/Logo%202023%20final%20dunkelgrau.png?width=221&height=97&name=Logo%202023%20final%20dunkelgrau.png)























Data Science ist branchenübergreifend ein beliebtes Thema. Besonders spannend sind die Ergebnispräsentationen von internen Projekten, die betriebliche Probleme im Handumdrehen mit state-of-the-art Modellen datenbasiert lösen. Jedoch benutzt der präsentierende Data Scientist oft eine eigene Sprache, welche für den Fachanwender nur schwer greifbar ist. Statistische Fachbegriffe, mathematische Formeln und Keywords, wie Overfitting, Feature Engineering und RMSE haben sich im Geschäftsalltag noch nicht etabliert. Damit Sie zukünftig diese Kommunikationsprobleme lösen und mitreden können, möchten wir Ihnen in diesem Artikel einen bildhaften und übersichtlichen Überblick über die wichtigsten Ideen und Konzepte vermitteln.
Der Unterschied zwischen Künstlicher Intelligenz (KI), Machine Learning und Deep Learning
Die Begriffe Künstliche Intelligenz, Machine Learning und Deep Learning werden oft synonym verwendet. Von der theoretischen Seite aus, ist diese Durchmischung nachvollziehbar: Deep Learning ist ein Teilgebiet von Machine Learning, welches wiederum selbst ein KI-Forschungsfeld ist.

In dieser Hierarchie, kommt es auf die Feinheiten an:
Künstliche Intelligenz (KI) beschreibt die Automatisierung von intelligenten Verhalten. Der Begriff Künstliche Intelligenz ist dabei umfassend und als übergeordneter Begriff immer verwendbar. Die Bezeichnung wird aus der Informatik geprägt und vereint eine Vielzahl an Forschungsfeldern. Darunter fallen zum Beispiel die intelligente Robotik, Computer Vision, Natural Language Processing und die Erforschung spezieller Machine Learning Algorithmen.
Selbst ein regelbasiertes System kann zu Künstlicher Intelligenz zählen, sofern komplexe Regeln dazu genutzt werden, intelligentes Verhalten technisch nachzubilden. Bis in die späten 1980er Jahre wurde solch ein Ansatz im Bereich der Textverarbeitung betrieben.
Machine Learning (ML) heißt, dass Algorithmen anhand von Daten lernen. Sie passen ihr Verhalten optimal an die Datenbasis an, um einen bestimmten Output zu kreieren. Ähnlich wie im Unternehmen, in denen Entscheidungen häufig auf Basis von Key Performance Indicator (KPI) getroffen werden, besitzt das maschinelle Lernen eigene KPIs, die sogenannten Features. Sie dienen als Input für die Ausgabe des Modells.

Dabei gibt es im Groben drei verschiedene Fragestellung, die mit ML gelöst werden. Überwachtes Lernen (Supervised Learning) mit bekannter Zielgröße, Unüberwachtes Lernen (Unsupervised Learning) zum Finden von Zusammenhängen und Bestärkendes Lernen (Reinforcement Learning) für die Förderung des richtigen Verhaltens.
Deep Learning (DL) ermöglicht es - als Teilgebiet des maschinellen Lernens - noch komplexere Probleme zu lösen. Mit dem Gedanken das menschliche Gehirn nachzuahmen, entstanden künstliche neuronale Netzwerke, die selbst Bild- und Textdaten verarbeiten können. Sie sollen das Zusammenspiel der Neuronen im Gehirn simulieren.
Durch die Komplexität wird eine sehr große Datenmenge für die Anpassung des Modells an die Daten benötigt. Der erhöhte Rechenaufwand spiegelt sich in der Trainingszeit wieder - teilweise beträgt diese Wochen.
Deep Learning findet trotz fehlender Transparenz und komplizierter Gestaltung seit den 2010er langsam Einzug in den betrieblichen Kontext.
Die 3 Kategorien von Machine Learning in der Praxis
Die verschiedenen Aufgabengebiete des Maschinellen Lernens kommen mit eigenen Fragestellungen und Herausforderungen einher. Für welche Projekte eignet sich welche Kategorie und welche Voraussetzungen müssen erfüllt sein?

