/Logo%202023%20final%20dunkelgrau.png?width=221&height=97&name=Logo%202023%20final%20dunkelgrau.png)























Ohne Zweifel, unser Alltag ist zunehmend datengetrieben und die Menge der Daten nimmt mit jedem Tag kontinuierlich zu. So wächst täglich die Datenmenge, die in Unternehmen über alle Bereiche hinweg erzeugt und verarbeitet werden. Bei diesem exponentiellen Datenwachstum spielt die Performance eines Business Warehouses eine besondere Rolle.
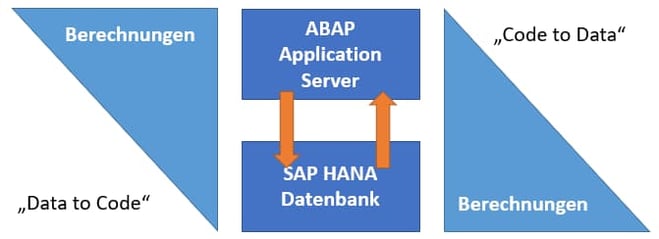
Eine Möglichkeit, die Performance Ihres Business Warehouses zu steigern ist SQLScript. Vor allem, wenn Sie viele kundeneigene Logiken einsetzen, kann SQLScript in SAP HANA hinsichtlich Performance helfen. Denn mit Hilfe von SQLScript können datenintensive Berechnungen auf der Ebene der Datenbank erfolgen. Was zu einem Paradigmenwechsel führt - statt die Daten von der Datenbank auf den ABAP-Server zu laden, um die Berechnungen dort auszuführen (“Data to Code” Paradigma) wird die Berechnung nun direkt in der SAP HANA Datenbank, also “Code to Data” durchgeführt.
Dabei bietet SQLScript einen größeren Funktionsumfang als SQL und erlaubt auch Programm- und Ablaufsteuerung. Somit ist es möglich, die Performance Ihrer SAP HANA Datenbank zu verbessern, ohne sich dabei auf die Open SQL Funktionen einzuschränken. Denn HANA stellt an sich eine sehr smarte Datenbank dar. Nachfolgend gehe ich auf Bestandteile von HANA ein, die diese so besonders machen.
SAP HANA ist vor allem als eine In-Memory Datenbank bekannt. Statt der Festplatte wird der Arbeitsspeicher des Computers für die Aufbewahrung der Daten genutzt, was einen wesentlich schnelleren Zugriff ermöglicht. So können selbst große Datenmengen performant verarbeitet werden.
Allerdings liegt der Kern der HANA Technologie nicht in einer massiven Arbeitsspeicherleistung, sondern in der neuartigen Datenbankarchitektur. Die hohe Performance wird erst durch die Kombination von vier bereits bekannten Technologien ermöglicht: Lesen und Schreiben sowohl im Zeilen- als auch im Spaltenformat, Kompression, Kodierung sowie Insert-Only Prinzip. In den nächsten Kapiteln erkläre ich diese Komponenten ausführlich.
Zeilen- und Spaltenformat unter einen Hut gebracht
Die HANA Datenbank kann sowohl im Zeilen- als auch im Spaltenformat arbeiten. Während das Spaltenformat schnelle Lesezugriffe ermöglicht, ist das Zeilenformat bei den Schreiboperationen performanter.
