/Logo%202023%20final%20dunkelgrau.png?width=221&height=97&name=Logo%202023%20final%20dunkelgrau.png)























Das Potential von Machine Learning und Advanced Analytics liegt nicht nur in den strukturierten Daten, die sich leicht aus einer Datenbank oder einen Data Warehouse extrahieren lassen. Eine noch größere Datenmenge liegt versteckt in Dokumenten, E-Mails, Kommentaren und natürlich dem Internet.
Diese unstrukturierten Daten enthalten Informationen, welche nicht direkt zugänglich sind. Unter den Schlagwörtern Text Mining und Natural Language Processing (NLP) finden sich Methoden wieder, die es ermöglichen, vielfältige Erkenntnisse aus den Textdaten zu bergen.
In diesem Artikel lernen Sie grundlegende Methoden und zugehörige Frameworks anhand eines konkreten Anwendungsbeispiels aus dem Bereich Marketing kennen und erschließen so ein weiteres Datenfeld für Ihre Analysen.
Text Mining kann neben der reinen Analyse und Inhaltsextraktion aus Textdaten wie bei Reklamationskommentaren und Wartungsnotizen oft gewinnbringend eingesetzt werden. Beispielsweise werden die Textdaten genutzt, um Prognosefaktoren für ein Machine Learning Projekt abzuleiten. Neben der quantitativen Einstufung des Kundens anhand der Bestellhistorie (siehe RFM-Analyse) sind mit Text Mining auch qualitative Einschätzungen möglich.
Wir stellen Ihnen nachfolgend den Anwendungsfall Erfolgsprognose bei Blogartikeln vor.
Dazu werden folgende Schritte durchlaufen:
- Festlegen des konkreten Analyseziels
- Schaffen der Datenbasis
- Bilden von Features aus dem Textinhalt und Titel
- Erstellen eines Prognosemodells
- Interpretation der Ergebnisse
Festlegung des Analyseziels
Bevor Textdaten analysiert werden, sollte ein passendes Analyseziel gebildet werden, um für einen Mehrwert zu sorgen. Aus Marketingsicht ist der Erfolg eines Blogartikels ausschlaggebend und dieser ist erstmal mit verschiedenen KPIs messbar. Beispielsweise kann die Anzahl der Ansichten, die Verweildauer auf dem Artikel oder der Website, die Weiterleitung auf Conversion-Content o.ä. interessant sein. Sobald ein Zielwert ins Auge gefasst und näher definiert wird, kann die Auswahl der Datengrundlage und die Extraktion der relevanten Prognosefeatures beginnen. In unserem Beispiel wurde die Anzahl der durchschnittlichen Ansichten in den ersten 6 Monaten nach Veröffentlichung des Beitrages betrachtet.
Schaffen der Datenbasis
Je nach Beschaffenheit der Datenquelle ist das Verfügbarmachen ein einfacher oder aufwendiger Prozess. Im einfachsten Fall sind die Textdaten direkt als Datenbankfeld, eine leicht lesbare Datei oder über eine API verfügbar. Für alle Arten von Textdateien (Word, PowerPoint, PDF) finden sich eine Reihe an nützlichen Python Bibliotheken, die für die Extraktion verwendet werden können. Liegen die gewünschten Daten im Internet verborgen, kann ein sogenannter Web-Scrapper automatisiert Webseiten abarbeiten und Texte und andere Information herausziehen. Richtig gestaltet stehen so aktuelle Daten mit externen Informationen zur Bereicherung der Datenmenge zur Verfügung. Es sollte jedoch auf die Rechtmäßigkeit des Vorgangs und die Vermeidung von datenschutzrechtlichen Konflikten geachtet werden. In unserem Anwendungsbeispiel werden die Blogdaten über eine Webextraktion generiert. Der Aufwand ist gerechtfertigt, da dort der finale Stand der Artikel liegt, wie er im Internet den Lesern zur Verfügung steht.
