/Logo%202023%20final%20dunkelgrau.png?width=221&height=97&name=Logo%202023%20final%20dunkelgrau.png)























Da immer mehr Business Intelligence Anwendungsfälle auf Machine Learning (ML) Modelle zur Unterstützung fortschrittlicher Analysen angewiesen sind, wird der Betrieb dieser Modelle in einem zuverlässigen und skalierbaren Framework zu einem Eckpfeiler der Arbeit von Data Teams. Eine neue logische Komponente des ML-Frameworks ist der Feature Store, der Datenquellen und Modellentwicklung miteinander verbindet. Wo dies bisher eine soziotechnische Schnittstelle zwischen Data Warehouse- und Data Science Teams ist, kann die Einführung einer tatsächlichen technologischen Komponente zur Harmonisierung der Datennutzung bei der ML-Entwicklung die Effizienz erheblich steigern.
In diesem Artikel stellen wir das Konzept des Feature Stores vor und erläutern, welche Vorteile dieses verspricht. Sie werden erfahren, ob und wie Ihr Unternehmen von einem Feature Store profitieren kann.
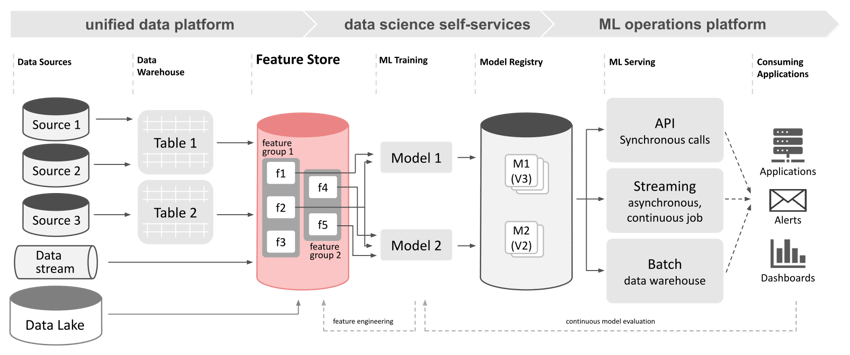
Der Feature Store fungiert als zusätzliche Abstraktionsschicht zwischen Datenquellen und Data Scientists. Quellsysteme können in diesem Zusammenhang bereits gut definierte und kuratierte Data Warehouse- oder Data Lake-Ökosysteme sein. Daten aus diesen Systemen werden in aller Regel einem Feature-Engineering-Prozess unterzogen, wenn ein Data Scientist sie in der Entwicklung eines neuen Modells verwenden will. Beim Feature-Engineering werden die aus einem Data Warehouse oder Data Lake abgerufenen Daten in weiteren Schritten umgewandelt und bereinigt, um die syntaktischen und semantischen Anforderungen der gewählten Algorithmen zu erfüllen. Dies kann von einfachen Abfragen von Aggregaten aus den richtigen Data Warehouse-Tabellen bis zu einem immensen Aufwand skalieren, wenn Daten aus mehreren (internen und externen) Quellen zusammengeführt, komplexe Aggregate berechnet, Normalisierungen angewendet werden müssen usw.
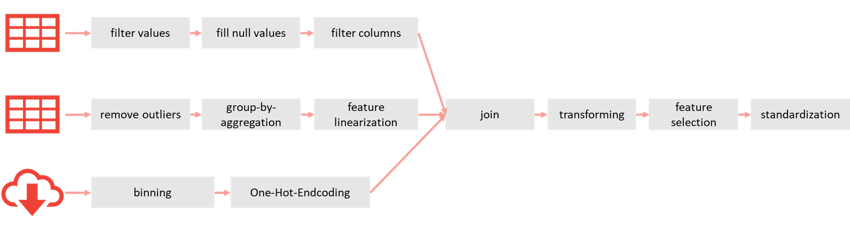
Typisches Beispiel für Feature-Engineering-Schritte in einem ML-Projekt mit drei Quellen. Das Ergebnis kann in einem Feature Store für den direkten Zugriff gespeichert werden, anstatt diese Schritte zu wiederholen.
