/Logo%202023%20final%20dunkelgrau.png?width=221&height=97&name=Logo%202023%20final%20dunkelgrau.png)























Digital transformation is a major success factor for companies and the ability to derive valuable insights from an abundance of data generated is a key competitive advantage. As more and more data becomes available for statistical analysis and prediction of business critical metrics, the demand for compute resources to process these data in time increases. Cloud services advertise seamless and infinite scaling of resources and Kubernetes or Apache Spark clusters are well-known examples.
But what if your team needs the same functionality on a smaller scale? If the data that needs to be processed cannot be accessed from distributed compute clusters in the cloud or must be kept on-premises for compliance reasons? Adding a high-end compute cluster to a company’s infrastructure is not done overnight and might not always be viable. Apache Airflow presents itself as a viable middle-ground solution for companies, data teams, or even single projects because it natively supports horizontal scaling of processing tasks.
The Apache Airflow Celery Executor Architecture
Apache Airflow is the leading open source workflow orchestration and scheduling platform that combines the Python programming language, a scalable microservices architecture, and configuration-as-code principles. Any digital workflow can be implemented and integrated using the Airflow framework. It is used to control data flows and process flows like clockwork for hundreds of companies all over the world. Today, we look at what is effectively a byproduct of the scalability built into the Apache Airflow Celery Executor architecture: the possibility to use Airflow as a distributed, horizontally scalable processing framework.
Airflow basically consists of a scheduling service and a task execution engine. The scheduler interprets workflow definitions and queues them for execution if all preconditions are met (scheduled time has come and all upstream tasks have completed). The execution engine handles the actual process logic. Airflow can be deployed with multiple execution engines for different purposes or depending on the available infrastructure components. The most scalable execution engine is itself based on Kubernetes and thus shares some of the higher up-front investment described above. The more lightweight alternative is based on the Celery distributed task queue framework which offers a valuable compromise between infrastructural requirements and scalability. The Celery executor is the basis of the use case we discuss today.
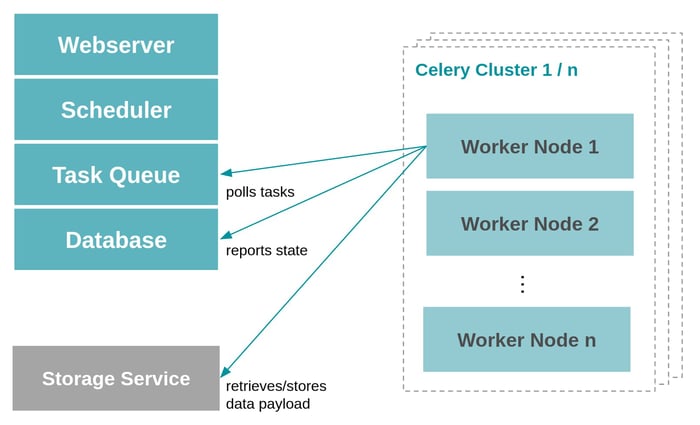
A simplified architectural view of Apache Airflow components: decentralized worker nodes need to contact central task queue service and the Airflow database to poll available tasks and to report task execution state back. Actual data payload needs to be managed by a remote storage service.
Celery itself is a Python module and can be run independently from Airflow to horizontally scale processing tasks. One important design aspect of Celery is that the worker nodes can join a compute cluster at any point in time without any need to update the central configuration. Any worker node that can reach the Celery task queue and results collection services can start adopting queued tasks and handle the processing whenever they have processing slots open. An Airflow system based on the Celery Executor can leverage this to seamlessly add more processing capacity to its task execution engine when required. While this lowers the barrier to scalable computing, it does not automate the scaling as well as a Kubernetes cluster. Some challenges will need to be resolved for the specific system and infrastructure: Where do the actual compute resources come from and how are they notified of the need to extend processing capacity dynamically?
Optimize your workflow management
with Apache Airflow!

Workflows defined to be run by Airflow are called directed acyclic graphs (DAGs), and define a set of tasks, their order of execution, and metadata to be passed between tasks. Because the DAG definition syntax is fully based on the Python programming language, DAG developers have always been able to create workflows that scale tasks dynamically at runtime with a bit of elbow grease. Since the release of Airflow v2.3 last year, the system natively supports dynamic task scaling within the process flow logic. Considering our use case of CPU-intensive data analysis, this means the source data can be dynamically split into smaller chunks, which can be processed independently by as many copies of the analysis tasks as there are chunks. Airflow provides the framework to split chunk processing out across tasks which will then be handed over to the Airflow task execution engine. If we can now provide more processing capacity to the task execution engine when such a large set of CPU-intensive tasks are queued up, we have achieved our goal.
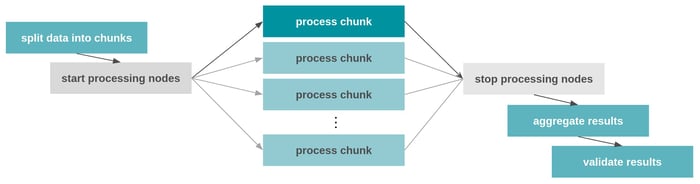
Schema of an Airflow DAG that splits an input dataset into chunks and processes these in parallel tasks.
