/Logo%202023%20final%20dunkelgrau.png?width=221&height=97&name=Logo%202023%20final%20dunkelgrau.png)























It is well established by now that Airflow is the state-of-the-art tool for scheduling and monitoring workflows in a unified framework. Airflow enables us to define complex dependencies among various tasks inside DAGs (directed acyclic graphs), although up until recently the execution of DAGs was only possible in a time-based manner (much like cron). Data-aware scheduling has been newly introduced to Airflow with version 2.4 and enables developers to define a producer-consumer relation between DAGs. A DAG can now be triggered by a task that operates on a dataset whenever that dataset is updated, independently of a predefined time schedule. Imagine for example, you have a task that imports currency exchange rates into a database table, and another DAG which performs a transformation should be triggered immediately. We will go through this scenario in greater detail and provide some actual code examples.
Benefits of data-aware scheduling
Scheduling a workflow in a time-based manner works well if you know beforehand when each process should run. This can cause problems if there is a need to define dependency between DAGs. Consider the following scenario: Data engineering team A runs a preprocessing pipeline that creates/updates a dataset periodically (it could be a plain text file, a database entry, or any kind of resource). Data analysis team B runs a pipeline that reads the dataset and performs some analysis and calculations. Team B would like to be notified as soon as possible for the availability of the new dataset in order to minimize the downtime between two pipeline runs. This can be achieved through the use of a data-aware scheduling mechanism where the consumer is notified when a change is published by the producer and its pipeline execution starts immediately. This results in faster and more robust cross-pipeline communication. Stakeholders that need just-in-time data in their reports and dashboards will always get the latest data as soon as possible.
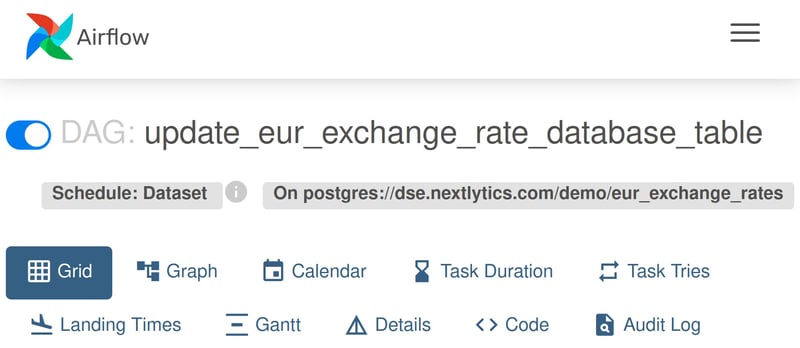
“update_eur_exchange_rate_database_table” DAG is scheduled based on a dataset update.
What is an Airflow dataset
An Airflow dataset is a stand-in for a logical grouping of data. Datasets may be updated by upstream “producer” tasks, and dataset updates contribute to scheduling downstream “consumer” DAGs. This means that a DAG will be executed if and only if a dataset that is dependent upon that, receives an update. Airflow makes no assumptions about the content or location of the dataset, which means that it can represent a simple text file saved locally, a database table, an Azure storage blob, etc. The dataset is identified by a URI (Uniform Resource Identifier).Two Dataset objects that share the same URI, will be considered to refer to the same resource. If a DAG depends upon multiple datasets, the execution starts when every dataset has received at least one update. Note that the dataset is considered to be updated if the task that is responsible for the update, finishes successfully. There is no way for Airflow to know if the dataset is actually updated, so the developer is responsible for making sure that the update is complete. In other words, no polling is taking place to ensure that the resource received an update.
Practical examples
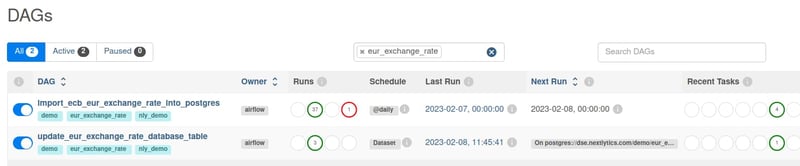
“update_eur_exchange_rate_database_table” DAG’s next run is determined by the updates on a specific resource.
To showcase the usage of the new Datasets feature, a simple example is presented. The “import_ecb_eur_exchange_rate_into_postgres” DAG is responsible for fetching the latest exchange rates for Euro and inserting them into a Postgres database and “update_eur_exchange_rate_database_table” DAG is scheduled to run when an update is available.
