/Logo%202023%20final%20dunkelgrau.png?width=221&height=97&name=Logo%202023%20final%20dunkelgrau.png)























ETL - This acronym describes like no other the immense effort that has had to be made everywhere since the emergence of data warehouses and business intelligence in order to transfer data from their source systems to the analysis system. Extract, Transform, Load are the eponymous logical steps of such processes, which have long been thought of and implemented in this order. In recent years, however, the trend has shifted towards the apparently only slightly modified paradigm of "ELT", Extract, Load, Transform. What is behind this, what advantages does the new approach promise and how can Apache Airflow enable ELT mechanisms for your data processing? We want to answer these questions today.
ETL and ELT - what's the difference?
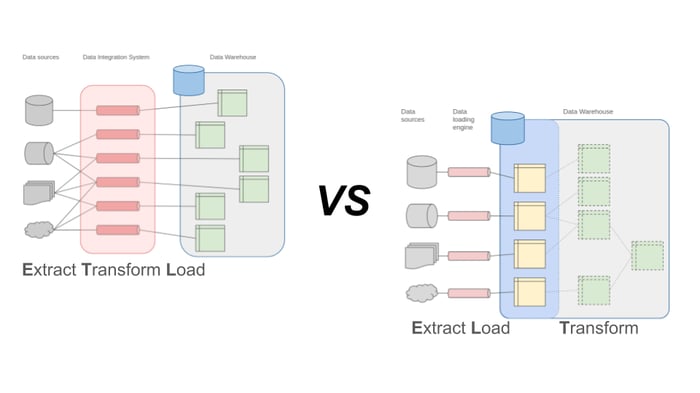
Classic data pipelines, often referred to directly as "ETL pipelines", are designed to link a data source with a target system and create the exact target format required during the transport process. Entire data integration platforms and system landscapes have evolved around this simple principle over the years and have established themselves as the connecting element between operational systems and analytical data warehouses in many companies. With the growing number of source systems and new requirements for the analytical use of data, the number of ETL processes required is increasing exponentially: different target formats have to be generated for each data source and the complexity of the overall system is exploding. As the processing is carried out in a dedicated system component, corresponding resources must be reserved for this (CPU and RAM). These requirements are usually very high for short load peaks, but lie idle for a large part of the time. Data processing according to the ETL scheme therefore becomes an expensive, inefficient bottleneck from both a technical and organizational perspective.
The paradigm shift to the ELT schema is based on a shift in the transformation logic through to the complete virtualisation of this step. Data is first transferred from each data source to a standardized storage system on the analysis platform before the various transformations required are carried out on this platform. In its simplest form, this means, for example, that source data is written to a logical zone of the warehouse database in an unadjusted way and then processed and utilized for various analysis purposes via views within this database. In the cloud or a data lake or lakehouse architecture, the raw data ends up in favorable object storage before it is processed further. The complexity of the source-sink connections can therefore be reduced to a linear mapping, at least for the first phase. By shifting the resource-hungry transformation steps to an existing, high-performance system such as a database or cloud platform, this bottleneck is also resolved.
![]() ELT processes in the data warehouse
ELT processes in the data warehouse
The ELT approach is not entirely new and has long been conceptually supported in large data warehouse platforms and enterprise databases with corresponding tools. The ELT paradigm has gained momentum in recent years, particularly with the development of new tools for the standardized management of data models: Led by dbt, these tools establish a standardized interface for automatic or virtual transformations of data once it has been loaded into the warehouse. In this way, efficiency and order are to be brought to the complex mappings in the data warehouse.
Apache Airflow is the pioneer of modern open source workflow management platforms and has played an important role in the further development and optimisation of data engineering processes in recent years. In Airflow, workflows are defined as Python code. For this reason, the system can be used for practically any purpose and can be expanded as required, while the processes are traceable at all times thanks to a strong link to mature best practices from software development. Thanks to its scalable and fail-safe system architecture, Airflow is a very robust and reliable orchestration tool for time-controlled and automated processes. As an open source platform, Airflow can be used for a wide range of tasks and offers very good control options, especially for complex data streams.
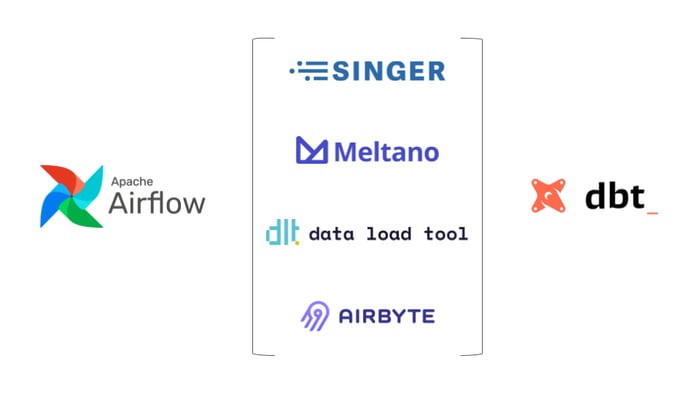
In the ELT paradigm, the initial loading of data into a storage system and the transformation to a required format are therefore decoupled. However, sequential linking and reliable execution of the individual steps is still required. The combination of ELT tools with Apache Airflow obviously makes sense here. Let's take a closer look at what this integration can look like using the following representatives of this class of tools as examples: Singer, Meltano, Airbyte and DLT.