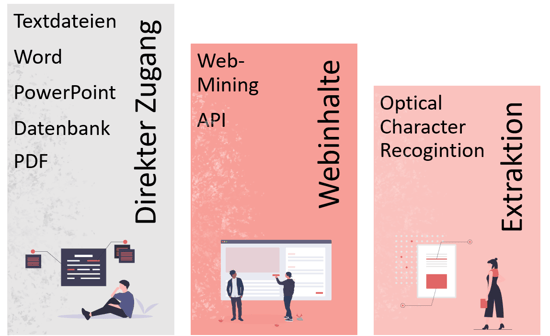
- Direkter Zugang in Dateiform oder über APIs
- Konformes Web-Mining mit dem Frameworks Scrapy oder BeautifulSoup
- Extraktion aus PDF Dokumenten mithilfe von pdfplumber, PyPDF4 oder Optical Character Recognition
Sollen die Textdaten nach der Extraktion in einer Datenbank aufgefangen werden, bietet sich hierfür eine SAP HANA Datenbank an. Dort kann der Text als NCLOB-Datentyp neben anderen Metadaten wie Titel, Datum und Tags gespeichert werden. Die SAP HANA Datenbank bietet die Möglichkeit einen Textindex zu erstellen, welcher den Text in seine Bestandteile zerlegt und Wortklassen, Positionen im Dokument etc. ergänzt. Diese Aufschlüsselung ist für die Datenanalyse hervorragend geeignet.
Kurbeln Sie Ihr Business an mit
Machine Learning und Künstlicher Intelligenz

Bilden von Features
Im nächsten Schritt geht es um die Exploration der Daten und das Bilden der Prognosefaktoren. Dieser Prozess ist kreativer und umfangreicher als bei strukturierten Daten. Auf Basis der vorhandenen Texte können eine Reihe an möglichen Einflussfaktoren gebildet und evaluiert werden.
Neben Textcharateristika wie die Wortanzahl und Satzlänge sind auch die verwendeten Wörter von Bedeutung. Hierfür gibt es eine Reihe an NLP-Techniken, welche zur Bildung der Features genutzt werden können. Beispielsweise kann anhand der verwendeten Wörter bestimmt werden, ob der Blogartikel in Form einer Anleitung geschrieben wurde. Eine andere NLP-Technik wie die Sentimentanalyse beurteilt die Texte anhand der Subjektivität (objektiv vs. subjektiv) und der Polarität (negativ, neutral, positiv) und liefert entsprechende Kennzahlen. Mithilfe des Topic-Modellings werden thematisch ähnliche Dokumente geclustert. Die Clusterzuordnung selber kann auch als Feature verwendet werden. Schlussendlich sind auch vorhandene Metadaten hilfreich. Da bei Blogartikeln ein Zeitfaktor bezüglich des Communityaufbaus mitwirkt, ist der Veröffentlichungszeitpunkt der jeweiligen Blogartikel wichtig. Der Communityaufbau wurde latent eingebaut, indem die durchschnittlichen Webseitenbesuche im Monat vor dem Zeitpunkt der Veröffentlichung als Faktor einfließen.
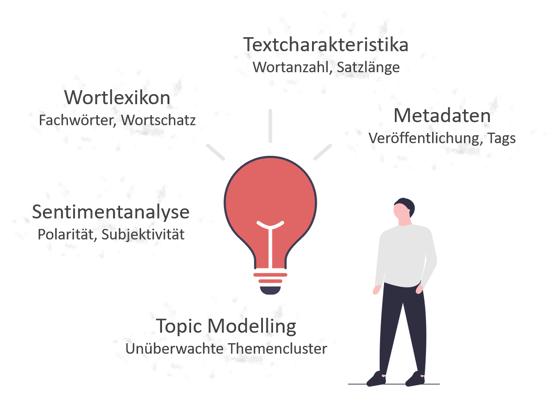
- Textcharakteristika wie Wortanzahl, durchschnittliche Satzlänge und Titellänge
- Metadaten wie Themen-Tags und das Veröffentlichungsdatum
- Erstellte Features auf Basis der verwendeten Wörter
- Ergebnisse einer Sentimentanalyse
- Themenzuordnung durch Topic Modelling
Erstellen eines Prognosemodells
Sobald die Daten inklusive Einflussfaktoren vorbereitet sind, ist das Bilden eines ersten Prognosemodells ein leichtes Unterfangen. Das Modell leitet anhand der Daten und des zugehörigen Zielwerts zugrundeliegende Regeln von selbst her. Deshalb spricht man auch von Künstlicher Intelligenz und Machine Learning. Im Prinzip werden Modellparameter mit Hilfe der Daten gesetzt. Dabei kommt es zu Abweichungen zwischen dem Modellergebnis und der Realität. Das Ziel der Modellbildung ist es, diese Abweichung bei neuen Daten auf ein Minimum zu reduzieren. Dafür werden verschiedene Modelltypen, Modelleinstellungen und Vorbereitungsschritte für die Datenbasis systematisch evaluiert.
