/Logo%202023%20final%20dunkelgrau.png?width=221&height=97&name=Logo%202023%20final%20dunkelgrau.png)























Nowadays, rapid prototyping in the machine learning field is important in order to evaluate as many approaches as possible and to select and pursue the most promising ones. For data manipulation and also model building, the Python programming language is often used because it combines the latest algorithms and simple but powerful syntax. However, fitting the descriptive or predictive model requires large amounts of training data. This is a clear bottleneck: while the algorithms can be scaled vertically, data transfer to the application server is a typical factor for waiting times in prototyping. That's why people like to rely on SAP HANA for high-performance analytics. Data serving happens in real-time on the HANA side and additional features for in-database machine learning are provided.
In this article, we will show you which possibilities you have to realize your own data science applications using the open-source programming language Python in combination with SAP HANA.
Machine Learning on SAP HANA
To begin with, you will learn why SAP HANA is an excellent choice for the Data Science domain. SAP HANA (High-performance ANalytic Appliance) is a development and integration platform, which at its core consists of a relational, column-oriented in-memory database management system. In the main memory, the data is available in real-time, which means the best prerequisite for fast access time. This performance advantage is important for machine learning applications.
In addition to pure data storage, HANA brings many practical functions for data analysis. With the Application Function Library (AFL), some functions for advanced analytics are available. These can be called via SAP HANA SQLScript procedures to execute analytical algorithms directly in the database.
The HANA Predictive Analysis Library (PAL) and the HANA Automated Predictive Library (APL) are worth mentioning here. Topics such as clustering, regression, time series analysis, data preprocessing, general statistics and recommendation systems are covered. Here, in-database machine learning allows modelling to run directly on the database hardware without data transfer.
SAP HANA Python Client API
The described PAL and APL libraries can also be accessed from Python. For this purpose, the SAP HANA Python Client API is used, which controls the modelling by means of HANA DataFrames out of Python. The application of the analytical algorithms takes place entirely on HANA and generates result tables there. This represents the first opportunity to access data in a HANA instance using Python. However, the limited algorithm selection and stiff result tables limit the flexibility of the application. Therefore, a dedicated application server running Python is generally used.
Process HANA data in Python
The Python programming language offers several advantages for data science applications. State-of-the-art algorithms, extensive data manipulation and understandable syntax are decisive main arguments. Developers additionally benefit from the well-documented packages and the uncomplicated setup of a development environment. For data transfer from HANA, several packages are available.
How to bring SAP BW and state of the art Machine Learning together - Download the whitepaper here!

Hana Database Client (hdbcli)
For the technical implementation of the data transfer from SAP HANA to the Python application server, the Hana Database Client (hdbcli) driver is available as a simple method. Here, data can be retrieved via a cursor and SQL statements can be executed through the connection. If the data is to be processed further, it must first be converted into a suitable format (e.g. Pandas DataFrames or Numpy Array). Furthermore, the upload is also associated with effort, since it requires individual INSERT-INTO statements to be generated and executed.
from hdbcli import dbapi
conn = dbapi.connect(
address="<hostname>",
port="<port>",
user="<username>",
password="<password>"
)
sql = 'SELECT * FROM TABLE1'
cursor = conn.cursor()
cursor.execute(sql)
for row in cursor.fetchall():
print(row)
Sqlalchemy
With the addition of the sqlalchemy library, large amounts of data can be uploaded to a generated table faster and pulled data can be converted directly into a Pandas DataFrame. This saves effort, but still has some disadvantages:
- Manual parallelization on multiple threads has to be created by yourself - including merging the temporary upload tables on SAP HANA when uploading
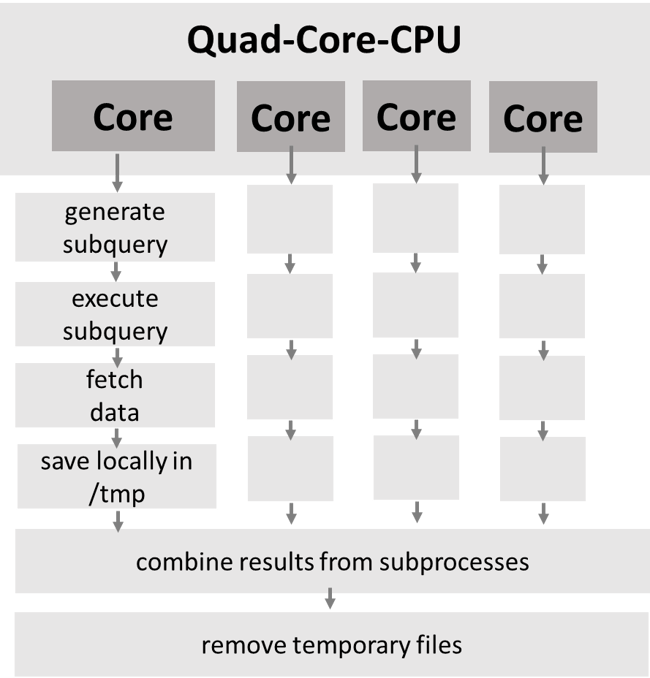
Parallelization of the data download
- The schema of the target table must be available to upload the data.
The last option for data access to HANA via Python was developed by us at NextLytics due to the special requirements in the Data Science area.
Python SAP HANA Connector by NextLytics
In order to optimize the interaction of SAP HANA with the Python programming language, we developed our own connector, which pays special attention to ease of use from the perspective of Python developers. The following points were of importance:
- Performance through parallelization
- Secure authentication
- Full compatibility with Panda's DataFrames
- Easy usability for a data science oriented Python developer.
The NextLytics HANA connector can be easily loaded as a package in Python and provides intuitive functions to communicate with a HANA instance. All information about the connector can be found on our website.
SAP HANA Connector - OurConclusion
To implement machine learning use cases with the combination of Python and SAP HANA you have many options. For simple use cases, the Application Functions Libraries APL and PAL for direct computations on HANA are the fastest option. These are also executable through the Python client.
Data analysis on an application server goes hand in hand with a costly data transfer. For this, you can rely on the Hana Database Client (hdbcli) as well as SqlAlchemy. For this, the NextLytics Python SAP HANA connector offers you a significant speed advantage through parallelization and allows developers to access the HANA database quickly and easily.
Do you have any questions or are you interested in the connector? NextLytics is always at your side as an experienced project partner. We help you to effectively solve your data problems from data integration to the use of machine learning models. Please do not hesitate to contact us.

