/Logo%202023%20final%20dunkelgrau.png?width=221&height=97&name=Logo%202023%20final%20dunkelgrau.png)























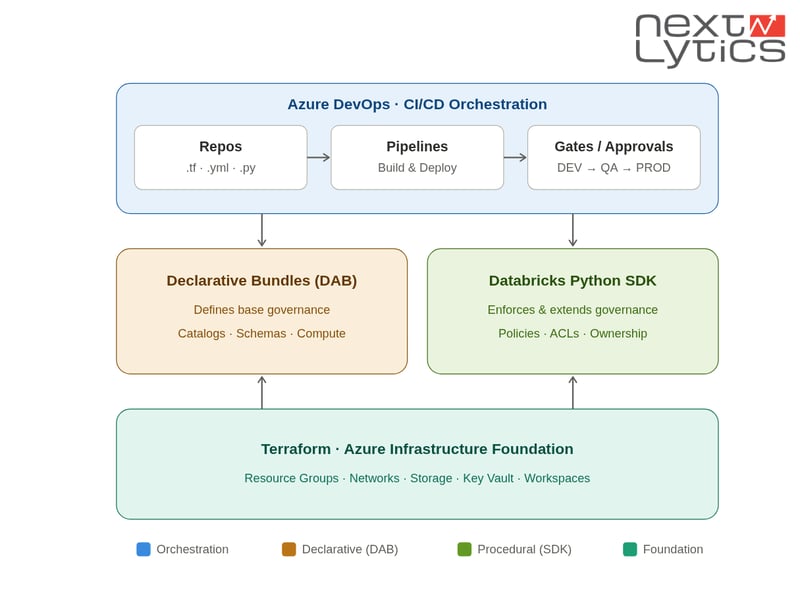
Moderne Datenplattformen müssen robust, sicher und einfach skalierbar für verschiedene Teams und Umgebungen sein. Viele Unternehmen migrieren von isolierten Datenlösungen hin zu gemeinsam genutzten Enterprise-Datenplattformen, die mehrere Teams und Anwendungsfälle bedienen. In diesem Kontext wird Databricks häufig zur zentralen Plattform für Data Engineering, Analytics und KI-Workloads in Entwicklungs-, Test- und Produktionsumgebungen.
In diesem Artikel möchten wir Sie durch den Prozess eines automatisierten Ansatzes zur Bereitstellung einer solchen Plattform auf Azure durch die Kombination dreier Technologien führen:
- Terraform für die Bereitstellung der Azure-Infrastrukturgrundlage,
- Databricks Declarative Automation Bundles (DAB), ehemals bekannt als Databricks Asset Bundles, für die Bereitstellung von Databricks-nativen Ressourcen und Unity Catalog Governance-Definitionen,
- Databricks Python SDK für verfahrenstechnische Steuerungsaufgaben, die nicht vollständig deklarativ ausgedrückt werden können.
Der Anwendungsfall betrifft eine Databricks-Plattform mit mehreren Umgebungen, bei der Infrastruktur, Governance und Workload-Bereitstellung standardisiert und Verantwortlichkeiten klar geregelt werden müssen. Plattform Teams benötigen sichere Arbeitsbereiche, Speicher, Identitäten und Netzwerkverbindungen. Daten Teams benötigen konsistente Kataloge, Schemas, Berechtigungen, Jobs und Ansichten. Sicherheits- und Governance-Teams benötigen klare Zuständigkeiten, wiederholbare Bereitstellungsprozesse und weniger manuelle Konfiguration.
Die Kernidee besteht darin, diese Belange bewusst zu trennen:
- Terraform stellt die Grundlage für die Azure-Plattform bereit.
- Databricks Bundles definieren Databricks-native Ressourcen und Governance.
- Das Databricks SDK schließt die Automatisierungslücken, wo eine deklarative Konfiguration nicht ausreicht.
Durch diese Trennung bleibt die Plattform wartbar und es wird vermieden, dass das häufige Anti-Pattern darin besteht, die gesamte Databricks-Automatisierung in einem einzigen Tool zu erzwingen, nur weil es technisch möglich ist.
