/Logo%202023%20final%20dunkelgrau.png?width=221&height=97&name=Logo%202023%20final%20dunkelgrau.png)























When working with business data, it’s not uncommon to find columns that store multiple values in a single field, often separated by commas.
For example, an account may have multiple classifications (A1,A2,A3), or a sales order might include several product codes (P01,P02,P03) within the same record.
While this approach might simplify the source system’s structure, it makes analytics more complex, because most reporting or modeling tools prefer normalized data, where each value appears in its own row.
In SAP Datasphere (and SAP HANA), this type of transformation can be done efficiently without using loops, thanks to SQLScript built-in functions like SERIES_GENERATE_INTEGER and OCCURRENCES_REGEXPR.
In this article, we’ll explore a real-world use case and walk through a SQLScript that cleanly and dynamically splits comma-separated lists into multiple rows.
The Business Use Case
Imagine getting data from multiple systems where account codes or classifications come packed into one string. We’ll unpack this typical scenario and understand why separating values into distinct rows is essential for clean data models.
Let’s say your company collects data from various financial systems, and one of them provides an Account field like this:
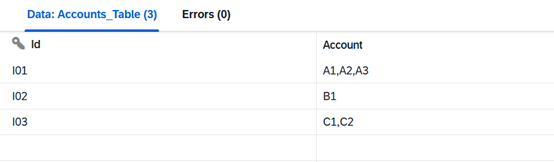
This structure causes issues when:
- You need to join with a master data table on individual account codes.
- You want to aggregate or filter based on each specific account.
- Or you’re building a data model that feeds into SAP Analytics Cloud and requires atomic values.
The goal is to transform each comma-separated list into separate rows like this:
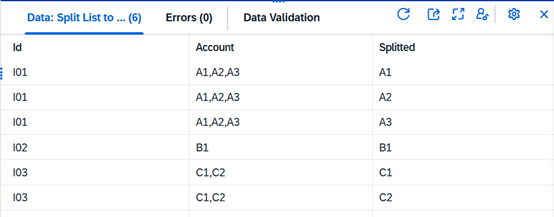
Watch the recording of our webinar:
"SAP Datasphere and the Databricks Lakehouse Approach"

The Core Challenge - The Set-Based Way to Split Lists
Loops may sound like a quick fix and you might be tempted to solve this with a loop or procedural logic, iterating through each record, counting commas, and slicing text.
But in SQL-based engines like SAP Datasphere, loops are inefficient and break the idea of set-based processing.
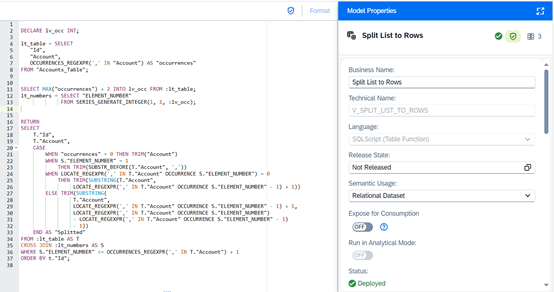
The code snippet below provides a fully set-based solution. It uses only SQLScript functions to detect how many elements exist in each list, to dynamically generate the required number of rows and extract each substring corresponding to its position.

The SQLScript Explained
Let’s break it down step by step.
Step 1: Identify the Maximum Number of Commas
Count the Commas in Each Row. Start by finding out how many elements each list holds. With OCCURRENCES_REGEXPR, you can easily detect the number of commas — and therefore, how many new rows you’ll need to create.
lt_table = SELECT
"Id",
"Account",
OCCURRENCES_REGEXPR(',' IN "Account") AS "occurrences"
FROM "Accounts_Table";
This part creates a local table that scans through the chosen column (“Account” for this example) and counts the number of commas in each row using OCCURRENCES_REGEXPR.
If a row has A1,A2,A3 the result is 2 (two commas).
We’ll later use this information to determine how many rows to generate.
Step 2: Generate a Dynamic Row Series
Instead of hard-coding anything, create a flexible number series using SERIES_GENERATE_INTEGER. This ensures your transformation can handle any list length automatically.
