/Logo%202023%20final%20dunkelgrau.png?width=221&height=97&name=Logo%202023%20final%20dunkelgrau.png)























Modern data platforms need to be robust, secure and easy to scale across teams and environments. Many organizations are moving from isolated data solutions toward shared enterprise data platforms that serve multiple teams and use cases. In this context, Databricks often becomes the central platform for data engineering, analytics and AI workloads across DEV, QA and PROD environments.
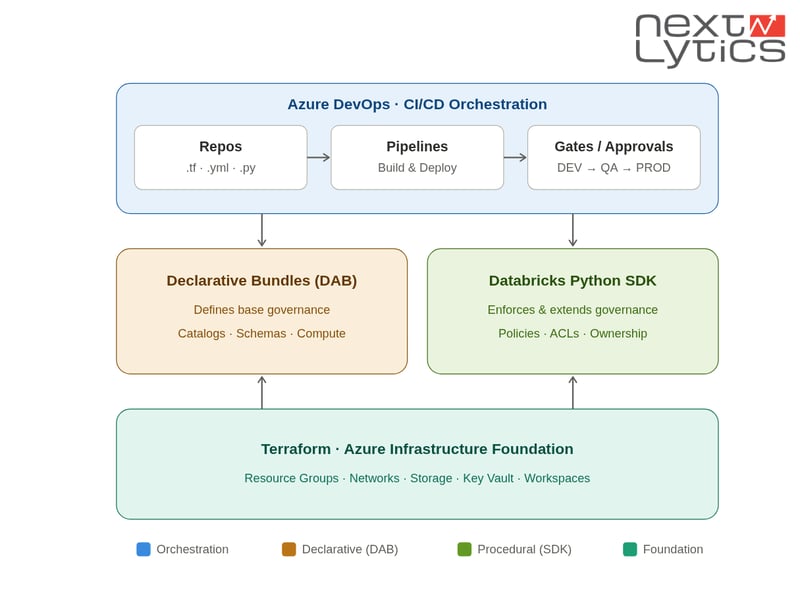
In this article we want to guide you through an automation approach for provisioning such a platform on Azure by combining three technologies:
-
Terraform for provisioning the Azure infrastructure foundation
- Databricks Declarative Automation Bundles (DAB), formerly known as Databricks Asset Bundles, for deploying Databricks-native resources and Unity Catalog governance definitions
- Databricks Python SDK for procedural governance tasks that cannot be expressed fully declaratively
The business use case is a multi-environment Databricks platform where infrastructure, governance and workload deployment need to be standardized without mixing responsibilities. Platform teams need to provision secure workspaces, storage, identities and networking. Data teams need consistent catalogs, schemas, permissions, jobs and views. Security and governance teams need clear ownership, repeatable deployment processes and reduced manual configuration.
The core idea is to separate these concerns deliberately:
-
Terraform provisions the Azure platform foundation
-
Databricks Bundles define Databricks-native resources and governance
- The Databricks SDK fills the automation gaps where declarative configuration is not enough
This separation keeps the platform maintainable and avoids the common anti-pattern of forcing all Databricks automation into one tool simply because it is technically possible.
Part I: Provisioning Azure Databricks Infrastructure with Terraform
The first layer of a production-ready Azure Databricks platform is not the workspace configuration itself, but the cloud infrastructure it depends on. Networking, identity, storage, security boundaries and workspace provisioning need to be defined in a reproducible way before higher-level Databricks resources are introduced.
This is where Terraform provides the foundation. It manages the Azure infrastructure layer that Databricks relies on, including resource groups, virtual networks, subnets, storage accounts, managed identities, access connectors, Key Vault integration, private endpoints and the Azure Databricks workspaces themselves.
Only after this infrastructure layer is in place does it make sense to move into Databricks-native concerns such as governance, jobs, pipelines, Unity Catalog objects and permissions.
In simple terms:
Terraform builds the platform.
Databricks Bundles configure what runs on top of it.
There are multiple valid ways to automate the deployment of an Azure Databricks platform. In this article, we separate the relatively stable Azure infrastructure foundation from the more dynamic Databricks configuration layer.