In unserem Fall dienen als Zielwert die Ansichten des Blogartikels in den ersten 6 Monaten. Die Vorhersage bezieht sich also auf einen numerischen Wert. Es handelt sich um ein Regressionsproblem. Für die verwendete Datenbasis war ein Random-Forest-Modell am aussichtsreichsten. Wenn das Modell auf neue, unveröffentlichte Blogartikel angewendet werden soll, müssen diese analog aufbereitet werden. Die ins Modell integrierten Einflussfaktoren sind zwingend für jeden neuen Datenpunkt zu generieren. Die Implementierung und Orchestrierung solcher Datenpipelines sind ein entscheidender Punkt für den langfristigen Mehrwert eines Machine Learning Modells.
Interpretation der Ergebnisse
Mit der reinen Vorhersage von neuen Ergebnissen hört das Erfolgsversprechen einer Machine Learning Anwendung noch nicht auf. Angenommen, manche Blogartikel werden von dem Modell als besonders erfolgsträchtig eingestuft. Wenn sich diese Behauptung wiederholt bewahrheitet, würden Sie nicht stoppen wollen. Interessant ist es jetzt, herauszufinden, weshalb die Vorhersage eintrifft und welche Stellschrauben es gibt, um die Reichweite zu erhöhen.
Bei einigen Modellen sind die Erkenntnisse leichter extrahierbar als bei anderen. Beispielsweise geben die Entscheidungsregeln eines trainierten Entscheidungsbaums einen Hinweis über die Wichtigkeit der Einflussfaktoren. Für komplexere Modelle werden spezielle Explainable-AI-Frameworks verwendet. Beispielsweise wird hier der Featureeinfluss mittels Ansätzen aus der Spieltheorie ermittelt.
Bei der Analyse der Reichweite unserer Blogartikel konnten wir interessante Erkenntnisse ableiten und quantifizieren. Zum Beispiel generiert ein Artikel zum Thema SAP Analytics Cloud oder SAP Dashboarding im Schnitt die doppelte Reichweite eines Artikels. Oder sobald der Titel eines Blogbeitrages auf eine Anleitung schließen lässt, ist ebenfalls die Reichweite besonders groß.
Text Mining - Unser Fazit
Die Analyse von unstrukturierten Textdaten kann interessante Erkenntnisse hervorbringen und stellt auch Analysten vor eine neue spannende Herausforderung. Die Open-Source Toollandschaft ist dabei für erste Anwendungsfälle geeignet, wobei Bibliotheken für deutschsprachige Analysen im Allgemeinen weniger ausgearbeitet sind. Im Zuge einer Modellierung liegt der wahre Mehrwert in der Extraktion der Erkenntnisse mittels ExplainableAI-Methoden, welche die Black Box des Modells transparent werden lassen.
Möchten Sie erörtern, welche Machine-Learning Anwendungsfälle für Textmining in Ihrem Umfeld bestehen oder haben Sie sogar ein konkretes Problem im Visier? Wir erarbeiten gerne mit Ihnen gemeinsam eine Strategie für Ihre Textdaten und unterstützen Sie vollumfänglich in der Konzipierung, Implementierung und dem Betrieb der Lösung. Sprechen Sie uns gerne an!