DECLARE lv_occ INT;
SELECT MAX("occurrences") + 2 INTO lv_occ FROM :lt_table;
lt_numbers = SELECT "ELEMENT_NUMBER"
FROM SERIES_GENERATE_INTEGER(1, 1, :lv_occ);
Here, SERIES_GENERATE_INTEGER creates a virtual table of integers (1, 2, 3, … n),
where n is based on the maximum number of commas found + 2.
In order to use it dynamically, a variable is created (lv_occ) that holds the maximum occurrences +2 value.
Why +2?
Because if the maximum number of commas is 5, that means there are 6 actual values (5 commas + 1 element) and we add one more for an open-ended range.
This ensures we generate enough rows to cover all possible list elements.
Step 3: Cross Join and Split Dynamically
The magic happens here: here’s where the transformation happens. Using a CROSS JOIN and string functions like SUBSTR_BEFORE and LOCATE_REGEXPR, you can extract every value cleanly into its own row.
SELECT
T."Id",
T."Account",
CASE
WHEN "occurrences" = 0 THEN TRIM("Account")
WHEN S."ELEMENT_NUMBER" = 1
THEN TRIM(SUBSTR_BEFORE(T."Account", ','))
WHEN LOCATE_REGEXPR(',' IN T."Account" OCCURRENCE S."ELEMENT_NUMBER") = 0
THEN TRIM(SUBSTRING(T."Account",
LOCATE_REGEXPR(',' IN T."Account" OCCURRENCE S."ELEMENT_NUMBER" - 1) + 1))
ELSE TRIM(SUBSTRING(
T."Account",
LOCATE_REGEXPR(',' IN T."Account" OCCURRENCE S."ELEMENT_NUMBER" - 1) + 1,
LOCATE_REGEXPR(',' IN T."Account" OCCURRENCE S."ELEMENT_NUMBER")
- LOCATE_REGEXPR(',' IN T."Account" OCCURRENCE S."ELEMENT_NUMBER" - 1)
- 1))
END AS "Splitted"
FROM :lt_table AS T
CROSS JOIN :lt_numbers AS S
WHERE S."ELEMENT_NUMBER" <= OCCURRENCES_REGEXPR(',' IN T."Account") + 1;
In this part of code:
- The
CROSS JOINpairs each record with a number series (1, 2, 3...) — one for each possible element in the list.
For example, a record with 3 elements will get 3 matching rows. - Depending on the element number, the code uses
SUBSTR_BEFORE,SUBSTRING, andLOCATE_REGEXPRto extract the right part of the text between commas.
No loops or procedural iteration are used, just pure SQL text functions and dynamic row generation.
Making Sense of the CASE WHEN Logic
Now that we’ve seen how the script joins our data with a series of numbers, let’s take a closer look at the CASE WHEN block. Each condition in the CASE block has a purpose — from handling records without commas to correctly extracting the first, middle, and last elements. This is where the actual text splitting happens. Let’s simplify what happens behind each case.
Here’s the part of the CASE WHEN code again:
CASE
WHEN "occurrences" = 0 THEN TRIM("Account")
WHEN S."ELEMENT_NUMBER" = 1
THEN TRIM(SUBSTR_BEFORE(T."Account", ','))
WHEN LOCATE_REGEXPR(',' IN T."Account" OCCURRENCE S."ELEMENT_NUMBER") = 0
THEN TRIM(SUBSTRING(
T."Account",
LOCATE_REGEXPR(',' IN T."Account" OCCURRENCE S."ELEMENT_NUMBER" - 1) + 1
))
ELSE TRIM(SUBSTRING(
T."Account",
LOCATE_REGEXPR(',' IN T."Account" OCCURRENCE S."ELEMENT_NUMBER" - 1) + 1,
LOCATE_REGEXPR(',' IN T."Account" OCCURRENCE S."ELEMENT_NUMBER")
- LOCATE_REGEXPR(',' IN T."Account" OCCURRENCE S."ELEMENT_NUMBER" - 1)
- 1
))
END AS "Splitted"
At first glance, it looks complicated, but it’s actually just handling four different situations. Let’s break them down in plain language.