Supervised Learning eignet sich besonders, wenn eine vorhandene Gesetzmäßigkeit gelernt und angewendet werden soll. Die Einflussgrößen und zugehörige Zielwerte sind hier in Form von Datenpunkten repräsentiert. Im Geschäftsalltag finden sich häufig Probleme die eine Wertvorhersage (Regression) oder eine Einordnung in Klassen (Klassifizierung) benötigen.
Folgende Voraussetzungen müssen erfüllt sein:
- Korrekte Daten mit vollständigen Zielwerten
- Gesetzmäßigkeit durch Features repräsentiert
- Ausreichend große Datenmenge
Reinforcement Learning wird auch als Lernen durch Ausprobieren bezeichnet. Nach dem Prinzip Versuch-und-Irrtum nähert sich das Modell einem bestimmten Zielzustand. Bekannte Beispiele sind Algorithmen, die gelernt haben, Super Mario oder AlphaGo zu spielen. Die geschäftliche Anwendung ist überwiegend in der Industrie, in der beispielsweise Roboter lernen, unsortierte Gegenstände aufzusammeln und auf ein Fließband zu legen. Dieser Bereich ist noch stark in der Entwicklung und bietet großes Potential gepaart mit großen Risiken. Sind die Zielvorgaben nicht präzise und durchdacht formuliert, kann ein KI-System den Entwickler mit unerwarteten Verhalten überraschen.
Folgende Voraussetzungen müssen erfüllt sein:
- Tiefes Know-How im Reinforcement Bereich
- Durchdachte Definition der Umgebung
- Passende Belohnungsfunktion
So kurbeln Sie Ihr Business durch
Künstliche Intelligenz und Machine Learning an