Nachfolgend erläutere ich den jeweiligen Ansatz anhand eines Beispiels. Betrachten wir die dargestellte Tabelle:
|
ID |
Name |
Abteilung |
Gehalt |
|
1 |
Sebastian |
Controlling |
115.000 |
|
2 |
Patrick |
Controlling |
110.000 |
|
3 |
Dirk |
IT |
110.000 |
Diese Tabelle dient allerdings nur der Darstellung. Faktisch werden die Informationen in einer anderen Form in der Datenbank gespeichert. So könnte der Inhalt der oben dargestellten Tabelle in einer zeilenbasierten Datenbank wie folgt abgelegt werden:
1, Sebastian, Controlling, 115000;
2, Patrick, Controlling, 110000;
3, Dirk, IT, 110000;
In einer spaltenbasierten Datenbank würde dieselbe Tabelle so aussehen:
1, 2, 3;
Sebastian, Patrick, Dirk;
Controlling, Controlling, IT;
115000, 110000, 110000;
Der spaltenbasierte Ansatz führt zu folgenden Vorteilen: Falls Sie zum Beispiel die Gehälter auswerten und die Summe aller Gehälter sehen möchten, benötigt die spaltenbasierte Datenbank nur einen Lesezugriff. So muss nur die letzte Zeile mit den Gehältern gelesen werden.
Eine zeilenbasierte Datenbank müsste dagegen alle Zeilen durchgehen und die Gehaltsinformationen auslesen. In unserem Beispiel würde es drei Lesezugriffen entsprechen, was länger dauert. Dreimal so lang, wie beim spaltenbasierten Ansatz.
Steigern Sie die Leistung Ihres BW mit SQLScript

Genauso verhält es sich, wenn Sie die Gesamtzahl der Mitarbeiter auswerten möchten. Während eine spaltenbasierte Datenbank mit einem Lesezugriff auskommt, benötigt die zeilenbasierte Datenbank drei Zugriffe.
Die spaltenbasierten Datenbanken haben jedoch einen entscheidenden Nachteil. Nehmen wir an, dass unser Unternehmen einen weiteren Mitarbeiter anstellt, sodass unsere Tabelle wie folgt aussieht:
|
ID |
Name |
Abteilung |
Gehalt |
|
1 |
Sebastian |
Controlling |
115.000 |
|
2 |
Patrick |
Controlling |
110.000 |
|
3 |
Dirk |
IT |
110.000 |
|
4 |
Steffen |
IT |
115.000 |
Bei einer zeilenbasierten Datenbank muss nur eine neue Zeile hinzugefügt werden. Anschließend würde die Datenbanksicht wie folgt aussehen:
1, Sebastian, Controlling, 115000;
2, Patrick, Controlling, 110000;
3, Dirk, IT, 110000;
4, Steffen, IT, 115000;
Bei einer spaltenbasierten Datenbank müssten hingegen alle vier Zeilen angepasst werden. Danach würde die Datenbank den folgenden Inhalt aufweisen:
1, 2, 3, 4;
Sebastian, Patrick, Dirk, Steffen;
Controlling, Controlling, IT, IT;
115000, 110000, 110000, 115000;
Wie Sie sich denken können, dauert es länger als bei der zeilenbasierten Datenbank. Während die spaltenbasierten Datenbanken beim Lesen der Daten punkten, sind die zeilenbasierten beim Fortschreiben der Daten schneller. Das ist der Grund warum früher die analytischen Systeme, wie z.B. SAP Business Warehouse, eher mit spaltenbasierten Datenbanken arbeitetet. Die transaktionalen Systeme, wie z.B. SAP ERP, liefen dagegen auf zeilenbasierten Datenbanken. Es fand also eine Unterteilung nach Anwendungsart statt.
Eine SAP HANA Datenbank vereint das Beste aus zwei Welten: die Informationen können im Handumdrehen spaltenweise gelesen und genauso schnell können neue Daten zeilenweise hinzugefügt werden.
Kompression
Neben dem Spalten- und Zeilenzugriff hilft auch der eingebaute Kompressionsmechanismus dabei, die Performance einer HANA Datenbank zu steigern. Denn die Informationen innerhalb einer Datenbank wiederholen sich häufig. So gibt es auf der ganzen Welt nur knapp 200 Länder, in Deutschland gibt es 16 Bundesländer und in einer mandantenabhängigen Datenbanktabelle häufig nur einen Mandant. In einer Datenbank mit Millionen von Datensätzen kommen daher dieselben Ausprägungen mehrfach vor.
