






















Without a doubt, our daily lives become increasingly data-driven and the amount of data is continuously increasing every day. Thus, the amount of data that is generated and processed in your company across all areas is also growing with each passing day. With this exponential data growth, the performance of a business warehouse is particularly important.
One way to increase the performance of your business warehouse is SQLScript. Especially if you use a lot of custom logic, SQLScript can really help in terms of performance. With the help of SQLScript in SAP HANA, data-intensive calculations can be carried out at the database level. Which has led to a paradigm shift - instead of loading the data from the database to the ABAP server to perform the calculations there ("data to code" paradigm), the calculation is now performed directly in the SAP HANA database, meaning the code is brought to data.
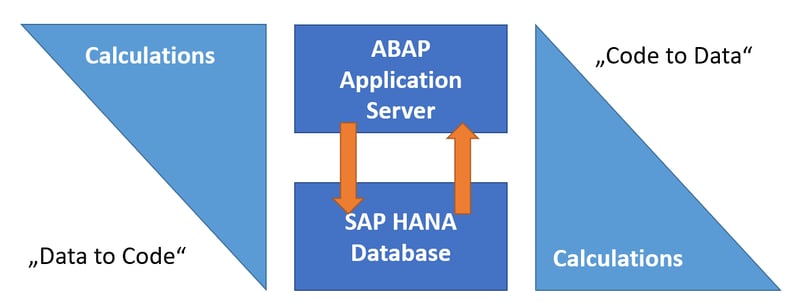
SQLScript offers a wider range of functions than SQL and also allows flow control. It enables you to enhance the performance of your SAP HANA database without restricting yourself to the Open SQL functions. This is because HANA in itself represents a very smart database. In the following, I will discuss the components of HANA that make it so special.
SAP HANA is primarily known as an in-memory database. Instead of the hard drive, the computer's main memory is used to store the data, which enables much faster access. This means that even large amounts of data can be processed with high performance.
However, the core of HANA technology does not lie in massive working memory performance, but in the novel database architecture. The high performance is only made possible by the combination of four already known technologies: reading and writing in both row and column format, compression, encoding as well as insert-only principle. In the next chapters I explain these components in detail.
Line and column format brought under one roof
The HANA database can operate in both row and column format. While the column format enables fast read access, the row format is more efficient for write operations.
In the following, I explain the respective approach using an example. Let's look at the table below:
|
ID |
Name |
Department |
Salary |
|
1 |
Sebastian |
Controlling |
115.000 |
|
2 |
Patrick |
Controlling |
110.000 |
|
3 |
Dirk |
IT |
110.000 |
However, this table represents only the presentation view. In fact, the information is stored in the database in a different form. For example, the contents of the table shown above could be stored in a row-based database as follows:
1, Sebastian, Controlling, 115000;
2, Patrick, Controlling, 110000;
3, Dirk, IT, 110000;
In a column-based database, the same table would look like this:
1, 2, 3;
Sebastian, Patrick, Dirk;
Controlling, Controlling, IT;
115000, 110000, 110000;
The column-based approach leads to the following advantages. For example, if you want to evaluate salaries and see the sum of all salaries, the column-based database requires only one read access. Thus, only the last row with the salaries needs to be read.
A row-based database, on the other hand, would have to go through all the rows and read the salary information. In our example, it would correspond to three reads, which of course takes longer. Three times as long as the column-based approach.
Increase the performance of your BW with SQLScript

The same is true if you want to evaluate the total number of employees. While a column-based database gets by with one read access, the row-based database requires three accesses.
However, the column-based databases have a significant disadvantage. Let's assume that our company hires another employee, so our table looks like this:
|
ID |
Name |
Department |
Salary |
|
1 |
Sebastian |
Controlling |
115.000 |
|
2 |
Patrick |
Controlling |
110.000 |
|
3 |
Dirk |
IT |
110.000 |
|
4 |
Steffen |
IT |
115.000 |
For a row-based database, only one new row needs to be added. After that, the database view would look like this:
1, Sebastian, Controlling, 115000;
2, Patrick, Controlling, 110000;
3, Dirk, IT, 110000;
4, Steffen, IT, 115000;
With a column-based database, on the other hand, all four rows would have to be adjusted. After that, the database would have the following content:
1, 2, 3, 4;
Sebastian, Patrick, Dirk, Steffen;
Controlling, Controlling, IT, IT;
115000, 110000, 110000, 115000;
As you can guess, it takes longer than the row-based database. While the column-based databases score high in reading the data, the row-based databases are faster when updating the data. This is the reason why in the past the analytical systems, such as SAP Business Warehouse, tended to use column-based databases. The transactional systems, such as SAP ERP, on the other hand, ran on row-based databases. Thus, a segmentation according to application type took place.
An SAP HANA database combines the best of both worlds: information can be read column-by-column in the blink of an eye and new data can be added row-by-row just as quickly.
Compression
In addition to column and row access, the built-in compression mechanism also helps to increase the performance of a HANA database. This is because the information within a database is often repeated. For example, there are only just under 200 countries in the entire world, in Germany there are 16 federal states, and in a client-dependent database table there is often only one client. Therefore, in a database with millions of data records, the same characteristics occur several times.
For instance, let's look at our table. The controlling department appears twice in the data, as does the IT department.
|
ID |
Name |
Department |
Salary |
|
1 |
Sebastian |
Controlling |
115.000 |
|
2 |
Patrick |
Controlling |
110.000 |
|
3 |
Dirk |
IT |
110.000 |
|
4 |
Steffen |
IT |
115.000 |
If you were to simply write
2x Controlling, 2x IT;
instead of
Controlling, Controlling, IT, IT;
at the database level, you could reduce memory requirements enormously. Think, for example, of the gender characteristic in a database with millions of records.
Encoding
Coding is another approach to increase performance. For example, the characteristic Controlling in the column Department is replaced by an integer number. In this way, the same information can be stored in a much more space-saving manner than in an ordinary database, which further increases performance. Our example table could look like this.
|
ID |
Name |
Department |
Salary |
|
1 |
1 |
1 |
1 |
|
2 |
2 |
1 |
2 |
|
3 |
3 |
2 |
2 |
|
4 |
4 |
2 |
1 |
Partitioning
In addition, the information stored in a SAP HANA database is processed in parallel by several CPUs, whereby the cache is also used. This way, the last piece of performance can also be tickled out.
Insert Only
We expect from a database that a SELECT statement returns only the records valid at the time of the query. If a data record is being changed during the call, but the change has not yet been saved, the last valid status should be returned.Therefore, the original value must be stored somewhere temporarily.
Whenever a record is overwritten, the old state is copied to the rollback segment of the database. This approach has its price. Even a simple update requires two operations - the actual change and backup of the original version.
A different approach was chosen for a SAP HANA database. Instead of overwriting old records, new ones are added with a timestamp. During a query, only the new data records are read and displayed. This way, write operations can be performed more quickly. To prevent the database from growing indefinitely, the different versions of the data are consolidated during delta merge.
SAP HANA database - Our conclusion
In themselves, the individual components of HANA do not represent a groundbreaking innovation. What makes SAP HANA so special is the combination of individual components. This maximizes the advantages and minimizes the disadvantages at the same time. One disadvantage remains, however: by using a HANA database, you are tied to SAP and can no longer use third-party databases such as Oracle. But the advantages clearly outweigh the disadvantages, because no other provider has a comparable product in their portfolio. Would you like to learn more about SAP HANA and the possible applications in the business warehouse environment? We will gladly support you! Contact us now.

