/Logo%202023%20final%20dunkelgrau.png?width=221&height=97&name=Logo%202023%20final%20dunkelgrau.png)























Garbage in, garbage out. This is a well-known guiding principle from IT that also applies to data analysis. Even an extensive analysis will not generate any added value if it is based on a faulty database with inconsistencies. When advanced analytics and forecasting are formed with machine learning (ML), this principle applies more than ever. A machine learning model makes decisions based on the known data. In model training, important relationships are extracted for this purpose. In addition to the data quality, the preparation of the influencing factors in the form of features is crucial for the model quality. The associated ML process for generating the influencing factors is called feature engineering.
In this blog article, we will show you the importance of feature engineering for successful machine learning models. You will also learn about the possibilities and limitations of automated feature engineering.
What is Feature Engineering?
In the process of feature engineering, concrete influencing factors (features) are formed for the later machine learning model based on the available database. These influencing factors represent an extension, simplification and transformation of the original data and are subsequently used in the machine learning project for training the model and forming predictions. The goal is to improve model performance through meaningful features.
The possibilities for generating new features depend on the dataset. Even though there are no limits to creativity, there are nevertheless some standard procedures:
- For numerical data, even filling in missing values is part of the feature engineering process. The reasonable exclusion of outliers, the capping of high and low data values, discretization (binning), transforming (logarithmizing, exponentiating, ...), scaling and standardizing are important techniques. The selection of useful steps is done according to the requirements of the chosen model.
- Categorical data is converted into numerical values. For this (simplified) one binary feature is formed per category using one-hot encoding. This is necessary, since most models function exclusively with numerical values. It is not uncommon for a combination of the categorical data with another data source to provide inspiration for numerical features. For example, city names can be transformed into their geo-coordinates using a public API. These can be used to retrieve further geo-information on the location and proximity to distribution centers, for example.
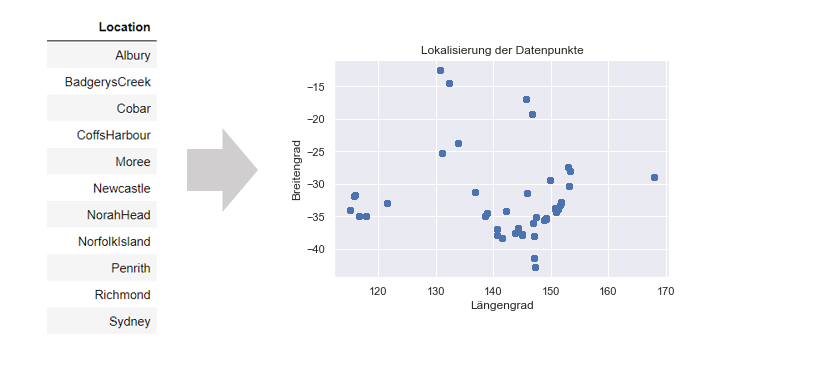
Conversion of city names as categorical data into their geo-coordinates
- Time data is often relativized to a reference point or existing time intervals are extracted. For example, in a payment forecast, the time interval between invoicing and payment can be calculated. Further information about calendar weeks, holidays and weekends can be useful influencing factors depending on the application purpose and can easily be extracted from a date value. In this process, the information contained in a date value is generalized and is more usable for the model: a calendar week will also occur in the future, a past date will not.
- Besides the mentioned transformation and extraction steps of the single factors, the combination of multiple influencing factors can be helpful. If the number of features should be kept low, a clustering or a principal component analysis can summarize several features. In the model itself, the individual cluster assignments are used instead of the features. More information about the procedure of clustering can be found in our article about customer segmentation.
In the most elaborate case, special features are created to represent a history in the form of informational indicators at the time of forecast. When predicting the payment date of an invoice, the behavior of the debtor in the last 3 months can be integrated in the form of features (average payment delay, percentage of open invoices,...). It is important for the training that the features are formed to the respective information status. In 2018, information from 2021 should not be included.
Now that the possibilities of feature engineering are known, you will find out in the next section which interactions between the features and the model are of importance.
Download the whitepaper and find out how to advance your business through Artificial Intelligence and Machine Learning

How does feature engineering influence the modeling result?