Unsupervised Learning hilft Assoziationen und zusammengehörige Cluster aus Daten abzuleiten. Im Clustering-Verfahren wird die heterogene Datenmenge in kleinere, homogene Gruppen aufgeteilt. Beispielsweise kann im betrieblichen Kontext eine Segmentierung ähnlicher Kunden in eine gemeinsame Gruppen helfen, Marketing- und Vertriebsaktivitäten effektiver zu planen. Die Ähnlichkeit wird dabei durch den Algorithmus ohne Vorkenntnisse (aber anhand der Daten) generiert.
Beim Bilden von Assoziationen werden Warenkörbe oder Suchverläufe nach häufig gemeinsam auftretenden Objekten durchsucht. Diese Daten können für die gezielte Werbung und das Bilden von Empfehlungen genutzt werden.
Folgende Voraussetzungen müssen erfüllt sein:
- Qualitative Datenbasis mit relevanten Faktoren
- Ausschließen von starken Veränderungen über die Zeit
- Interpretationsfähigkeit der Cluster oder Assoziationen
Wichtige Fachbegriffe im Rahmen des ML-Modells
Oft wird bei der Präsentation von ML-Projekten auf bestimmte Erfolgs- und Qualitätskriterien des Modells eingegangen. In welchem Kontext diese Begriffe stehen, erklären wir im Folgenden.
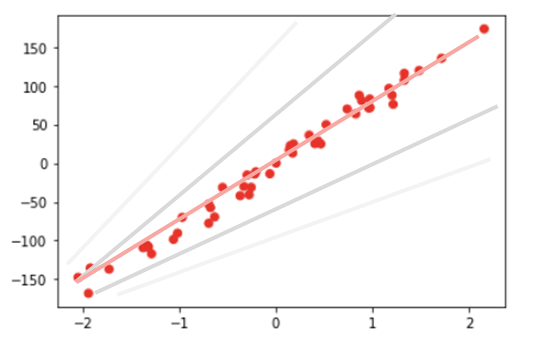
Modell beschreibt das Zentrum des Machine Learning Systems. Mit einer mathematischer Modellierung wird der Lernvorgang abgebildet und kann auf neue Daten angewendet werden. Das einfachste Modell entspricht der Linearen Regression. Hier wird eine Gerade auf die Datenmenge gefittet d. h. so angepasst, dass die entstehende Abweichung minimal wird. Die optimale Gerade ist im untenstehenden Bild orange gekennzeichnet. Die grauen Linien sind ebenfalls mögliche Modelle. Sie repräsentieren den Datensatz jedoch nur schlecht.
Selbstverständlich verlaufen nicht alle Zusammenhänge linear. Dafür können komplexere Methoden eingesetzt werden. Einige davon sind sehr verständlich wie ein Entscheidungsbaum, andere sind ein Black-Box-Modell. Beispielsweise kann bei dem beliebten XG-Boost Algorithmus - der bei vielen Problemen phänomenale Ergebnisse erzielt - nicht direkt nachvollzogen werden, wie genau sich das Ergebnis zusammensetzt.
Machine-Learning-System beschreibt das produktiv gesetzte Machine Learning Modell mit allen Hardware- und Softwarekomponenten. Ein funktionierendes Modell alleine löst keine Probleme. Ein ML-System hingegen stellt eine Anwendung mit geschäftlichem Mehrwert dar.
Features beschreibt die Merkmale, die in Form von Daten in das Modell einfließen. Bei der Vorhersage des Bezahldatums einer Rechnung fließen beispielsweise der Rechnungsbetrag, zeitliche Faktoren und spezifische Verhaltensmerkmale des Debitoren ein. Für die Trainingsdatensätze sind beim überwachten Lernen diese Features und der Zielwert bekannt. Für eine Vorhersage sind nur die Features bekannt und liefern eine Schätzung.
- Feature Importance: Aussagekraft der Features
- Feature Engineering: Kreieren neuer Features
Zielwert (Target Value) beschreibt beim Supervised Learning den Zielwert, der mit dem Modell vorhergesagt werden soll. Dieser kann entweder ein bestimmter numerischer Wert sein (Regression) oder eine oder mehrere Kategorien (Klassifikation).
Beim Training wird das Modell so modifiziert, dass die Abweichung der Zielwerte des Trainingssatzes minimal werden. Die Abweichungen bei numerischen Werten werden üblicherweise mit dem mittleren Abweichungsquadrat (RMSE) bestimmt. Bei der Klassifizierung wird oft die Accuracy (Treffsicherheit) angegeben.
Hyperparameter beschreiben die Konfigurationsmöglichkeiten des Modelltrainings und allgemein die Aspekte des Lernverhaltens. Beim Hyperparameter Tuning kann das Lernverhalten des Modells systematisch und zielfördernd angepasst werden, um die Performance des Modells zu verbessern.
Overfitting bezeichnet die Überanpassung des Modell an die verwendeten Daten. Das Modell folgt nicht nur dem Trend, sondern auch den Besonderheiten. Im Allgemeinen ist eine genaue Anpassung an die Daten gewünscht, um eine gute Prognosegenauigkeit zu erzielen. Folgt das Modell jedoch den zufälligen Schwankungen der Daten, wirkt sich das negativ auf die Prognose neuer Daten aus. Als Gegenmaßnahme bietet sich eine Vergrößerung der Datenmenge an oder die Flexibilität des Modells muss eingeschränkt werden.
Haben Sie noch Fragen? Möchten Sie noch tiefer einsteigen? NextLytics steht Ihnen jederzeit als erfahrener Projektpartner zur Seite. Wir helfen Ihnen Ihre Datenprobleme von der Datenintegration bis zum Modell-Deployment effektiv zu lösen und bringen Ihnen auch die theoretischen und methodischen Grundlagen näher.


