/Logo%202023%20final%20dunkelgrau.png?width=221&height=97&name=Logo%202023%20final%20dunkelgrau.png)























When your company is growing, so is the amount of data you accumulate. To analyze the ever increasing amount of data and to produce valuable insights from it comes with major challenges for any data team: keeping processing times and load to a minimum, and making sure that your data processing pipelines are running both as scheduled and without errors. Using “delta loading” as a design principle for data pipelines can help to ensure freshness, validity, and efficiency as long as source systems and processing frameworks support this approach.
In this example we want to investigate how to process a delta subset of SAP BW data provided via an OData service using the open source orchestration service Apache Airflow. While this example is focused on SAP BW, this process should work in a very similar way for OData interfaces exposed by other SAP systems as well.
Apache Airflow is an open source orchestration service that is often used to create, schedule and monitor data processing pipelines. With it you can create those pipelines called DAGs (Directional Acyclic Graphs) using the Python programming language.
A few words about OData
OData refers to the Open Data Protocol, a standardized protocol to provide and consume relational data as a RESTful API that was initially developed by Microsoft in 2007. Nowadays its version 4.0 is standardized at OASIS and approved as an international standard.
SAP BW can leverage the OData protocol to expose InfoProviders such as InfoCubes, DataStore Objects, or InfoObjects as an OData service to clients outside of SAP. These OData services can be configured in a variety of ways, including but not limited to allowing the extraction of a delta of the connected data source, allowing the user to collect the changes in the data since the last extraction. This is a big help when working with data providers containing a large amount of data, since it helps to keep execution times of data processing pipelines as low as possible.
Using the OData protocol to extract SAP BW data
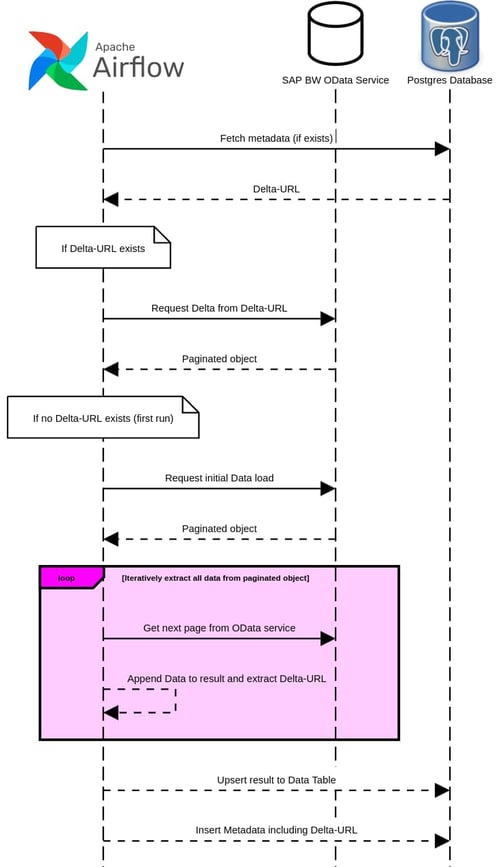
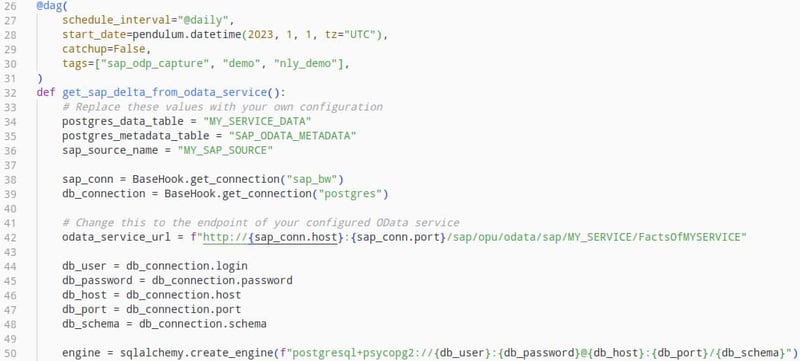
In this article we will design an Airflow DAG to extract the contents of a SAP BW DataStore via the aforementioned OData provider. This DAG will extract the whole content of the DataStore on the first execution, duplicating all the existing data and then only loading the delta with each subsequent run. For this example the extracted data is going to be saved in a separate Postgres database, with an additional table saving metadata about the data load as well as the API endpoint to extract the delta for the next process execution.