The goal of feature engineering is to improve model performance. For this purpose, the quality and, in particular, the relevance of the features are to be increased. A few relevant influencing factors lead to a better model result than many semi-relevant influencing factors. Quantity is therefore not a measure for the procedure.
The relevance can be evaluated via feature selection based on a specific model. Experienced data scientists use their knowledge of how the model works in advance to create an optimal representation of relevant influencing factors.
Example: The classic linear regression forms a simple linear model. If it is known in advance through the Data Exploration and Visualization that the influence of an influencing factor is logarithmic, however, a logarithmized version of the influencing factor can have a better fit in the linear model.
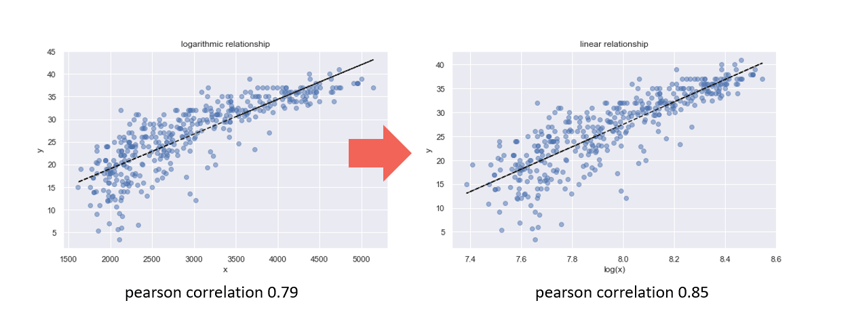
Logarithmization of the influence quantity to improve the linear relationship
After modeling, the importance of the influencing factors can be determined with the help of special feature importance libraries. If a feature has only a small influence, a model without this feature can outperform the full model under certain circumstances.
At any time it is important that the created influence factors can be generated from the new data in the running operation of the model. Otherwise, the model is not applicable and can only be used descriptively. A logarithmization is very clear and easy to reproduce. For standardization, on the other hand, the mean and variance of the original base feature of the training data must be stored. For this purpose, common frameworks offer special ML pipelines that store corresponding transformation values.
At the latest in productive environments, the greatest danger of feature engineering is uncovered. In many ML projects, data leakage leads to astonishing results during modeling, which, however, cannot be reproduced with new data. During data leakage, the created features reveal indirect information about the target value. For example, in a sales forecast, the "sales class" feature provides an indication of the rough range of the sales value. However, without the sales value, no sales class can be generated in productive operation. The sales value should be predicted by the model and is therefore not available. Therefore, an experienced Data Scientist checks the produced features with a critical eye.
In general, the features show a greater influence on the model performance than the optimization of the training process by hyperparameters. However, the optimization of hyperparameters can be automated very well. In the last step, we will therefore consider the question of the extent to which feature engineering can also be automated as a lever for project success.
Can Feature Engineering be Automated?
In the course of automated machine learning (AutoML), model-specific parameters are optimized during model training and the best model is selected from various model types. It is desirable that feature engineering is also executed as a process step without manual intervention. In some subareas, this is already possible:
- In the area of automated time series, no manual feature engineering is necessary. The internal optimization of the model parameters completely replaces the derivation and transformation of influencing factors. The determination of seasonalities and trends is realized via model training. Only the known time series is used as input.
- For linear models libraries like autofeat are available, which take over the feature engineering and the feature selection for regression and classification models. The formed influencing factors are limited here to the transformation (logarithmization, exponentiation,...) and combination of existing features. If desired a standardization of the features must take place in the advance. Altogether this automation is sufficient for simple use cases.
The limits of what can be automated arise from the use of domain knowledge. While transformations are easy to implement, mapping the known history in the form of indicators is an intellectually and code technically demanding implementation. The design is very dependent on the use case and is designed using domain knowledge. If, for example, customer-specific features are already available in a database, the selection of these features is again easy to automate. In this case, it can be worthwhile to keep general features in good quality throughout the company and to make them available centrally for machine learning projects.
In summary, feature engineering is a target-oriented method for improving model success. Influencing factors can be mapped in a model- and domain-oriented manner using partly simple and partly complex methods. The automated creation and selection of features saves additional manual effort for simple use cases.
Do you have further questions about the process of feature engineering in ML projects? Are you trying to build up the necessary know-how in your department or do you need support with a specific question?
We are happy to help you. Request a non-binding consulting offer today!