This structure fits a multi-environment setup with several workspaces and governance requirements. It also allows Terraform state to track the provisioned infrastructure explicitly, making changes easier to review, reproduce and promote across environments.
Terraform as the Infrastructure Foundation
In an Azure Databricks architecture, Terraform should own the resources that belong to the Azure platform boundary. These are resources that must exist before Databricks workloads and governance models can be applied.
Typical Terraform-managed Azure resources include:
-
Azure resource groups
-
Azure Databricks workspaces
-
virtual networks and subnets
-
network security groups and route tables
-
private endpoints and private DNS zones
-
storage accounts and containers
-
managed identities
-
access connectors for Azure Databricks
-
Azure Key Vault
-
Databricks groups for RBAC permission management
These resources are relatively stable compared to Databricks-native objects such as jobs, schemas, views or grants. They usually follow a different lifecycle and managing them through a dedicated infrastructure deployment process can help to separate the two areas both on a logical level for organizational purposes, as well as reducing load in the actual deployment processes.
Databricks Account Level vs. Databricks Workspace Level
Within Databricks itself, it is useful to distinguish between account-level resources and workspace-level resources.
Account-level resources exist above individual workspaces. They define the shared Databricks platform context and become especially relevant when operating multiple workspaces. Typical examples include account users, groups, service principals, workspace assignments, Unity Catalog metastores and metastore-to-workspace assignments.
Workspace-level resources exist inside a specific Databricks workspace. These include workspace-local configuration and runtime resources such as clusters, cluster policies, SQL warehouses, jobs, notebooks, workspace permissions and operational settings.
This distinction matters especially when deploying multiple environments at once. Workspace-level resources can usually be provisioned per workspace, while account-level resources often exist only once within the Databricks account and then need to be assigned to one or more workspaces.
Examples include Unity Catalog metastores, account-level groups, service principals and metastore assignments. These resources are shared by nature and therefore do not always fit neatly into the same Terraform flow as workspace-specific infrastructure. When DEV, QA and PROD workspaces are deployed together, account-level resources may require additional existence checks, import logic, manual verification or a separate deployment stage.
For this reason, it can be practical to handle selected account-level resources manually during the initial platform bootstrap, or to manage them through a dedicated Terraform state and pipeline that is separate from the workspace deployments. This avoids creating the same shared resource multiple times and keeps the workspace provisioning process focused on resources that are truly environment-specific.
The practical distinction is:
- Account-level resources define the shared Databricks platform context and are created once, then assigned where needed.
- Workspace-level resources belong to a specific workspace and can be deployed per environment.
Databricks Governance Implementation Approach
The first step is usually the creation of resource groups, shared tags and naming conventions.
resource "azurerm_resource_group" "RG_DEV" {
name = var.resource_group_name
location = var.location
tags = var.tags
}
A consistent naming convention helps identify environment, ownership, region and cost responsibility across multiple subscriptions and workspaces.
Example:
rg-dataplatform-dev-weu
dbw-dataplatform-dev-weu
stplatformdevweu
kv-dataplatform-dev-weu
Once the Azure foundation is available, Terraform can provision the Azure Databricks workspace.
resource "azurerm_databricks_workspace" "this" {
name = local.workspace_name
resource_group_name = azurerm_resource_group.RG_DEV.name
location = azurerm_resource_group.RG_DEV.location
sku = "premium"
tags = var.tags
managed_resource_group_name = local.managed_resource_group_name
}
For enterprise environments, the workspace is often deployed with additional security and networking requirements such as VNet injection, private endpoints and specific DNS zones. These concerns also belong to the infrastructure layer and should be handled before any governance or workload deployment starts.
Terraform should also create the storage accounts, containers, managed identities and Databricks roles used for RBAC.
Watch the recording of our webinar "Bridging Business and Analytics: The Plug-and-Play future of Data Platforms"

Infrastructure Repository Structure
There are several valid ways to structure Terraform code for an Azure Databricks deployment. A module-based approach can be useful when the same infrastructure pattern is reused many times with only small differences. However, it is not always the simplest option.
If environments differ significantly, or if the deployment scope is still manageable, heavy modularization can introduce additional abstraction and complexity. In this implementation, we therefore use a more explicit structure: each environment has its own folder, while the Terraform files inside each folder are organized by responsibility.