We will use the TaskFlow API exposed by Airflow to define and structure the DAG, and the Python libraries “Pandas” for data object handling, “SQLAlchemy” to connect to the Postgres database and “requests” to communicate with the OData service.
The whole DAG itself is structured as follows:
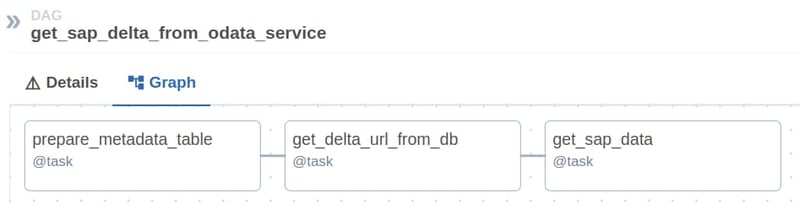
When initializing the DAG, the credentials for connecting with both the OData service and the Postgres instance will be loaded from the previously configured Airflow connection objects.
In the first task, the structure for the metadata table documenting the pipeline executions and saving key metrics will be created.
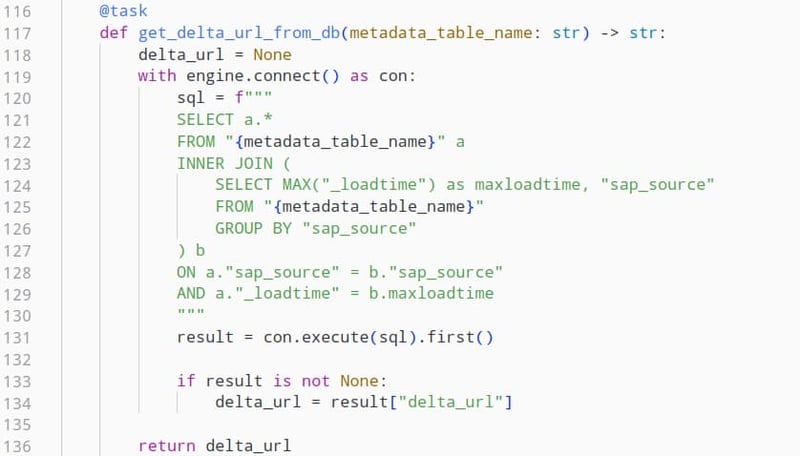
In the second task we will query this metadata table using SQL and extract the field “delta_url” from the most recent execution of the pipeline for this OData source. This in turn allows us to get the corresponding delta from our OData service. If this pipeline is executed for the first time, this value will be nonexistent, informing the further process step that we need to execute an initial data load.
At this point we are ready to get to the actual data extraction.
Effective workflow management with
Apache Airflow 2.0

Interacting with the SAP BW OData API
The OData API of a SAP data provider is implemented as a RESTful API, providing the payload of HTTP responses in the JSON format. This allows us to easily parse the data and extract the relevant fields for our use case.
To keep the size of the responses manageable, this API will provide data in a paginated format. This means that if a large amount of data is being requested, the first response will only contain a subset of this data as well as a field containing another API endpoint called “__next”, containing the next subset of data. This stands true for querying said endpoint again as well, up until the point where all data has been transmitted. In this case the response will contain a field called “__delta”, containing the API endpoint to query the delta for the next pipeline execution.
This mechanism is important to understand how the next step of the data pipeline works, since only by iteratively querying the OData API can we make sure that all queried data will be extracted without compromising system performance or risking data loss due to HTTP request timeouts.
The following task will execute the data extraction, varying slightly depending on whether this is the first time the data provider is extracted or just a delta of the data is being processed. In both cases this operation will yield both a Pandas dataframe containing the data as well as the API endpoint to query the delta on the next pipeline execution.
The interaction with the OData service itself works as follows:
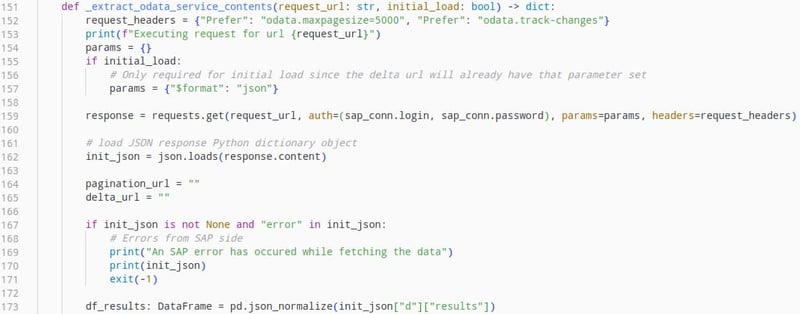
This will load the response of the initial request as a dataframe and we can proceed with parsing the data.
