/Logo%202023%20final%20dunkelgrau.png?width=221&height=97&name=Logo%202023%20final%20dunkelgrau.png)























Data integration and analysis are the cornerstones of modern, fact-based decision-making and corporate management. To ensure that the most up-to-date and correct data is always available, a reliable data integration platform is required. An orchestration service enables and structures workflow management and scheduling for all automated data processing procedures and thus becomes the central clock generator of that data integration platform. Definition and execution logic for workflows are harmonised and reliably controlled and executed based on various timing or content preconditions. When a data integration platform is to be newly introduced or incrementally migrated to the cloud, the question often arises as to which system can be the right choice as an orchestration service.
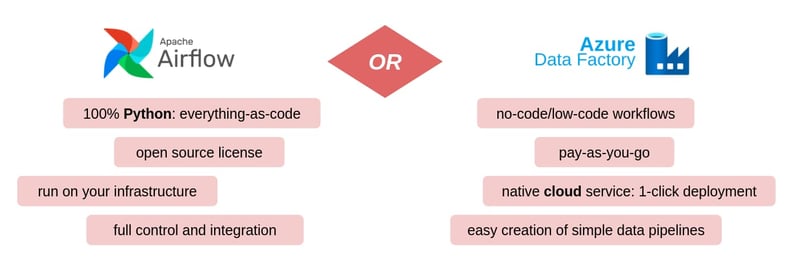
In our view, Apache Airflow is the flagship of open source orchestration services. But how does Airflow compare with its rival product from the Microsoft Cloud, Azure Data Factory? We want to take a look at exactly this question.
The Candidates
Apache Airflow
Apache Airflow relies entirely on the Python programming language to define and control workflows and associated tasks. Workflows are defined as Python source code so that the entire system can be developed and operated using version control and DevOps platforms such as Azure DevOps, GitHub or GitLab based on established software engineering best practices.
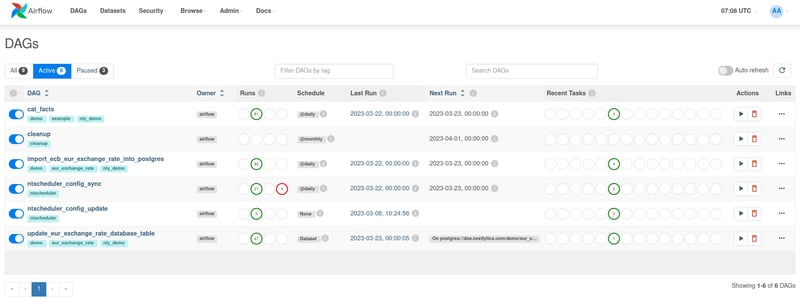
Apache Airflow can be operated by means of container virtualisation either in your own data centre or in the cloud. Direct installation on Linux servers is possible, but operation via Docker or Kubernetes Cluster is easier to maintain and automate. Airflow can communicate with practically all common compute, storage and database systems via freely available plug-ins and connect them with each other in workflows. Since all workflows and tasks are defined in Python code, there is no limit to the existing interfaces. The Airflow user interface allows easy monitoring of all workflows, schedules and past processes as well as encrypted storage of connection data and runtime variables.
Airflow can be operated and scaled in different ways due to the underlying micro-services architecture. In the comparison "on-premise" vs "cloud" operation, the usual advantages and disadvantages of the respective modes of operation apply with regard to technical preconditions, scalability, connectivity and personnel deployment. A fully-fledged, cloud-based software-as-a-service offering for Airflow is available from various providers, but in Azure only in a limited form. Strong programming skills and an established software engineering process are prerequisites for using Airflow efficiently in practice over the long term. Once this foundation has been laid, the possibilities for expansion are practically unlimited. Nevertheless, caution is advised: If, for example, the quality of further development is put on the back burner in favour of short-term goal achievement, freely expandable infrastructures can also grow beyond their healthy level of complexity.