This structure keeps the deployment easy to inspect and makes environment boundaries explicit. Each environment has its own backend configuration, variables and Terraform state, which helps separate DEV, QA and PROD changes from each other. The trade-off is that some Terraform definitions are repeated across environments and changes to the structure of resources may need to be implemented multiple times.
Part II: How to Manage Unity Catalog Governance with Declarative Automation Bundles (DAB)
As soon as the underlying Databricks workspaces are provisioned, the next challenge emerges: implementing a consistent, scalable and environment‑aware governance model on top of that infrastructure. Declarative Automation Bundles (DAB) fill this gap by providing a structured way to define Unity Catalog governance, but they don’t cover everything.
At first glance, Unity Catalog appears straightforward: define catalogs, schemas and permissions. However, once multiple teams, environments and pipelines are involved, governance often turns into a fragmented mix of configurations, manual processes and implicit assumptions.
We frequently observe the same challenges across projects:
-
inconsistent permission models across environments
-
unclear separation between infrastructure and data logic
-
duplicated or conflicting resource definitions
-
pipelines that fail due to hidden dependencies
In this section, we share a pragmatic and production-ready approach to manage Unity Catalog governance using Declarative Automation Bundles (DABs).
Strong governance directly shapes how efficiently an organization can use its data in the end. Especially for functional user groups such as Data Platform Teams, Data/AI Engineers, Analysts, Cloud Architects and any team scaling Databricks across multiple environments.
Declarative Governance Architecture
The foundation of our approach is a medallion architecture combined with declarative infrastructure illustrated through a layered governance model that shows how permissions flow from catalogs to schemas and down to tables and views.
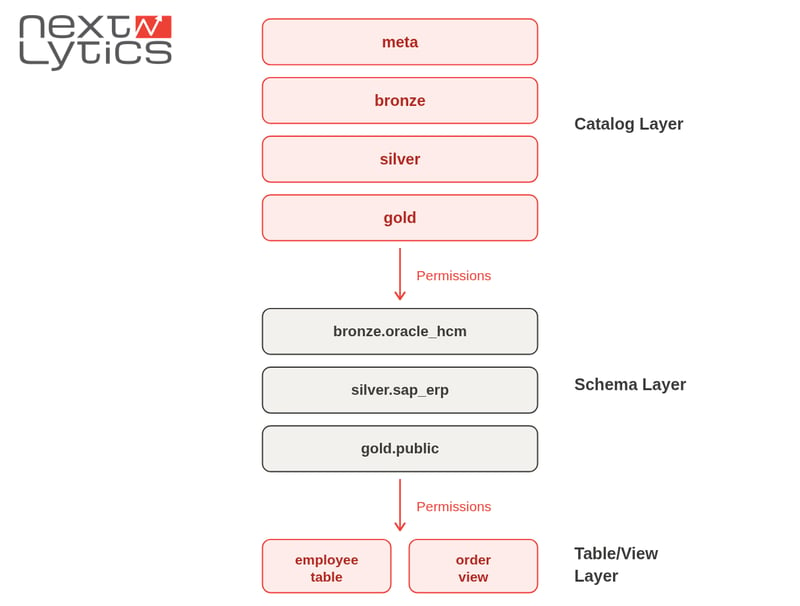
Implementing Governance Declaratively with Databricks Bundles
To translate a governance architecture into a reproducible, environment‑aware automation, we use Databricks Declarative Automation Bundles (DABs) to express Unity Catalog governance along this step-by-step guide:
Step 1: Use a Single Declarative Configuration
A single declarative configuration keeps all environments in one central databricks.yml, removing duplication and establishing a clear source of truth.
Step 2: Understand Catalog-Level Permissions
Catalog‑level permissions define who is allowed to enter and organize a data domain, for example through privileges like USE_CATALOG and CREATE_SCHEMA in the catalog_engineer_privileges block, but they do not grant access to the data itself, which makes misunderstanding their purpose one of the most common pitfalls in Unity Catalog governance.
Typical example:
catalog_engineer_privileges:
- USE_CATALOG
- CREATE_SCHEMA
Step 3: Define Access at Schema Level
The actual data access logic resides at the schema level.