Grey workflow nodes imply that the actual compute resource can be scaled on-demand before and after the mapped processing tasks are triggered.
Scaling Compute Power with Airflow: Practical Challenges
Using Airflow as a distributed compute engine has certainly not been the primary objective of its developers so to make our use case work, some of the default configuration parameters of the system have to be adjusted. First of all, the number of tasks that Airflow queues up for execution is limited by default to not overload the execution engine. Furthermore, the number of actively processed tasks per DAG is limited by default. To allow significantly higher task scaling, the Airflow parameters parallelism and max_active_tasks_per_dag need to be increased from their default values of 32 and 16 respectively. How many tasks can actually be processed in parallel is limited by the number of available worker nodes and their respective capacity to adopt tasks.
The second dimension of worker scaling in a Celery-based Airflow environment is the number of running worker nodes. If you set up Airflow with the basic Docker-Compose templates, a single worker node is available to the system. Using the Compose Container replication interface, this number can be easily increased. Obviously, simply increasing the number of worker nodes on a single Docker host server is still limited by the resources available to that server. True horizontal scaling comes from spreading out worker nodes across multiple hosts to add more resources to the base system. As described above, new worker nodes only need to be able to communicate with the Airflow task queue service and its metadata database. For remote workers to properly communicate task logs with Airflow, they have to be configured to share logs through a built-in web service which must be accessible to the main Airflow server. Last but not least, DAG definition files and Python modules must be kept in sync between all Airflow components, which can be achieved by including these into custom Airflow Docker images or automatically pulling latest versions from a Git repository. In our experience, how to best set this up varies heavily depending on the existing infrastructure and system context.
Once you have figured out how to integrate the (remote) worker nodes into the Airflow environment, the number of parallel threads each Celery worker node handles is the final parameter to tune. Airflow wraps these settings into the parameters worker_concurrency and worker_autoscale. The latter enables each worker to start up additional CPU threads dynamically if the task queue is full and effectively overrides the former parameter. When tuning the different worker scaling dimensions, keep in mind that the number of actual CPU units available present a limit on how many tasks can be processed in parallel. Increasing the number of parallel tasks over the number of CPU cores will introduce context switching overhead in the lower layers of the operating system and hardware.
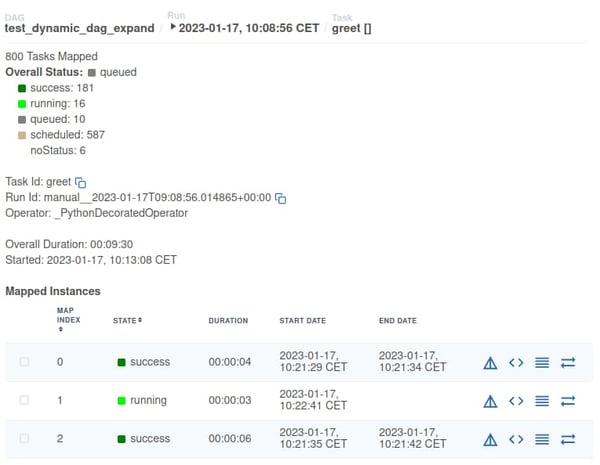
Screenshot from the Apache Airflow 2.5 user interface showing information about dynamically mapped tasks in a DAG.
In this case, 800 data chunks have been scheduled for execution, 16 of which can be seen to be in “running” state.
Constraints and Possibilities
The application scenario discussed here is rather specific in that it assumes a set of constraints: that highly scalable infrastructure like a Kubernetes cluster, Databricks, or Apache Spark ecosystem are not available to the team; that running Airflow with or without Docker is a feasible option; that scaling of compute resources or more specifically virtual servers is possible, maybe even possible to automate via some API. Finally, the data analysis task to perform must contain process logic which allows a classic divide and conquer approach where chunks can be independently processed and results aggregated.
From project experience and discussions with our customers we know that such constraints are quite common and might require creative solutions that can be implemented in a short period of time. Using the Apache Airflow Celery Executor as we described here can be such a short- to mid-term solution when results must be achieved before a strategic infrastructure or cloud migration project can be launched.
We only scratched the surface of how to make use of the Apache Airflow Celery Executor engine for parallel computation. More advanced scenarios are possible as well: Integrating the API-triggered scaling or startup of compute resources as part of the DAG flow itself or managing multiple compute clusters by leveraging multiple Celery worker queues. All these possibilities share the usual disclaimer that complexity may be shifted from the responsibility of individual developers or teams into the system but it does not magically disappear. In-depth knowledge of Airflow, Celery, microservices, distributed systems and computer networking are required to test, deploy, and optimize such intricate systems.
Has your organization or team faced similar challenges or do you need someone to discuss architectural choices regarding scalable compute frameworks? You are welcome to schedule an initial discussion with our NextLytics Data Science and Engineering team. We’re curious to learn about your use cases and support you in finding solutions that fit your specific needs and system context.

