/Logo%202023%20final%20dunkelgrau.png?width=221&height=97&name=Logo%202023%20final%20dunkelgrau.png)























The potential of machine learning and advanced analytics is not limited to the structured data that can be easily extracted from a database or data warehouse. An even larger amount of data is hidden in documents, emails, comments and of course the internet.
This unstructured data contains information that is not directly accessible. Under the keywords text mining and natural language processing (NLP), methods can be found that make it possible to extract a variety of insights from text data. In this article, you will learn about basic methods and associated frameworks using a practical example from the field of marketing and thus open up a further data field for your analysis.
Text mining can often be used profitably, for example, with complaint comments and maintenance notes. For example, the text data is used to derive prognosis factors for a machine learning project. In addition to the quantitative rating of the customer based on the order history (see RFM analysis), qualitative ratings are also possible with text mining.
We present below the use case of success prediction for blog articles.
For this purpose, the following steps are followed:
- Determining the concrete analysis objective
- Generating the database
- Forming features from the text content and title
- Creating a prediction model
- Interpreting the results
Determination of the analysis objective
Before analysing text data, a suitable analysis objective should be formed in order to provide added value. From a marketing point of view, the success of a blog article is crucial and this can first be measured with various KPIs. For example, the number of views, the length of time spent on the article or the website, the lead to conversion content or similar can be interesting. Once a target value is envisioned and defined in more detail, the selection of the data basis and the extraction of the relevant prediction features can begin. In our example, the number of average views in the first 6 months after publication of the article was considered as an analysis objective.
Generating the database
Depending on the nature of the data source, making it available is a simple or complex process. In the simplest case, the text data is available directly as a database field, an easily readable file or via an API. For all types of text files (Word, PowerPoint, PDF) there are a number of useful Python libraries that can be used for extraction. If the desired data is hidden on the internet, a so-called web scraper can automatically process web pages and extract texts and other information. Properly designed, this provides up-to-date data with external information to enrich the data set. However, care should be taken to ensure the legality of the process and to avoid conflicts with data protection laws. In our application example, the blog data is generated via web extraction. The effort is justified because the final state of the articles is there, as it is available to readers on the internet.
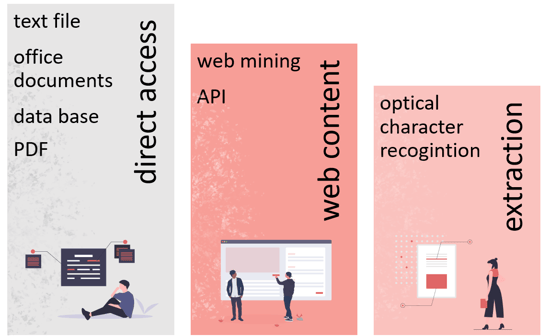
- Direct access in file form or via APIs
- Compliant web mining with the frameworks Scrapy or BeautifulSoup
- Extraction from PDF documents using pdfplumber, PyPDF4 or Optical Character Recognition
If the text data is to be collected in a database after extraction, SAP HANA platform is a good choice. There, the text can be stored as NCLOB data type alongside other metadata such as title, date and tags. SAP HANA platform offers the possibility to create a text index, which breaks down the text into its components and adds word classes, positions in the document, etc. This breakdown is excellent for data analysis.
Boost your business with
Artificial Intelligence and Machine Learning

Forming features from the text content and title
The next step is to explore the data and form the predictive factors. This process is more creative and extensive than with structured data. Based on the existing texts, a number of possible influencing factors can be formed and evaluated.
In addition to text characteristics such as the number of words and sentence length, the vocabulary used is also important. There are also a variety of NLP techniques that can be used to create specific features. Sentiment analysis assesses the texts based on subjectivity and polarity (negative, neutral, positive) and provides corresponding numeric features. Topic modelling is used to cluster thematically similar documents. The clustering itself can also be used as a feature. Finally, existing metadata is also helpful. Since blog articles have a time factor in terms of community building, the time of publication of the respective blog articles is important. This Topic modelling is used to cluster thematically similar documents. The clustering itself can also be used as a feature. Finally, existing metadata is also helpful. Since blog articles have a time factor in terms of community building, the time of publication of the respective blog articles is important.This community growth was latently built in by including the average website visits in the month before the time of publication as a factor.
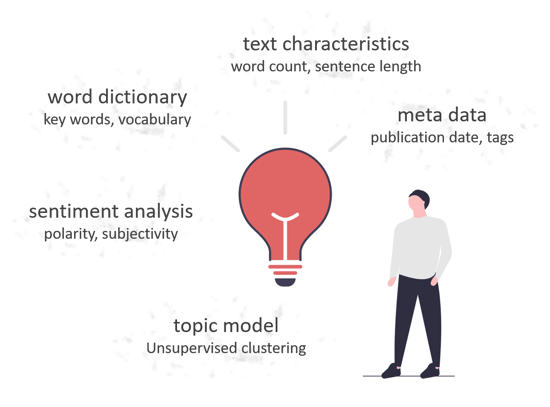
- Text characteristics such as word count, average sentence length and title length.
- Metadata such as topic tags and publication date
- Created features based on the vocabulary used
- Results of sentiment analysis
- Topic assignment through topic modelling
Creating a prediction model
Once the data including influencing factors is prepared, building a first forecast model is an easy task. Based on the data and the associated target value, the model derives the underlying rules on its own. This is why we refer to artificial intelligence and machine learning. In principle, model parameters are set with the help of the data. In the process, some differences occur between the model result and reality. The aim of modelling is to reduce these deviations to a minimum when new data is used. For this purpose, different model types, model settings and preparation steps for the data basis are systematically evaluated.
In our case, the target value is the views of the blog article in the first 6 months. So the prediction refers to a numerical value. It is a regression problem. For the underlying data, a random forest model was the most promising model. If the model should be applied to new, unpublished blog articles, these must be prepared in the same way like the training data. The implementation and orchestration of such data pipelines is also a crucial point for the long-term added value of a machine learning model.
Interpreting the results
The promise of success of a machine learning application does not end with the mere prediction of new results. Let's say that some blog articles are considered by the model to be particularly likely to succeed. If this claim is repeatedly confirmed, you would not want to stop. It is now interesting to find out why the prediction occurs and what levers there are to increase the reach.
With some models, the insights are easier to extract than with others. For example, the decision rules of a trained decision tree give an indication of the importance of the influencing factors. For more complex models, special Explainable AI frameworks are used. Here, the feature influence is determined via approaches from game theory, for example.
When analysing the reach of our blog articles, we were able to derive and quantify interesting findings. For example, an article on the topic of SAP Analytics Cloud or SAP Dashboarding generates twice the reach of an average article. Or as soon as the title of a blog article suggests a how-to guide, the reach is also particularly high.
Text Mining - Our Conclusion
The analysis of unstructured text data can thus produce interesting insights and also presents the analyst with an exciting new challenge. The open-source tool landscape is suitable for initial use cases, although libraries for German-language analyses are generally less elaborated. In the course of modelling, the real added value lies in the extraction of insights using ExplainableAI methods, which make the black box of the model transparent.
Would you like to discuss which machine learning use cases for text mining exist in your environment or do you even have a concrete problem in mind? We would be happy to work with you to develop a strategy for your text data and provide you with full support in the design, implementation and operation of the solution. Please do not hesitate to contact us.