Apache Airflow as the basis for ELT process landscapes
Modern ELT tools generally come with their own execution and workflow environments to a certain extent. However, these components are not their proven area of expertise, meaning that integration with a standalone orchestrator is often suggested. The type of integration with Apache Airflow is often similar: the tools allow the definition of loading processes from supported source systems into specific target systems via configuration parameters. The execution of such a load route is then usually triggered via a command line interface (CLI). Alternatively, they offer a fully-fledged graphical user interface and REST-based programming interfaces.
Singer
Singer is one of the pioneers in the field of ELT tools and the open source framework behind the cloud service provider Stitch. Singer defines a JSON-based format for the exchange of data between any sources ("taps") and sinks ("targets"), provided that corresponding interfaces exist. The implemented taps and targets as well as the Singer framework are Python code and can be installed via the package management PyPI. A loading route is then configured via CLI commands and YAML files. The execution of a loading route can again be started via CLI. To set up an Apache Airflow ELT infrastructure with Singer, the generated configuration files must be made available to Airflow in corresponding directories and executed via the Singer CLI using BashOperator.
Optimize your workflow management
with Apache Airflow!

Meltano
Meltano is another open source project that has utilized the Singer specification of taps and targets to achieve even more comprehensive coverage in terms of supported sources and sinks. Meltano also largely follows the same conceptual structure and provides for the definition of load paths via its own CLI. If the associated cloud product is not used, Meltano pipelines can also be executed with an ad-hoc Airflow scheduler or orchestrated directly via CLI with an existing Apache Airflow instance. In fact, this is also done by providing configuration files in corresponding folders. Meltano allows you to create Airflow-compatible Python definitions for load paths via CLI. Alternatively, a route can also be triggered directly via the Meltano CLI using the Airflow BashOperator or this process can be executed in a specially created Docker container.
DLT
Structurally very similar, but developed on a completely independent Python code base, the DLT project is currently establishing itself as another aspirant on the ELT tool market. DLT stands for "data load tool" and also describes the primary goal: generic loading of data from various sources without any great ambition to operate as a platform itself. DLT also works with its own CLI, which is used to configure the source and sink. The method of transmission can then be granularly configured and executed in Python code. However, to control a DLT pipeline with Airflow, the working directory including configuration files must also be synchronized and triggered via CLI or Python command.
Airbyte
The Airbyte project takes a slightly different approach, which also comes in its open source edition as a fully-fledged platform with a sophisticated user interface. Here, pipelines are compiled via configuration forms in the browser, can be executed with a click and granular log and metadata can be viewed. Airbyte comes with an in-built scheduling system for simple time-controlled sequences as well as a REST API with all control commands. This API is also used for integration with Airflow, and there is even a dedicated Airbyte operator available. Airbyte load sequences can therefore be natively integrated into workflows, started and their success tracked via asynchronous status monitoring in Airflow.
ELT without additional tools?
The tools presented all focus on the initial loading of data into a warehouse infrastructure. All common relational database management systems are generally supported as sinks, most notably the popular cloud data warehouses or data lake storage systems. Singer, Meltano, DLT and Airbyte offer a standardized declarative language for this purpose and enable the definition and operation of a large number of data streams with relatively little effort.
A pure Python library with this purpose, which can be used completely without its own CLI and can therefore be integrated completely natively into an Apache Airflow ELT concept, has unfortunately not yet been established.
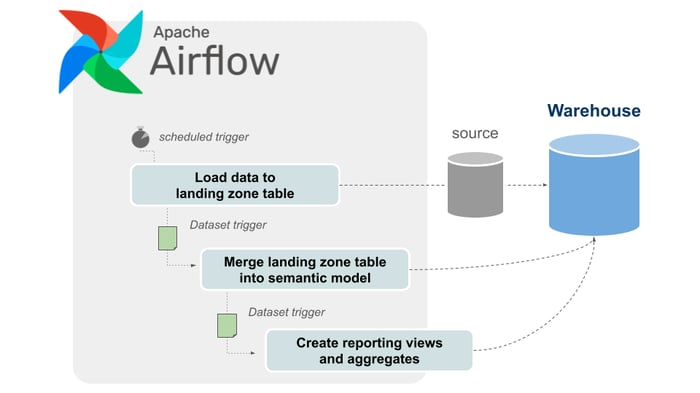
In order to enjoy the benefits of the ELT paradigm, no dedicated tool is required. Especially for in-house warehouse architectures that connect a limited number of data sources, pure Python code with Airflow as the development framework can be an efficient alternative as our examples of SAP data extractions have shown. Following the loading process, the corresponding transformations can also be executed natively with Airflow using pure SQL templates, without the need to use a dedicated tool such as dbt. Multi-dimensional dependencies between loading routes and transformations can be precisely defined using Airflow Datasets. When it comes to monitoring data streams down to the processed data points themselves, however, dedicated ELT tools are inherently better positioned, and Airflow leaves some room for maneuver in terms of design.
Apache Airflow ELT Process - Our Conclusion
In today's brief overview, we have highlighted the advantages of ELT processes and presented some representatives of the current generation of ELT tools and their possible combinations with Apache Airflow. Of course, the topic has many more facets and practically unlimited technological diversity. Ultimately, it is important to make the right choice of data warehouse architecture and tools in order to solve specific challenges. The decision in favor of a certain architecture, the tools used and the development processes are always specific to a use case and should be examined with a sense of proportion. While new cloud platforms are constantly coming onto the market in line with technological trends, a direction can quickly be taken that misses the actual needs of an organization.
We would be happy to discuss with you the possibilities of designing and operating ELT processes with Apache Airflow or to shed light on your data processing and analysis challenges in general. Simply get in touch with us - we look forward to exchanging ideas with you!