Example:
schemas:
bronze_oracle_hcm:
grants:
- principal: data_engineers
privileges: write_privileges
- principal: data_analysts
privileges: read_privileges
This is where permissions are applied:
-
SELECT -
MODIFY -
CREATE_TABLE WRITE access
Without schema-level governance, access control remains incomplete.
Step 4: Govern Compute and Views for Complete Access Control
Compute access determines who can run workloads or attach notebooks to governed clusters, making it a critical enforcement point for secure and compliant data processing.
Views require explicit permissions because they expose curated or restricted subsets of data, and without governance on both compute and views, users can bypass schema‑level controls and weaken overall governance.
Step 5: Implement Environment-Aware Logic
To apply governance consistently across the platform, the model must adapt to each environment, ensuring flexibility in DEV, stability in QA and strict control in PROD without ever compromising production safety.
Hint: Using YAML Anchors for Scalable Governance Definitions
As governance configurations grow, maintaining consistency and avoiding duplication becomes increasingly challenging. This is where YAML anchors help to keep bundle definitions clean and scalable.
YAML anchors allow you to define a configuration block once and reuse it multiple times.
Step 6: Structuring the Repository for Scalable Governance
A well-designed governance setup also requires a clear and maintainable repository structure. In our implementation, we organize the Databricks bundle into a modular and scalable layout:
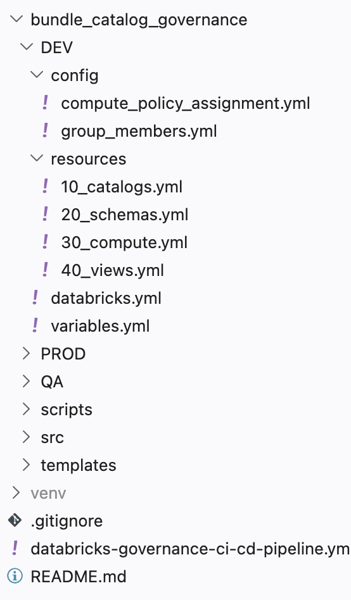
Each part has a distinct responsibility:
- databricks.yml: central entry point for configuration and environment orchestration
- /resources: declarative definitions for clusters, jobs and Unity Catalog governance
- /scripts: executable logic such as initialization routines or group management
- /config: reusable configuration blocks like policy assignments and group membership mappings
This structure keeps governance maintainable, modular and fully aligned with CI/CD principles and also makes the split between Declarative Automation Bundles in the /resources folder and programmatic logic (SDK) in the /scripts folder explicit.
Shortcomings of DAB and the need for Python SDK
After defining catalogs, schemas, permissions and repository structure declaratively, it becomes clear that Databricks Bundles cover only a part of the whole governance story. Bundles are excellent for expressing infrastructure and schema‑level access control, but several critical governance operations remain outside the declarative model. This is where the Databricks Python SDK becomes essential.
Example: CODE BLOCK 1 - unity_governance.py (Python)
# =============================
# WORKSPACE BINDING + ISOLATION
# =============================
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.catalog import CatalogIsolationMode
for catalog in catalogs.values():
try:
print(f"Processing {catalog}")
workspace_client.catalogs.update(
name=catalog, isolation_mode=CatalogIsolationMode.ISOLATED
)
print(f"Isolation set for {catalog}")
workspace_client.workspace_bindings.update(
name=catalog, assign_workspaces=[workspace_id]
)
print(f"Success: {catalog}")
except Exception as e:
print(f"Error: {catalog}: {e}")
Bundles provide strong declarative coverage for catalogs, schemas, grants and compute, but they cannot express workspace governance, account‑level automation, workspace object permissions or fully idempotent logic and because secure multi‑workspace setups depend on exactly these capabilities, the Databricks Python SDK remains essential to fill the gaps Bundles cannot reach.
