/Logo%202023%20final%20dunkelgrau.png?width=221&height=97&name=Logo%202023%20final%20dunkelgrau.png)























As more and more business intelligence use cases rely on machine learning (ML) models to support advanced analytics, operating these models in a reliable and scalable framework becomes a cornerstone of data teams’ work. An emerging logical component of the ML framework is the feature store that bridges data sources and model development. Where this has previously been a socio-technical interface between data warehouse teams and data scientists, introducing an actual technological component to harmonize data usage in ML development may greatly improve efficiency.
This article will introduce the concept of the feature store and highlight the promises it holds. You will learn whether your organization could benefit from a feature store or not.
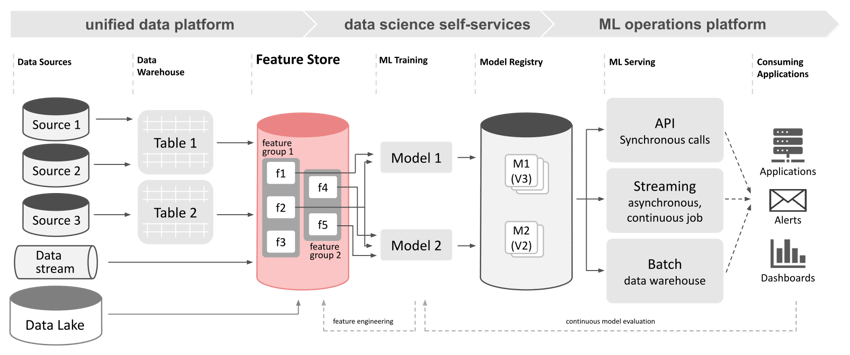
The feature store acts as an additional abstraction layer between data sources and data scientists. Source systems in this context may refer to already well-defined and curated data warehouse or data lake ecosystems. Data retrieved from these systems for machine learning applications will be subject to a feature engineering process usually applied by the data scientist working on an ML model. Feature engineering adds further transformation and cleaning steps to the data retrieved from a warehouse or data lake to meet the syntactic and semantic demands of the chosen machine learning algorithms. This may be as simple as querying aggregates from the right data warehouse tables, or it may be of immense effort as data from multiple (internal and external) sources has to be merged, complex aggregates have to be calculated, normalizations applied, etc.
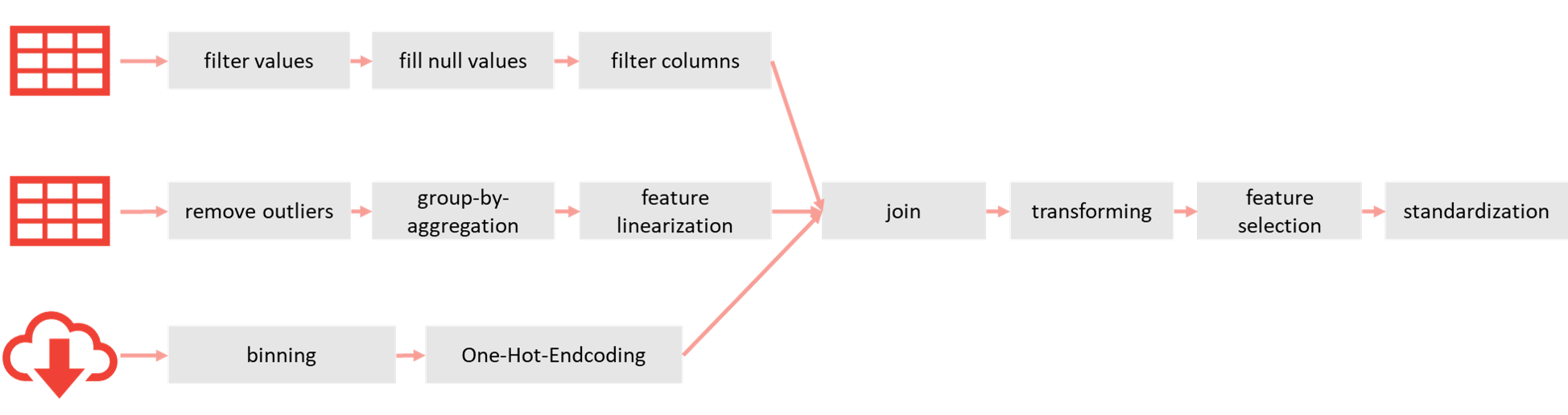
Typical example of feature engineering steps in a usual ML project with three sources. The result will be stored in a feature store for direct access instead of repeating those steps.
