/Logo%202023%20final%20dunkelgrau.png?width=221&height=97&name=Logo%202023%20final%20dunkelgrau.png)























Data Science is a popular topic across industries. Particularly exciting are the presentations of results from internal projects that solve operational problems in no time using state-of-the-art models based on relevant data. However, the presenting Data Scientist often uses his own language, which is difficult to grasp for the business user. Statistical terms, mathematical formulas and keywords such as overfitting, feature engineering and RMSE have not yet established themselves in everyday business life. In order to help you solve these communication problems in the future, we would like to provide you with a clear overview of the most important ideas and concepts in this article.
The difference between Artificial Intelligence, Machine Learning and Deep Learning
The terms artifcial intelligence, machine learning and deep learning are often used interchangeably. From a theoretical point of view, this mixture is understandable: deep learning is a subfield of machine learning, which itself is an AI research field.

In this hierarchy, it's the subtleties that matter:
Artificial intelligence (AI) describes the automation of intelligent behavior. The term artificial intelligence is comprehensive and can always be used as a superordinate term. The term originated in computer science and unites a variety of research fields. These include, for example, intelligent robotics, computer vision, natural language processing and the investigation of special machine learning algorithms. Even a rule-based system can count as AI, as long as complex rules are used to technically emulate intelligent behavior. Until the late 1980s, such an approach was pursued in the field of word processing. Machine learning (ML) means that algorithms learn from data. They adapt their behavior optimally to the database in order to create a specific output. Similar to business, where decisions are often made based on key performance indicators (KPIs), machine learning has its own KPIs, called features. They serve as input for the model's output.

Broadly speaking, there are three different issues that are solved with ML. Supervised Learning with a known target, Unsupervised Learning to find relationships and Reinforcement Learning to encourage the right behavior.
Deep learning (DL) - as a subfield of machine learning - makes it possible to solve even more complex problems. With the idea of imitating the human brain, artificial neural networks were created that can even process image and text data. They are designed to simulate the interaction of neurons in the brain with their numerous connections.
Due to the complexity, a very large amount of data is needed to fit the model to the data. The increased computational effort is reflected in the training time - in some cases it takes weeks.
Deep learning has slowly found its way into the operational context since the 2010s despite the lack of transparency and complex composition.
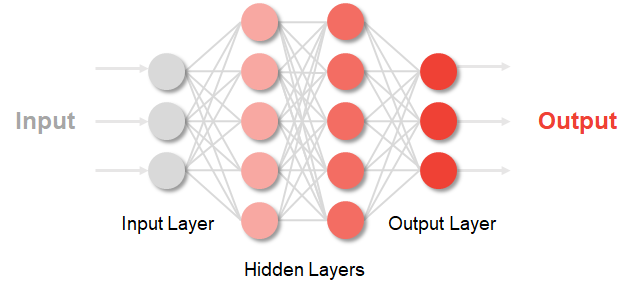
The 3 categories of machine learning in practice
The different task areas of machine learning come with their own issues and challenges. For which projects is which category suitable and which requirements must be met?

Supervised Learning is particularly suitable when an existing rule set is to be learned and applied. The influencing variables and associated target values are represented here in the form of data points. In everyday business, there are often problems that require a numeric value prediction (regression) or a classification into classes (classification).
The following requirements must be met:
- Correct data with complete target values
- Rules represented by features
- Sufficiently large data set
Reinforcement learning is also referred to as learning by doing. According to the trial-and-error principle, the model approaches a certain target state. Well-known examples are algorithms that have learned to play Super Mario or AlphaGo. The rules are learned along the way. The business application is predominantly in industry, where, for example, robots learn to pick up unsorted items and put them on an assembly line. This area is still very much in development and offers great potential coupled with great risks. If the targets are not formulated precisely and thoughtfully, an AI system can surprise the developer with unexpected behavior.
The following requirements must be met:
- Deep know-how in the reinforcement area
- Thoughtful definition of the environment
- Suitable reward function
How to advance your business through Artificial Intelligence and Machine Learning

Unsupervised learning helps to derive associations and related clusters from data. In the clustering process, the heterogeneous data set is divided into smaller, homogeneous groups. For example, in a business context, segmenting similar customers into a common group can help plan marketing and sales activities more effectively. The similarity is generated by the algorithm without prior knowledge (but based on the available data).Associations are formed by searching shopping carts or search histories for items that frequently occur together. This data can be used for targeted advertising and forming recommendations.
The following requirements must be met:
- Qualitative database with relevant factors
- Exclusion of strong changes over time
- Interpretability of the clusters or associations
Important technical terms in the context of the ML model
When presenting ML projects, we often refer to certain success and quality criteria of the model. In which context these terms belong, is explained here.
The model describes the center of the machine learning system. Mathematical modeling is used to represent the learning process and the resulting model can be applied to new data. The simplest model is a linear regression. Here, a straight line is fitted to the data set, i.e. adjusted so that the resulting deviation is minimal. The optimal straight line is marked in orange in the figure below. The gray lines are also possible models. However, they do not represent the data set very well.
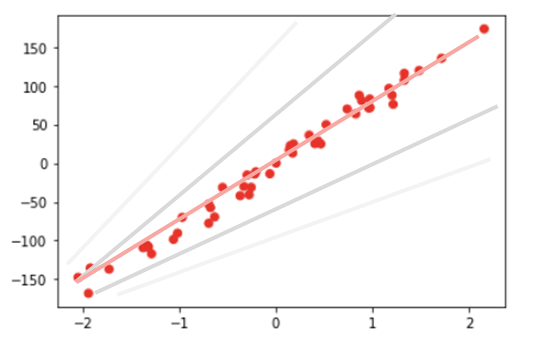
Of course, not all correlations are linear. For this, more complex methods can be used. Some of them are very understandable like a decision tree, others are a black box model. For example, in the case of the popular XG-Boost algorithm - which achieves really good results for many problems - it is not possible to directly understand how exactly the result is composed.
A machine learning system describes the productive machine learning model with all hardware and software components. A working model alone does not solve problems. An ML system, on the other hand, represents an application with added business value.
Features describe the characteristics that flow into the model in the form of data. For example, when predicting the payment date of an invoice, the invoice amount, temporal factors and specific behavioral characteristics of the debtor are included. For the training datasets, in supervised learning, these features and the target value are known.For prediction, only the features are known and provide an estimate.
- Feature Importance: meaningfulness of the features
- Feature Engineering: Creation of new features
Target Value in supervised learning describes the value to be predicted by the model. This can be either a specific numerical value (regression) or one or more categories (classification).
During training, the model is modified in such a way that the deviation of the target values of the training set becomes minimal. The deviations for numerical values are usually determined with the root mean square error (RMSE). Accuracy is often specified in the classification.
Hyperparameters describe the configuration possibilities of the model training and generally the aspects of the learning behavior. In hyperparameter tuning, the learning behavior of the model can be systematically adjusted to improve the performance of the model.
Overfitting refers to an extreme fit of the model to the data used. The model follows not only the trend but also the specifics. In general, an exact fit to the data is desired to achieve good forecast accuracy. However, if the model follows the random fluctuations of the data, it has a negative impact on forecasting new data. A countermeasure is to increase the amount of data or to limit the flexibility of the model.
Do you still have questions? Would you like to go deeper? NextLytics is always at your side as an experienced project partner. We help you to effectively solve your data problems from data integration to model deployment and also teach you the theoretical and methodological basics.

