/Logo%202023%20final%20dunkelgrau.png?width=221&height=97&name=Logo%202023%20final%20dunkelgrau.png)























Garbage in, Garbage out. So lautet ein bekannter Leitsatz aus der IT, der auch für die Datenanalyse gilt. Selbst eine umfangreiche Analyse wird keinen Mehrwert erzeugen, wenn sie auf einer fehlerhaften Datenbasis mit Inkonsistenzen beruht. Werden fortgeschrittene Analysen und Prognosen mit Machine Learning (ML) gebildet, gilt dieser Grundsatz mehr denn je. Ein Machine Learning Modell trifft die Entscheidung anhand der bekannten Daten. Im Modelltraining werden hierfür wichtige Zusammenhänge extrahiert. Neben der Datenqualität ist die Aufbereitung der Einflussfaktoren in Form von Features für die Modellqualität entscheidend. Der zugehörige ML-Prozess zur Erzeugung der Einflussfaktoren nennt sich Feature Engineering.
In diesem Blogartikel zeigen wir Ihnen die Bedeutung von Feature Engineering für erfolgreiche Machine Learning Modelle. Lernen Sie zudem Möglichkeiten und Grenzen der Automatisierung des Feature Engineerings kennen.
Was ist Feature Engineering?
Im Prozess des Feature Engineerings werden konkrete Einflussfaktoren (Features) für das spätere Machine Learning Modell anhand der verfügbaren Datenbasis gebildet. Diese Einflussfaktoren stellen eine Erweiterung, Vereinfachung und Anpassung der ursprünglichen Daten da und werden anschließend im Machine Learning Projekt für das Training des Modells und Erstellung der Prognose verwendet. Ziel ist es, durch aussagekräftige Features die Modellperformance zu verbessern.
Die Möglichkeiten zur Erzeugung neuer Features sind dabei abhängig von der Datenbasis. Auch wenn der Kreativität keine Grenzen gesetzt sind, gibt es dennoch einige Standardverfahren:
- Bei numerischen Daten gehört selbst das Auffüllen von fehlenden Werten zu dem Prozess des Feature Engineerings. Der sinnvolle Ausschluss von Ausreißern, das Abkappen von hohen und niedrigen Datenwerten, Diskretisierung (Binning), das Transformieren (Logarithmieren, Potenzieren, …), das Skalieren und das Standardisieren sind wichtige Techniken. Die Auswahl der sinnvollen Schritte erfolgt nach den Anforderungen des gewählten Modells.
- Kategoriale Daten werden in Zahlenwerte überführt. Hierfür wird, vereinfacht dargestellt, mittels One-Hot-Encoding pro Kategorie ein binäres Feature gebildet. Das ist notwendig, da die meisten Modelle ausschließlich mit numerischen Werten funktionieren. Nicht selten kann auch ein Verbund der kategorialen Daten mit einer weiteren Datenquelle Inspiration für numerische Features bieten. So können Städtenamen mithilfe einer öffentlichen API in ihre Geo-Koordinaten überführt werden. Anhand dieser sind weitere Geoinformationen zur Lage und Nähe zu beispielsweise Distributionszentren abrufbar.
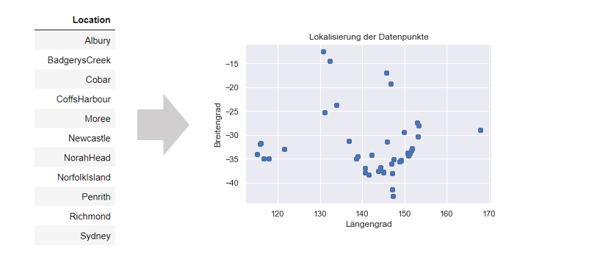
Umwandlung von Städtenamen als kategoriale Daten in ihre Geo-Koordinaten
- Zeitdaten werden oft auf einen Bezugspunkt relativiert oder vorhandene Abstände herausgearbeitet. Beispielsweise kann in einer Zahlungsprognose der zeitliche Abstand zwischen Rechnungsstellung und Begleichung des Betrages gebildet werden. Weitere Informationen über Kalenderwochen, Feiertage und Wochenenden können je nach Anwendungszweck sinnvolle Einflussfaktoren darstellen und leicht aus einem Datumswert extrahiert werden. In diesem Zug wird die Information, die in einem Datumswert steckt verallgemeinert und ist für das Modell besser nutzbar: Eine Kalenderwoche wird auch in Zukunft auftreten, ein vergangener Tag nicht.