First, the “import_ecb_eur_exchange_rate_into_postgres” or producer DAG is defined:
import io
import pandas as pd
import pendulum
import requests
import sqlalchemy
from airflow import Dataset
from airflow.decorators import task, dag
from airflow.hooks.base import BaseHook
db_conn = BaseHook.get_connection("pg_default")
engine = sqlalchemy.create_engine(
f"postgresql+psycopg2://{db_conn.login}:{db_conn.password}@{db_conn.host}:{db_conn.port}/{db_conn.schema}")
@dag(
schedule_interval="@daily",
start_date=pendulum.datetime(2023, 1, 1, tz="UTC"),
catchup=True,
)
def import_ecb_eur_exchange_rate_into_postgres():
@task
def get_ecb_exchange_rate_data(**kwargs) -> str:
base_url = "https://sdw-wsrest.ecb.europa.eu/service/data"
flow_ref = "EXR"
key = "D..EUR.SP00.A"
logical_date = kwargs["ds"]
parameters = {
"startPeriod": logical_date,
"endPeriod": logical_date,
"format": "csvdata",
}
request_url = f"{base_url}/{flow_ref}/{key}"
response = requests.get(request_url, params=parameters)
return pd.read_csv(io.StringIO(response.text)).to_json()
@task(outlets=[Dataset("postgres://dse.nextlytics.com/demo/eur_exchange_rates")])
def import_exchange_rate_data_into_postgres(json_data: str, table: str):
loadtime = pendulum.now().isoformat()
df_source = pd.read_json(json_data)
df_db = pd.DataFrame().assign(
exchange_rate_date=df_source["TIME_PERIOD"],
currency=df_source["CURRENCY"],
currency_name=df_source["TITLE"].str.replace("/Euro", ""),
rate=df_source["OBS_VALUE"],
_loadtime=loadtime)
with engine.connect() as con:
df_db.to_sql(name=table, con=con, if_exists="append", index=False)
json_data = get_ecb_exchange_rate_data()
import_exchange_rate_data_into_postgres(json_data, table='eur_exchange_rates')
dag = import_ecb_eur_exchange_rate_into_postgres()
The “import_exchange_rate_data_into_postgres” task defines a list of Dataset objects as “outlets”, i.e. datasets produced or updated by this task. In this case, the task inserts some new records in a database table.
Effective workflow management with Apache Airflow 2.0

The “update_eur_exchange_rate_database_table” or consumer DAG has the following definition and its job is to insert only the latest exchange rate data into a separate table as soon as a new batch of data is available:
import pendulum
import sqlalchemy
from airflow import Dataset
from airflow.decorators import task, dag
from airflow.hooks.base import BaseHook
db_conn = BaseHook.get_connection("pg_default")
engine = sqlalchemy.create_engine(
f"postgresql+psycopg2://{db_conn.login}:{db_conn.password}@{db_conn.host}:{db_conn.port}/{db_conn.schema}")
@dag(
schedule=[Dataset("postgres://dse.nextlytics.com/demo/eur_exchange_rates")],
start_date=pendulum.datetime(2023, 1, 1, tz="UTC"),
catchup=False,
)
def update_eur_exchange_rate_database_table():
@task
def update_table(**kwargs):
with engine.begin() as con:
backup_table = "ALTER TABLE IF EXISTS report_current_eur_exchange_rates RENAME TO report_current_eur_exchange_rates_bak"
con.execute(backup_table)
update_table = """
select
distinct eer.currency,
eer.currency_name,
(select rate from eur_exchange_rates eer2 where eer2.currency=eer.currency
order by eer2.exchange_rate_date desc limit 1),
now() as update_timestamp
into report_current_eur_exchange_rates
from eur_exchange_rates eer order by currency asc;"""
con.execute(update_table)
remove_backup = "drop table if exists report_current_eur_exchange_rates_bak"
con.execute(remove_backup)
update_table()
dag = update_eur_exchange_rate_database_table()
The “consumer” DAG is scheduled based on a Dataset, which in this case shares the URI defined by our exemplary producer. Notice that the “Dataset” objects used for defining the dependencies are different, but they refer to the same resource. The DAG is triggered the moment the “import_exchange_rate_data_into_postgres” task from the producer succeeds, resulting in zero downtime between the two DAG executions.
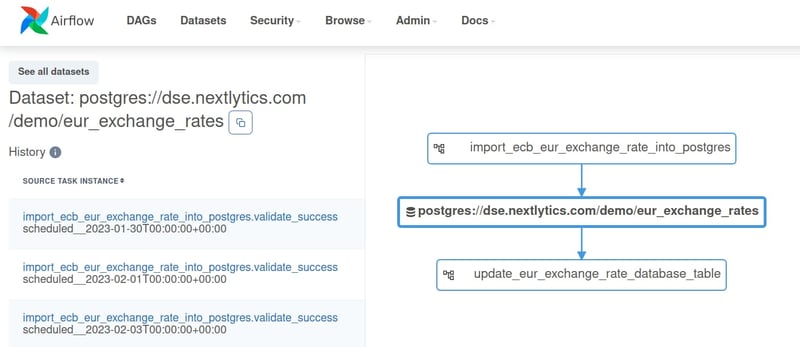
Visual representation of the lineage between the DAGS. Notice the dataset resource in the middle.
This new feature allows for more flexibility when scheduling DAGs that are interrelated, but there are some pitfalls to avoid. It is possible to create a task that is supposed to update a resource, but there is no interaction with the resource at all. Airflow allows that because it's at the developer's discretion to decide what constitutes an update. Airflow deems a dataset updated if the task that is assigned to update it, is executed successfully regardless of the implementation of the task. The Airflow Dataset API preserves the design choice to separate workflow process logic from the processed data and at the same time enables tighter coupling with less custom code.
Years of discussion and development have finally resulted in the new Airflow Dataset concept described above. The current implementation is a very high-level wrapper around actual data artifacts that provides little functionality beyond cross-DAG-scheduling. Notably, there is no REST API endpoint to mark a dataset as externally updated yet, which would open up interesting cross-system integration scenarios. The possibility of just-in-time scheduling of DAGs is still a highly valuable addition to the ever-increasing Apache Airflow toolset and provides data engineers yet another possibility to meet business requirements.
Do you have further questions about Apache Airflow? You are welcome to schedule an initial discussion with our NextLytics Data Science and Engineering team. We’re curious to learn more about your use cases and support you in finding solutions that fit your specific needs and system context.