Azure Data Factory
Data Factory is the cloud-based data transformation and orchestration service from the Microsoft Azure portfolio. Azure Data Factory (ADF) can communicate with a variety of data sources and a smaller selection of data sinks via various connectors. In particular, data writing is relatively limited to Azure services such as Managed SQL Server, Azure Synapse and Azure Blob Storage. Data processing is performed in Apache Spark clusters, which are dynamically managed in the background. Data pipelines are primarily edited in a graphical user interface and can be scheduled for execution in calendar-based or event-driven manner. All configuration changes can be synchronised with an Azure DevOps Git repository and credentials can be stored encrypted in an Azure Key Vault and made accessible to different user groups.
The strong integration with Microsoft technologies as well as the graphical user interface for pipeline development according to low-code or no-code principles are advantages and disadvantages of Azure Data Factory, depending on your point of view. Especially the restriction to Azure storage services and databases as recipients of data from ADF pipelines limits the scope for the strategic development of one's own infrastructure. The development of ADF pipelines via user interface requires extensive familiarisation with the functionality and vocabulary.
Shared Features
Orchestration services and especially Azure Data Factory and Apache Airflow have features in common that cover the basic range of functions:
- Workflow control: Sequential and parallel processes as well as conditional branching of process flows can be defined
- Chronological scheduling: workflows can be triggered regularly on the basis of a temporal specification
- Event scheduling: Workflows can be triggered based on a precondition that has occurred.
- User/Permission Management: The system allows you to work with personalised user accounts with different access rights.
- Credential Store: The credentials for accessing data sources and sinks can be stored encrypted in the system and loaded via references at runtime
- Monitoring: the status and history of processes can be viewed and monitored
- Logging: Log information on processes and process steps is recorded and can be viewed.
- Alerting: When certain circumstances occur, notifications can be sent to selected persons, e.g. by e-mail when a process is successfully completed or in the event of an error

The Differences
Apache Airflow and Azure Data Factory differ from each other, sometimes significantly, in detail. In order to make the differences tangible, in the following we look at the respective preconditions for the use of the systems, their core functions, the possibilities for integration into existing system contexts and sustainability aspects.
Effective workflow management with Apache Airflow 2.0

Preconditions: What technical conditions must be met?
Apache Airflow can be operated on any hardware or infrastructure. Between a pure on-premises installation in your own data centre and a completely outsourced software-as-a-service product in the cloud, all possibilities are conceivable.
Azure Data Factory, on the other hand, is a pure cloud service. If databases and services in one's own data centre are to be integrated with ADF, connectivity between the cloud and on-premises components must be ensured at the network level. Since the executing component (Microsoft Integration Runtime) works according to the pull principle and does not have to be controlled from outside, this may be a unidirectional connection from the own network to the data factory. For many functions of ADF, however, data is transferred to the cloud and processed on Spark Clusters in the Azure Cloud. A corresponding data protection consideration of the processes may be necessary.
If there is a need to mediate between the services of different cloud providers, there are the corresponding connectors for both systems. In this respect, we see Airflow as having the advantage, since the portfolio of freely available extensions to the project is constantly expanding, is fundamentally independent and no strategic restrictions on the intended uses are built into the components.
Core functions: In what respects do the services differ in their range of functions or in the way they are used?
The functional scope of Azure Data Factory is clearly to be located as a data integration platform and thus covers the requirements for a dedicated orchestration service rather incidentally. The functionality of Data Factory to configure data integration paths directly via the graphical user interface can be seen as a clear plus in terms of possibilities. In particular, simple data transfers without complex transformations are quickly put together and do not require any programming knowledge.
All configuration stored in Data Factory can be synchronised into an Azure DevOps Git repository, where it is stored in the form of JSON files. In this way, the development of data integration routes with Data Factory is based on the principles of software development in a distributed development team, but remains far behind the possibilities of a full Git integration.
This, in turn, is fully exploited by Airflow with the "configuration as code" principle: all configuration and workflow definitions in Airflow are Python source code and as such can be seamlessly managed via version control and developed in a distributed team.
Integration in system context: How can the systems be integrated into existing infrastructure?