- Neben den genannten Transformation- und Extraktionsschritten der Einzelwerte kann die Kombination von Einflussfaktoren hilfreich sein. Soll die Anzahl an Features gering gehalten werden, kann ein Clustering oder eine Hauptkomponentenanalyse mehrerer Features zusammenfassen. Im Modell selbst werden die einzelnen Clusterzuordnungen anstelle der Features herangezogen. Mehr Information über das Vorgehen bei einem Clustering erhalten Sie in unserem Artikel über Customer Segmentation.
- Im aufwendigsten Fall werden spezielle Features zur Abbildung einer Historie in Form von informationsaktuellen Indikatoren zum Prognosezeitpunkt erstellt. Bei der Vorhersage des Bezahltages einer Rechnung, kann das Verhalten des Debitors in den letzten 3 Monaten in Form von Features (durchschnittliche Verzögerung, prozentualer Anteil offener Rechnungen,...) verwendet werden. Wichtig für das Training ist, dass die Features zum jeweiligen Informationsstand gebildet werden. Im Jahr 2018 sollten keine Informationen aus 2021 einfließen.
Nachdem die Möglichkeiten des Feature Engineerings bekannt sind, erfahren Sie im nächsten Abschnitt, welche Wechselwirkungen zwischen den Features und dem Modell von Bedeutung sind.
So kurbeln Sie Ihr Business durch Künstliche Intelligenz und Machine Learning an

Wie beeinflusst das Feature Engineering das Modellierungs-ergebnis?
Das Ziel des Feature Engineering ist die Verbesserung der Modellperformance. Hierfür soll die Qualität und insbesondere die Relevanz der Features gesteigert werden. Wenige relevante Einflussfaktoren führen dabei zu einem besseren Modellergebnis, als viele halbwegs relevante Einflussfaktoren. Quantität ist somit kein Maß für das Vorgehen.
Die Relevanz kann über eine Feature Selection modellabhängig evaluiert werden. Erfahrene Data Scientisten nutzen hierfür schon im Vorfeld ihr Wissen über die Funktionsweise des Modells, um relevante Einflussfaktoren optimal abzubilden.
Beispiel: Der Klassiker Lineare Regression bildet ein einfaches lineares Modell. Ist aus der Data Exploration und Visualisierung im Vorfeld bekannt, dass der Einfluss eines Einflussfaktors jedoch logarithmisch ist, kann eine logarithmierte Version des Einflussfaktors im linearen Modell die volle Wirkung entfalten.
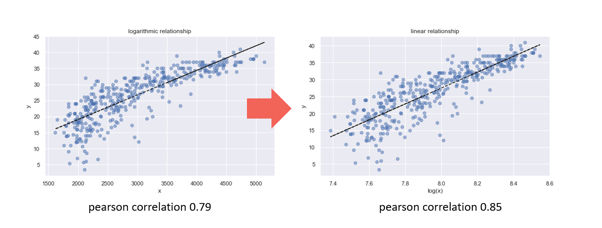
Logarithmierung der Einflussgröße zur Verbesserung des linearen Zusammenhangs
Nach der Modellierung kann die Wichtigkeit der Einflussfaktoren mithilfe von speziellen Bibliotheken ermittelt werden. Hat ein Feature nur einen geringen Einfluss, kann ein Modell ohne dieses Feature unter Umständen sogar besser abschneiden.
Zu jeder Zeit ist es wichtig, dass die erstellten Einflussfaktoren im produktiven Betrieb des Modelles aus den neuen Daten heraus erzeugbar sind. Das Modell ist ansonsten nicht anwendbar und kann nur deskriptiv genutzt werden. Eine Logarithmierung ist hier sehr eindeutig und einfach nachzubilden. Für eine Standardisierung hingegen muss der Mittelwert und die Varianz des ursprünglichen Basisfeatures der Trainingsdaten gespeichert werden. Hierfür bieten gängige Frameworks spezielle ML-Pipelines an, welche entsprechende Transformationswerte speichern.