Je mehr ML-Modelle im Unternehmen etabliert werden, desto häufiger werden auch dieselben Features verwendet. Konkret können Kunden-Features bei der Kundensegmentierung für gezieltes Marketing, einer Zahlungseingangsprognose oder bei der Erstellung von Empfehlungssystemen verwendet werden. Die Komplexität der Feature Engineering-Schritte vervielfacht sich, wenn sie für mehrere ML-Workflows angewendet werden müssen. Dadurch steigt nicht nur die Rechenzeit, sondern die daraus resultierende Vervielfältigung von Codes lädt zu Fehlern, abweichenden Prozessen und erhöhtem Wartungsaufwand ein.
Der Feature Store soll diese Risiken und den Aufwand reduzieren. Alle Schritte des Feature Engineerings werden von der Modellentwicklung abgekoppelt und in ein eigenes Spezialsystem verlagert. Ergänzt wird diese Zentralisierung durch eine explizite Versionierung der Features, um dieselben Features beim Retraining verwenden zu können. Gleichzeitig kann eine neue Version dieser (z. B. durch Anpassung des Default-Wertes für fehlende Einträge) flexibel erprobt werden. Ein Data Scientist muss letztlich nur die Feature Store API abfragen, um den Input für die Verwendung in der gewünschten syntaktischen und semantischen Form zu erhalten, z. B. indem Daten direkt als DataFrame-Objekt geladen werden können, anstatt sie erst aus einer Datei herunterzuladen und einzulesen. Neben der Entkopplung und Straffung des Entwicklungsprozesses ermöglicht dies die Wiederverwendung und Verfolgung der Nutzung von Features. Eine automatische Validierung kann in die Phase der Feature-Aufnahme integriert werden, sodass nur Features bereitgestellt werden, welche den erforderlichen Qualitätskriterien entsprechen.
Spezialfunktionen des Feature Stores
Die Einführung eines Feature Stores in den ML-Workflow verspricht, den Datenfluss zwischen den Quellsystemen und den Phasen der Modellerstellung und -wartung zu entkoppeln und zu entflechten. Darüber hinaus bieten Feature Stores einige spezifische Funktionen zur Verbesserung der Effizienz des Prozesses, die in der Regel nicht von gängigen Quellen bereitgestellt werden:
- Integration von Online- und Offline-Datenquellen
- Verwaltung von Trainingsdaten
- Auffinden und Registrieren von Features
- Versionierung von Features und "Time Travel"-Funktion
- Verfolgung der Datenherkunft
So kurbeln Sie Ihr Business durch Künstliche Intelligenz und Machine Learning an - Laden Sie hier Ihr Whitepaper herunter!

Integration von Online/Offline-Datenquellen
Der Feature Store bietet eine zentrale Anlaufstelle für nachgelagerte Verarbeitungsschritte und Applikationen wie z. B. ML-Modelle. Die Abfrage und Integration von Datenelementen aus verschiedenen Quellsystemen bleiben bei einem Feature Store für die ML-Entwickler hinter der Feature Store API verborgen. Der Feature Store kann intern zwischen "Online"-Quellen mit niedriger Latenz und "Offline"-Quellen für den Abruf von großen Datenmengen aufgeteilt werden, um die Leistung zu optimieren. Wenn die neuesten Datenelemente aus einer Streaming-Quelle für eine nachgeschaltete Anwendung benötigt werden, können diese direkt aus der Event Queue abgerufen, mit den neuesten Elementen aus dem Online-Speicher zusammengeführt und nahezu in Echtzeit bereitgestellt werden. Wenn ein großer historischer Datensatz benötigt wird, kann dieser aus Offline-Quellen wie Datenobjekten in einem Data Lake geladen, aggregiert und als ein einziger Batch geliefert werden.
Verwaltung von Trainingsdaten
Ein Feature Store kann einen API-Endpunkt bereitstellen, um Feature-Gruppen intern zu Trainingsdatensätzen zusammenzufügen. Der vom Feature Store verwaltete Trainingsdatensatz und die vorberechneten Splits in Test- und Validierungsmengen können direkt abgerufen werden. Den ML-Entwickler können diese Funktionen von wiederkehrenden Verarbeitungsschritten entlasten und so mehr Ressourcen für die Optimierung des eigentlichen Machine Learning Verfahrens freigeben. Auf diese Weise erzeugte Trainingsdatensätze können ebenfalls für die weitere Verwendung in mehreren Anwendungsszenarien wiederverwendet werden.