Apache Airflow offers the user a relatively free framework for defining workflows. Developers have every opportunity to link to the existing system context and drive integration incrementally. How to interact with third-party systems is not strictly specified, but can be easily harmonised via a variety of freely available connectors. Thus, data can either be completely loaded into the runtime environment of a task and processed in Python or processing instructions can be sent to a database. The decision is up to the development team and can be linked to the respective conditions or quality requirements of a use case.
The integration possibilities of an Azure Data Factory are more limited. There are a large number of native connectors for third-party systems, but experience shows that the probability of having at least one unsupported system in use centrally in one's own system context is high. Finally, ADF also allows the development of own extensions, e.g. using Python, so that with a certain amount of effort all integration possibilities are certainly given. However, if ADF is greatly extended in this way, the supposed advantage of easier accessibility for users without programming knowledge is given up.
Sustainability: What lines of development do the systems offer in terms of increasing requirements (performance, scalability) and operating time?
Azure Data Factory, as a pure SaaS cloud application, is a proprietary product of Microsoft. This status implies a certain longevity, but does not guarantee endless support for the product. The complete configuration can be saved in Git repositories, but is specific to Data Factory and would have to be fully translated for a later migration. Depending on the depth of integration of the own workflows into the Data Factory logic, such a migration can be more or less costly: If Data Factory is only used as a framework for the development of workflows based on Python source code, for example, the process logics could be easily reused and transferred to other frameworks. If the native Data Factory pipeline components are used and configured, there is no such possibility.
A big plus of a data factory is the seamless scalability for users due to the underlying cloud computing technologies. Airflow can also be scaled vertically and horizontally thanks to its micro-services architecture, but may require targeted control depending on the operating mode. If the system is set up on a Kubernetes cluster, it even works fully automatically.
If Apache Airflow is operated in the own data centre, a later migration to the cloud is possible and requires the transfer of the system configuration to the new environment. Since all configuration is kept as source code in a version control system, such a change of environment can be carried out with limited effort. There is no automatism for a cloud migration. Effort drivers would be, in particular, the testing of all connected resources (storage, databases) in the new environment.
As open source software, Airflow offers the advantage that permanent operation is possible independent of the product life cycle of a provider. Under the auspices of the Apache Software Foundation, Airflow benefits from a professional organisational framework and long-term project strategy with a broad-based developer community (almost 30,000 "stars" on Github, over 11,000 forks of the core project).
And the operating costs?
We have deliberately excluded a consideration of operating costs from our brief comparison. Azure Data Factory is sold purely on a pay-as-you-go basis and entices with low entry prices. In practice, however, you need a number of other services from the Azure portfolio to exploit the full range of possibilities of ADF. The cost model can therefore be very different for each individual. Compared to the costs for the database systems to be operated in Azure, to which one is bound without alternative, the ADF operating costs are negligible.
As open source software, Apache Airflow comes without licensing costs, but with corresponding operating costs, depending on the chosen form of operation. For both systems, the cost driver is the complexity of the material and the operationalisation for the individual use case. A data integration platform cannot be operated without highly qualified personnel or appropriate external support.
Apache Airflow or Azure Data Factory - Our Conclusion
Azure Data Factory brings with it a wide range of functions that go beyond the basic requirements of an orchestration service. However, the profound linking of the Data Factory workflow model with the data to be processed again limits the possibilities of integration with existing services in one's own data centre.
Apache Airflow is a dedicated orchestration service in its native functionalities and separates workflows from data flows in its architecture. Due to the full compliance with the configuration-as-code principle, the use of the widespread programming language Python as a basis and the open source licence, a complete integration into any system context is possible.
Even this superficial discussion of the two services shows that the decision between Azure Data Factory and Apache Airflow as an orchestration service depends heavily on the circumstances of a company and the existing system context. We support our customers in working with both systems and see many of the practical pros and cons in everyday work. We would gladly support you on your own journey to decide on the right orchestration service for your needs and put it into practice. You are welcome to schedule an initial discussion with our NextLytics Data Science and Engineering team.