Table 1: Bundles and SDKs form a complete Governance Framework
| Area | Bundles (DAB) | Python SDK | Notes |
| Governance Definitions | ✅ | ❌ | Bundles define catalogs & schemas declaratively. |
| Permission Models | ✅ | ❌ | YAML anchors keep permission logic DRY. |
| Compute Deployment | ✅ | ❌ | Bundles deploy clusters & SQL warehouses. |
| Compute Governance | ❌ | ✅ | SDK enforces cluster policies & workspace ACLs. |
| View Deployment | ✅ | ❌ | Bundles create views via SQL tasks. |
| View Governance | ❌ | ✅ | SDK manages ACLs & ownership on views. |
| Environment Logic | ✅ | ❌ | DEV/QA/PROD differences expressed declaratively. |
| Programmatic Governance | ❌ | ✅ | Loops, conditions, checks. |
| Idempotent Updates | ❌ | ✅ | Retries, exception handling. |
| Account‑Level Automation | ❌ | ✅ | Bundles are workspace‑scoped only. |
| Workspace Governance | ❌ | ✅ | Catalog isolation, workspace bindings. |
| Ownership & Permissions | ❌ | ✅ | Ownership changes, cluster policy permissions, workspace ACLs. |
Bundles define governance. The SDK enforces governance.
Together, they form the currently only complete automation framework for multi‑workspace, multi‑environment Databricks platforms.
Deployment Process for Databricks Infrastructure & Governance
For our example, the complete platform configuration, including cloud infrastructure (Terraform), Databricks native resources (DAB), and logic (SDK) is managed as code within Azure DevOps repositories. Within those repositories, an Azure Pipeline orchestrates the deployment process across all environments.
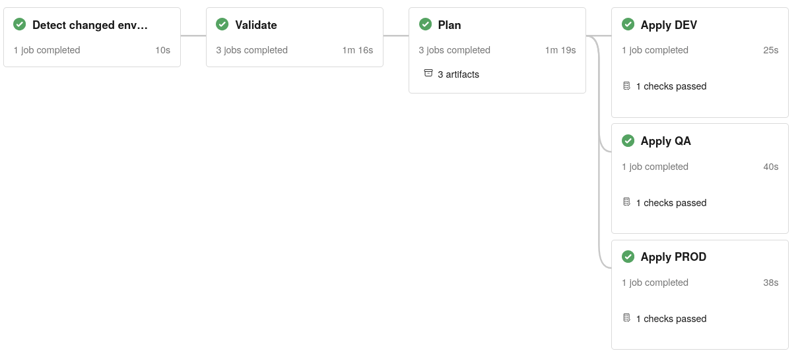
For example, in our Terraform pipeline we have decided to have a single pipeline to validate & plan the deployments across environments, with a separate manual deploy stage per environment.
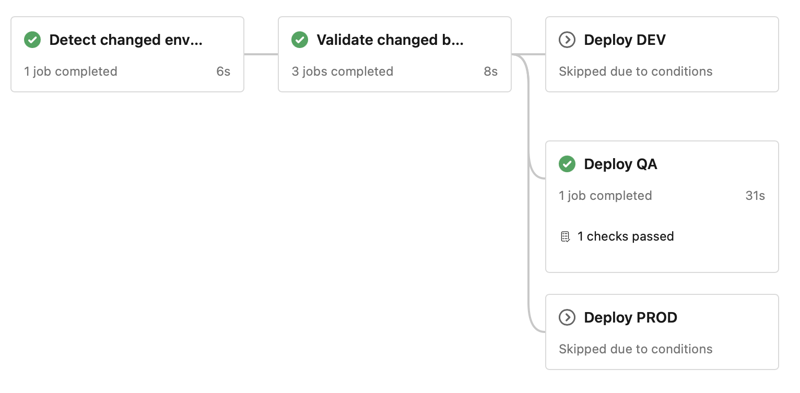
For our Databricks governance pipeline, we use a single pipeline that first detects which environments have changes, validates the changed bundle and only deploys those environments affected, with PROD additionally gated by a manual approval after merging into the main branch.
Provisioning and Governing Azure Databricks with Terraform and Databricks Bundles: Our Conclusion
Combining Terraform, Databricks Declarative Automation Bundles and the Python SDK provides a clean and scalable approach to building Azure Databricks platforms.
-
Terraform establishes the infrastructure,
-
Bundles define governance and resources declaratively,
-
and the SDK fills critical automation gaps.
This separation of concerns enables consistent, secure and environment-aware deployments while avoiding tool overload and manual processes, resulting in a robust and maintainable enterprise data platform.
This part of the deployment is just part of the Databricks journey. If you are wondering, how to best structure your deployments, how to implement Governance or have any other questions regarding Databricks, feel free to contact us.


