With Databricks, developers and data scientists can work together effectively in shared workspaces. The platform supports multiple programming languages, including Python, SQL, and R, making it the ideal environment for developing and maintaining data pipelines. Furthermore, built-in Git integration facilitates version control, encourages rigorous documentation practices, and enables teams to collaborate and track development progress in a transparent manner. Solutions can be developed, tested, and deployed directly on the platform via Jupyter Notebooks, allowing development teams to move seamlessly from prototyping to production without having to switch between different tools.
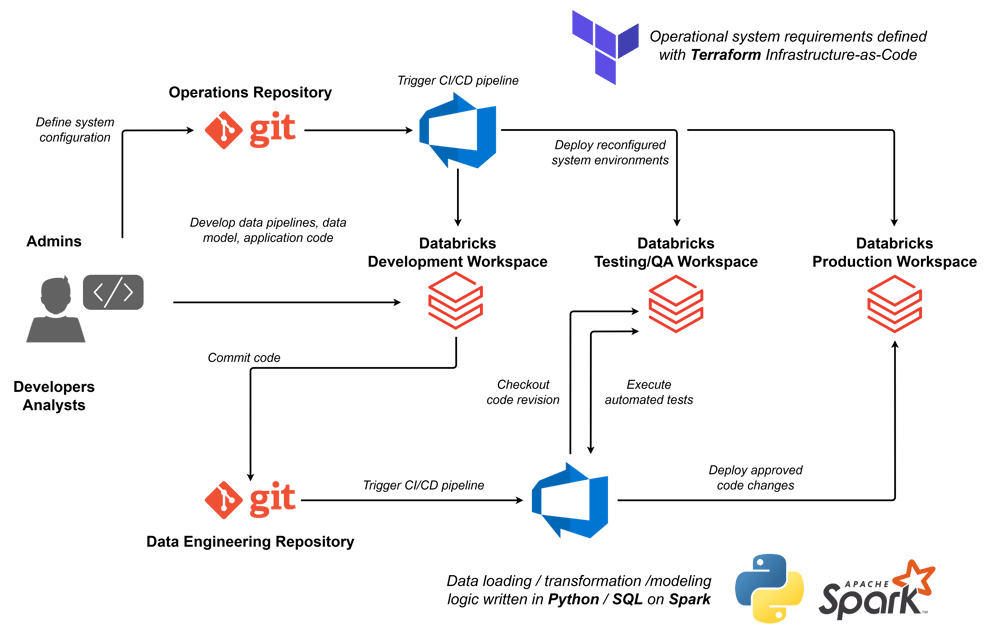
Databricks DevOps processes using Azure DevOps as an example: the Infrastructure-as-Code process is shown above the three Databricks system environments, which defines, checks, and deploys system components such as workspaces and authorization management, Spark clusters, Databricks jobs, etc. using Terraform. The development process for data processing in the Lakehouse is outlined in the lower half. SQL and Python Notebooks as well as central Python libraries are developed on the Databricks Dev-Workspace, versioned and synchronized with Git, automatically tested, and delivered via deployment pipeline.
/Logo%202023%20final%20dunkelgrau.png?width=221&height=97&name=Logo%202023%20final%20dunkelgrau.png)


