Auffinden und Registrieren von Features
Je nach gewählter Feature Store Software können Benutzerschnittstellen und API-Endpunkte für die Self-Service-Feature-Registrierung und Feature-Erkennung Teil des Systems sein. Die Identifikation von relevanten Features und Metriken ist ein wesentlicher Bestandteil der Arbeit der Data Scientists. Je nach Reifegrad der Quellsysteme oder (Meta-)Datenkataloge kann dies eine zeitaufwändige und mühsame Aufgabe sein. Ein Feature Store mit einer ausgereiften Benutzeroberfläche kann das schnelle Auffinden der richtigen Datenelemente für ein neues ML-Projekt ermöglichen oder dabei helfen, fehlende Datenpunkte zu erschließen. Sofern das Einspielen von Features als Self-Service angeboten wird, können Datenwissenschaftler die erforderlichen Elemente selbst erstellen, ohne auf die Implementierung von Pipelines oder Views durch Data Engineering- oder Data Warehouse Teams zu warten.
Feature Versionierung / Time Travel
Die Erfassung verschiedener chronologischer Snapshots derselben Daten kann für das Training und die Bewertung von ML-Modellen erforderlich sein. Feature Stores versehen jeden registrierten Wert mit einem Zeitstempel und können eine umfassende Versionierung aller Datenelemente bieten. Der Abruf von Momentaufnahmen ist im Allgemeinen über die Hinzunahme zusätzlicher Zeitstempel-Parameter bei der Abfrage von Daten über die API mit minimalem Aufwand möglich.
Verfolgung der Datenherkunft
Basierend auf der Versionierung von Features können Feature Stores die sogenannte “Data Lineage” erfassen, verfolgen und mitunter auch visualisieren. Die Abstammung von Datensätzen über die gesamte Pipeline der Datenverarbeitung und des Machine Learning kann für die Entwicklung zuverlässiger und vertrauenswürdiger datengesteuerter Anwendungen entscheidend sein. Feature Stores sind mit den notwendigen API-Endpunkten ausgestattet, um Lineage-Metadaten für registrierte Elemente abzurufen,
z. B. wann die jeweilige Feature Version erstellt, abgerufen oder zu einem Trainingsdatensatz kombiniert wurde.
Feature Stores - Unser Fazit
Feature Stores zielen darauf ab, die Entwicklungs- und Betriebsprozesse des maschinellen Lernens weiter zu harmonisieren. Da immer mehr Modelle übersetzt und in Geschäftsprozesse integriert werden, verspricht die zusätzliche logische Funktionsebene die Effizienz der Data Teams zu steigern, indem sie die Wiederverwendung und einfache Reproduktion von Aufgaben ermöglicht.
Der Feature Store kann eine wichtige Komponente in einer Machine Learning Architektur sein und einen wichtigen Beitrag zur gesamten Infrastruktur für Advanced Analytics Self-Service Systeme leisten. Er kann dazu beitragen, die Arbeitsabläufe bei der Modellentwicklung zu vereinfachen und kann Data Engineering- und Data Science Teams eine klar definierte Schnittstelle zur besser Kollaboration bieten. Die Einführung einer neuen Abstraktionsebene geht jedoch mit steigender Systemkomplexität und höheren Wartungsaufwänden einher. Die Entscheidung, ob in einen dedizierten Feature Store investiert werden sollte, will daher gut überlegt sein. Die spezifischen Problemstellen der aktuellen Architektur Ihres Unternehmens sind sorgfältig gegenüber möglichen Vorteilen abzuwägen.
Wir greifen das Thema Feature Store im NextLytics Blog in der kommenden Woche erneut auf und werden Ihnen einen Überblick der verschiedenen Umsetzungsmöglichkeiten und Feature Store Produkte im Markt geben.
Haben Sie weitere Fragen zu Feature Stores als Ergänzung zu Ihrer Data Science Infrastruktur oder benötigen Sie einen Implementierungspartner? Wir unterstützen Sie gerne von der Problemanalyse bis zur technischen Umsetzung. Nehmen Sie noch heute Kontakt mit uns auf!