1. When there are no commas at all
No commas? Just keep the original value.
WHEN "occurrences" = 0 THEN TRIM("Account")
If the column doesn’t have any commas, there’s nothing to split.
The code simply returns the original value. The TRIM function is used here in order to remove any leading or trailing spaces.
Example:
B1 → B1
It’s a simple “do nothing” case that keeps single-value records intact.
2. The first element in the list
First item? Grab everything before the first comma.WHEN S."ELEMENT_NUMBER" = 1 THEN TRIM(SUBSTR_BEFORE(T."Account", ','))
When the element number is 1, we’re dealing with the first value in the list.
The SUBSTR_BEFORE function is used and simply takes everything before the first comma.
Example:
A1,A2,A3 → A1
This is usually the cleanest case since the function doesn’t have to calculate any positions.
3. The last element in the list
Last item? Take what comes after the last comma.
WHEN LOCATE_REGEXPR(',' IN T."Account" OCCURRENCE S."ELEMENT_NUMBER") = 0 THEN TRIM(SUBSTRING( T."Account", LOCATE_REGEXPR(',' IN T."Account" OCCURRENCE S."ELEMENT_NUMBER" - 1) + 1 ))
When there are no more commas left to find, it means we’ve reached the end of the string.
Here, the code looks for the position of the last comma, adds one, and takes everything after that point.
The OCCURRENCE part in the LOCATE_REGEXPR function is expecting an integer after it so that it knows in which occurrence time of the comma it looks for (e.g the 1st time it is found, the 2nd etc.). By using the “ELEMENT_NUMBER” column, the code looks dynamically for the occurrences of each row.
Example:
A1,A2,A3 → A3
So this case handles the tail end of each list.
4. Everything in between
Middle items? Extract what lies between commas.
ELSE TRIM(SUBSTRING( T."Account", LOCATE_REGEXPR(',' IN T."Account" OCCURRENCE S."ELEMENT_NUMBER" - 1) + 1, LOCATE_REGEXPR(',' IN T."Account" OCCURRENCE S."ELEMENT_NUMBER") - LOCATE_REGEXPR(',' IN T."Account" OCCURRENCE S."ELEMENT_NUMBER" - 1) - 1 ))
This one covers all the “middle” values, anything that isn’t the first or last element.
The idea is to find the comma before and the comma after the current value, then extract everything between them.
Example:
A1,A2,A3,A4 → A2, A3
The LOCATE_REGEXPR calls are just finding the positions of those commas so that SUBSTRING can pull out the right piece. The SUBSTRING function expects the text to take the substring for (“Account”), the position it should start from (1,2,3 etc.) and the number of characters to march forward( 1,2,3 etc.) as its parameters.
In this part, the position it should start from is the first occurrence of comma it finds + 1, so that the comma is not included in the text it extracts, and the length of characters to extract is dynamically created for each row using the next and previous comma occurrence position (therefore the subtraction part of the LOCATE_REGEXPR expressions).
Each rule ensures your data stays consistent and readable.
Putting It All Together in SAP Datasphere
Once you run the full SQLScript view, you’ll see each comma-separated list expanded into separate rows — ready for joins, aggregations, and analytics in SAP Datasphere or SAP Analytics Cloud.
Splitting Comma-Separated Lists into Rows with SQLScript: Our Conclusion
Comma-separated fields might seem like a harmless shortcut in source systems, but they quickly become a barrier to reliable analytics and scalable data models. With a few powerful SQL functions, you can elegantly transform complex string data into a clean, normalized format — all without loops or heavy scripting. The approach shown here runs efficiently in SAP Datasphere, making it ideal for large data volumes and near-real-time transformations.
If your data landscape still contains legacy patterns that slow down analytics, our team can help. We specialize in designing performant, cloud-ready data models, optimizing SQLScript transformations, and integrating SAP Datasphere seamlessly into your architecture.
Let’s discuss how you can modernize your data layer and unlock better reporting performance — get in touch with us for a short consulting session or hands-on use-cases.