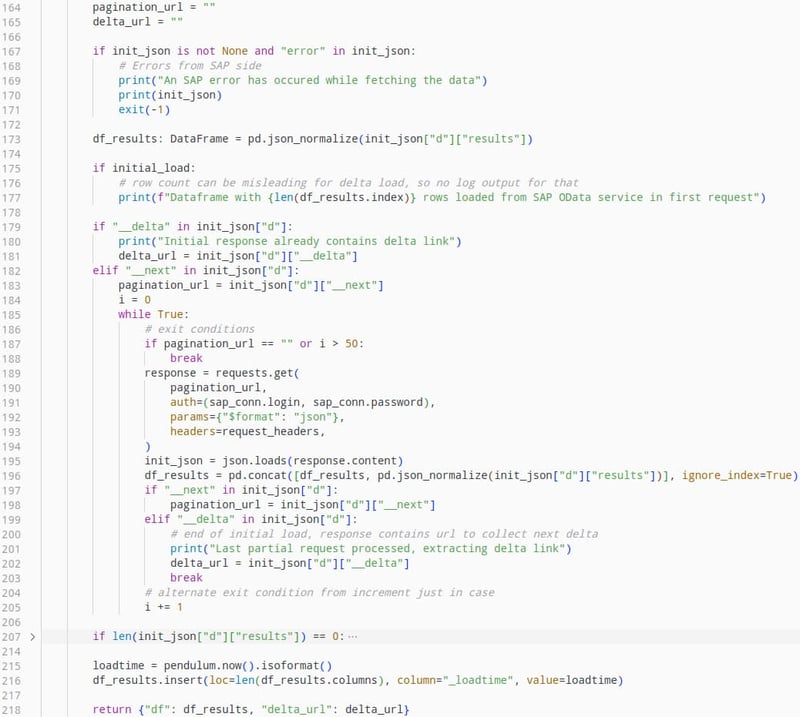
This piece of code will iteratively extract the paginated data and append it to a resulting dataframe, as well as adding a separate metadata column to document the load time of the data.
This data can then be written to our target data table. In case of an initial data load, all of the data just needs to be inserted. If a delta load is executed on the other hand, there needs to be an
upsert* mechanism that handles the database write for newly inserted data, as well as the updated or deleted rows since the last pipeline execution.
(*The term "upsert" is a portmanteau of the words "update" and "insert")
To correctly identify to which category the data belongs, we can leverage the field “ODQ_CHANGEMODE” , which is part of the delta load response we received from the OData service. These values can be “D” for deleted rows, “C” for newly created rows and “U” for updated existing rows.
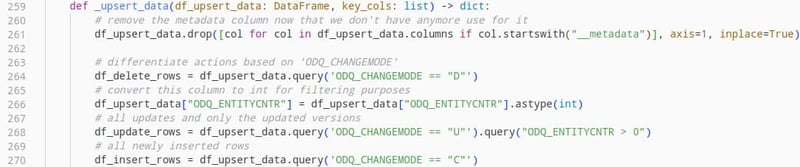
All that’s left is to write the separated dataframe objects to the target database based upon the operation that is to be executed on each of them.
Documenting data operations with relevant metadata
Now that our data has been written, the last step will be to create an entry in the metadata table we created in the beginning of the DAG. For this purpose we have collected the amount of rows that have been inserted, updated and deleted as well as the API endpoint for the next delta load.
Apache Airflow for SAP change data capture -
Our Conclusion
In this example we have examined the power of the OData standard as well as the possibilities of how you can use Apache Airflow to structure your data processing pipelines. This process is not exclusive to SAP BW OData services and should work in a very similar way for other SAP products like SAP S/4HANA as well.
The data that has been collected with this pipeline can now be used to generate further business insights. We could for example use sales data for a certain product to generate a visually appealing dashboard with Apache Superset.
You can find the whole code for this DAG here. If you have questions about this implementation or if you’re wondering how you can use Apache Airflow to empower your data driven business we are happy to help you. Contact the Data Science and Engineering team at Nextlytics today.