Spätestens im produktiven Betrieb wird die größte Gefahr des Feature Engineerings aufgedeckt. Data Leakage führt in vielen ML-Projekten zu erstaunlichen Ergebnissen während der Modellierung, welche jedoch nicht im produktiven Betrieb reproduzierbar sind. Durch die erstellten Features werden bei einem Data Leakage indirekte Informationen über den Zielwert bekannt gegeben. Beispielsweise liefert bei einer Umsatzprognose das Feature “Umsatzklasse” einen Hinweis auf den groben Bereich des Umsatzwertes. Jedoch ist ohne den Umsatzwert im produktiven Betrieb keine Umsatzklasse erzeugbar. Dieser soll durch das Modell prognostiziert werden und ist demnach nicht verfügbar. Ein erfahrener Data Scientist überprüft deshalb die gewonnen Einflussfaktoren mit kritischem Blick bereits vor der Produktivsetzung der Machine Learning Anwendung.
Im Allgemeinen weisen die Features einen größeren Einfluss auf die Modellperformance auf, als die Optimierung des Trainingsvorgangs durch Hyperparameter. Die Optimierung der Hyperparameter ist jedoch sehr gut automatisierbar. Im letzten Schritt soll deshalb die Frage betrachtet werden, inwiefern auch das Feature Engineering als Hebel für den Projekterfolg automatisiert werden kann.
Ist Feature Engineering automatisierbar?
Im Zuge des automatisierten Machine Learning (AutoML) werden während des Modelltrainings modellspezifische Parameter optimiert und das beste Modell aus verschiedenen Modelltypen ausgewählt. Wünschenswert ist es, das auch das Feature Engineering als Prozessschritt ohne manuelles Zutun ausgeführt wird. In manchen Teilbereichen ist dies schon möglich:
- Im Bereich der automatisierte Zeitreihen ist kein manuelles Feature Engineering notwendig. Die interne Optimierung der Modellparameter ersetzt das Ableiten und Transformieren von Einflussfaktoren völlig. Die Ermittlung von Saisonalitäten und Trends wird über das Modelltraining realisiert. Als Eingabe wird lediglich die bekannte Zeitreihe verwendet.
- Für lineare Modelle stehen Bibliotheken wie autofeat bereit, welche das Feature Engineering und die Feature Selektion für Regressions- und Klassifikationsmodelle übernehmen. Die gebildeten Einflussfaktoren beschränkt sich hierbei auf die Transformation (Logarithmierung, Potenzierung,...) und Kombination von bestehenden Features. Falls gewünscht muss eine Standardisierung der Features im Vorfeld erfolgen. Insgesamt reicht diese Automatisierung für einfache Anwendungsfälle aus.
Die Grenzen des Automatisierbaren liegen in der Nutzung des Domänenwissens. Während Transformationen leicht zu realisieren sind, ist das Abbilden der bekannten Historie in Form von Indikatoren ein intellektuell und codetechnische anspruchsvolle Umsetzung. Die Gestaltung ist sehr abhängig von dem Anwendungsfall und wird mithilfe von Domänenwissen entworfen. Liegen zum Beispiel kundenspezifischen Features bereits in einer Datenbank vor, ist die Auswahl dieser Features wiederum leicht automatisierbar. Hier kann es sich lohnen allgemeine Features in guter Qualität unternehmensweit vorzuhalten und für Machine Learning Vorhaben zentral zur Verfügung zu stellen.
Zusammenfassend ist Feature Engineering eine zielführende Methode, um den Modellerfolg zu verbessern. Mit teils einfachen und teils komplexen Methoden können Einflussfaktoren modell- und domänengerecht abgebildet werden. Die automatisierte Erstellung und Auswahl von Features spart für einfache Anwendungsfälle zusätzlich manuellen Aufwand ein.
Haben Sie weitere Fragen zu dem Prozess des Feature Engineerings im ML-Projekt? Versuchen Sie das nötige Know-How in Ihrer Abteilung aufzubauen oder benötigen Sie Unterstützung bei einer konkreten Fragestellung?
Wir helfen Ihnen gerne dabei. Fordern Sie noch heute ein unverbindliches Beratungsangebot an!