Betrachten wir zum Beispiel unsere Tabelle. Die Controlling Abteilung kommt in den Daten zweimal vor, genauso wie die IT-Abteilung.
|
ID |
Name |
Abteilung |
Gehalt |
|
1 |
Sebastian |
Controlling |
115.000 |
|
2 |
Patrick |
Controlling |
110.000 |
|
3 |
Dirk |
IT |
110.000 |
|
4 |
Steffen |
IT |
115.000 |
Wenn man auf der Datenbankebene statt
2x Controlling, 2x IT;
einfach
Controlling, Controlling, IT, IT;
schreiben würde, könnte man den Speicherbedarf enorm senken. Denken Sie zum Beispiel an das Merkmal Geschlecht in einer Datenbank mit Millionen von Datensätzen.
Codierung
Ein weiterer Ansatz, die Performance zu steigern, ist die Codierung. So wird zum Beispiel die Ausprägung Controlling in der Spalte Abteilung durch eine ganze Zahl ersetzt. Auf diese Weise lassen sich dieselben Informationen viel platzsparender ablegen als in einer gewöhnlichen Datenbank, womit die Performance weiter gesteigert wird. Unsere Beispieltabelle könnte dabei wie folgt aussehen.
|
ID |
Name |
Abteilung |
Gehalt |
|
1 |
1 |
1 |
1 |
|
2 |
2 |
1 |
2 |
|
3 |
3 |
2 |
2 |
|
4 |
4 |
2 |
1 |
Partitionierung
Darüber hinaus werden in einer SAP HANA Datenbank die gespeicherten Informationen durch mehrere CPUs parallel verarbeitet, wobei auch der Cache zum Einsatz kommt. So kann auch das letzte Stück Performance herausgekitzelt werden.
Insert Only
Wir erwarten von einer Datenbank, dass ein SELECT Statement nur die zur Zeit des Aufrufes gültige Datensätze liefert. Wenn ein Datensatz während des Aufrufes gerade geändert wird, aber die Änderung noch nicht gespeichert wurde, soll der zuletzt gültige Stand aufgerufen werden. Daher muss der alte Wert irgendwo zwischengespeichert werden.
Wann immer ein Datensatz überschrieben wird, wird der alte Stand in das Rollback Segment der Datenbank kopiert. Dieser Ansatz hat seinen Preis. Selbst bei einem einfachen Update sind zwei Operationen notwendig - die eigentliche Änderung und Backup des alten Standes.
Bei einer SAP HANA Datenbank wurde ein anderer Ansatz gewählt. Anstatt alte Datensätze zu überschreiben, werden neue hinzugefügt und mit einem Zeitstempel versehen. Bei einer Abfrage werden nur die neuen Datensätze gelesen und ausgegeben. So können Schreiboperationen schneller ausgeführt werden. Damit die Datenbank nicht unendlich wächst, werden die verschiedenen Versionen der Daten beim Delta Merge konsolidiert.
SAP HANA Datenbank - Unser Fazit
An sich stellen die einzelnen Komponenten keine bahnbrechenden Neuerungen dar. Was SAP HANA so besonders macht, ist die Kombinationen der einzelnen Komponenten. So werden gleichzeitig die Vorteile maximiert und Nachteile minimiert. Ein Nachteil bleibt allerdings: durch den Einsatz einer HANA Datenbank ist man an SAP gebunden und kann nicht mehr Datenbanken der Drittanbieter wie Oracle nutzen. Aber die Vorteile überwiegen unverkennbar, denn kein anderer Anbieter hat ein vergleichbares Produkt im Portfolio. Möchten Sie mehr über SAP HANA und die Einsatzmöglichkeiten im Business Warehouse Umfeld erfahren? Wir unterstützen Sie gerne! Kontaktieren Sie uns jetzt.