As more ML models are established in the enterprise, the same features are also used more often. Specifically, customer features can be used in customer segmentation for targeted marketing, an incoming payment forecast, or in the creation of recommendation systems. The complexity of the feature engineering steps multiplies when they have to be applied for multiple ML workflows. Not only is the computational cost increased but the resulting duplication of code invites errors, divergence of processes, and increased maintenance effort.
The feature store aims to reduce these risks and efforts. All feature engineering steps are unhinged from the model development and moved to a dedicated feature store ingestion stage. The centralization is supplemented by explicit versioning of the features in order to be able to use the same features in retraining. At the same time, a new version of these (for example, by adjusting the fill value of missing values) can be flexibly tried out. Data scientists only have to query the feature store API to retrieve input for their work in the required syntactic and semantic form, e.g. loading data directly as a DataFrame object instead of downloading and reading from a file first. Apart from decoupling and streamlining the development process, this enables reuse and usage tracking of features. Validation may be included in the feature ingestion stage to provide only feature data that meets necessary quality criteria.
Feature Store Functionality
Introducing a feature store into the machine learning workflow promises to decouple and disentangle the data flow between source systems and model building/serving stages. Additionally, feature stores offer some distinct functionality to further improve efficiency of the process which are not typically provided by common sources:
- Integration of online and offline data sources
- Training data management
- Feature registration and discovery
- Feature versioning and “time travel” functionality
- Tracking of data lineage
How to advance your business through AI and Machine Learning - Download your whitepaper here!

Online/Offline Source Integration
The feature store provides a single point of contact for downstream data consumers like machine learning models. The task of collecting data items from different source systems is hidden from the data scientist behind the feature store API. The feature store can internally split between low-latency “online” sources and bulk data “offline” sources to optimize performance. If newest data items from a streaming source are required for a downstream application, these can be directly pulled from the message queue system, aggregated with most recent items from the online storage, and delivered in near real-time. If a large historical set of data items is required, these can be loaded from offline sources like data objects from a data lake system, aggregated, and delivered as a single batch in due time. The complexity of joining semantically identical data from different sources is no longer of any concern for the data scientist preparing the model.
Training Data Management
A feature store may provide an API endpoint to join feature sets into training datasets internally. The training dataset managed by the feature store engine and pre-calculated splits into test and validation subsets can be directly retrieved by a downstream consumer. Data scientists working with a feature store that handles training data like this can offload another recurring task from actual model development jobs. The same training dataset can be reused in an arbitrary number of downstream jobs.
Feature Registration and Discovery
Depending on the feature store software, user interfaces and API endpoints for self-service feature registration and feature discovery can be part of the system. Feature or data discovery is an integral part of data scientists’ work. Depending on the maturity of source systems or (meta)data catalog systems, it can also be a time consuming and expensive task. A feature store with a rich user interface may enable fast discovery of the right data items for a new machine learning project or help to point out missing items. If feature registration is offered as a self-service, data scientists could be encouraged to create the necessary items themselves without waiting for data engineering or data warehouse teams to implement pipelines or views.
Feature Versioning / Time Travel
Acquiring different chronological snapshots of the same data can be necessary for appropriate training and evaluation of machine learning models. Feature stores combine every registered value with a timestamp and can provide comprehensive versioning of all data items. Retrieval of snapshots is generally a simple matter of including an additional timestamp parameter when querying data from the API.
Data Lineage Tracking
Based on the feature versioning mechanisms, feature stores can collect, track, and sometimes visualize data lineage. Lineage across the entire data engineering and machine learning pipeline may be crucial to build reliable and trusted data-driven applications. Feature stores come equipped with the necessary API endpoints to retrieve lineage metadata for registered items, e.g. when the respective feature version has been created, retrieved, or combined into a training dataset.
Feature Stores - Our Conclusion
Feature stores aim to further harmonize the machine learning development and operations processes. As more and more models are translated and incorporated into business applications, the additional logical feature layer increases data teams’ efficiency by enabling re-use and easy reproduction of tasks.
The feature store can be an important component in a machine learning operations framework and contribute significantly to an overall advanced analytics self-service infrastructure. It can help to declutter model development workflows and provide data engineering- and data science teams with a well-defined interface to improve collaboration. Introducing a new layer of abstraction comes at the cost of increased system complexity and maintenance though. The decision whether to invest into a dedicated feature store should therefore be well considered and actual pain points of your organization's current architecture carefully weighed against the possible benefits.
We will focus on the topic of feature stores again next week with an overview of implementation options and available software solutions in the market.
Do you have further questions about feature stores as an addition to your data science infrastructure or do you need an implementation partner? We are happy to support you from problem analysis to technical implementation. Get in touch with us today!