Teil I: Bereitstellung der Azure Databricks-Infrastruktur mit Terraform
Die erste Ebene einer produktionsreifen Azure Databricks-Plattform ist nicht die Workspace-Konfiguration selbst, sondern die zugrunde liegende Cloud-Infrastruktur. Netzwerk, Identität, Speicher, Sicherheitsgrenzen und Workspace-Bereitstellung müssen reproduzierbar definiert werden, bevor übergeordnete Databricks-Ressourcen eingeführt werden.
Hier bildet Terraform die Grundlage. Es verwaltet die Azure-Infrastrukturschicht, auf der Databricks basiert, einschließlich Ressourcengruppen, virtueller Netzwerke, Subnetze, Speicherkonten, managed identities, Zugriffskonnektoren, Key Vault-Integration, privater Endpunkte und der Azure Databricks-Arbeitsbereiche selbst.
Erst wenn diese Infrastrukturschicht existiert, macht es Sinn, sich mit Databricks-eigenen Aspekten wie Governance, Jobs, Pipelines, Unity Catalog-Objekten und Berechtigungen zu befassen.
Einfach ausgedrückt:
Terraform erstellt die Plattform.
Databricks Bundles konfigurieren, was darauf aufbaut.
Es gibt sicherlich mehr als eine valide Methode, die Bereitstellung einer Azure Databricks-Plattform zu automatisieren. In diesem Artikel trennen wir die relativ stabile Azure-Infrastruktur von der dynamischeren Databricks-Konfigurationsschicht.
Diese Struktur eignet sich für eine Multi-Umgebungs-Konfiguration mit mehreren Arbeitsbereichen und Governance-Anforderungen. Sie ermöglicht es Terraform außerdem, den bereitgestellten Infrastrukturstatus explizit zu verfolgen, wodurch Änderungen einfacher zu überprüfen, zu reproduzieren und umgebungsübergreifend zu verteilen sind.
Terraform als Infrastruktur-Fundament
In einer Azure Databricks-Architektur sollte Terraform die Ressourcen verwalten, die zur Azure Cloud-Infrastrutkur gehören. Diese Ressourcen müssen vorhanden sein, bevor Databricks-Workloads und Governance-Modelle angewendet werden können.
Typische, von Terraform verwaltete Azure-Ressourcen umfassen:
- Azure-Ressourcengruppen
- Azure Databricks-Arbeitsbereiche
- virtuelle Netzwerke und Subnetze
- Netzwerksicherheitsgruppen und Routingtabellen
- private Endpunkte und private DNS-Zonen
- Speicherkonten und Container
- managed identities
- Zugriffskonnektoren für Azure Databricks
- Azure Key Vault
- Databricks-Gruppen für die RBAC-Berechtigungsverwaltung
Diese Ressourcen sind im Vergleich zu Databricks-eigenen Objekten wie Jobs, Schemas, Views oder Grants relativ stabil. Sie folgen üblicherweise einem anderen Lebenszyklus, und ihre Verwaltung über einen dedizierten Infrastrukturbereitstellungsprozess kann dazu beitragen, die beiden Bereiche sowohl auf logischer Ebene aus organisatorischen Gründen zu trennen als auch die Last in den eigentlichen Deployment-Prozessen zu reduzieren.
Databricks-Kontoebene vs. Databricks Arbeitsbereichsebene
Innerhalb von Databricks selbst ist es sinnvoll, zwischen folgenden Punkten zu unterscheiden: Ressourcen auf Kontoebene und Ressourcen auf Arbeitsbereichsebene.
Die Ressourcen auf Kontoebene existieren über den einzelnen Arbeitsbereichen. Sie definieren den gemeinsamen Kontext der Databricks-Plattform und sind besonders relevant beim Betrieb mehrerer Arbeitsbereiche. Typische Beispiele hierfür sind Benutzerkonten, Gruppen, Service Principals, Arbeitsbereichszuweisungen, Unity Catalog-Metastores und Metastore-zu-Arbeitsbereich-Zuweisungen.
Ressourcen auf Arbeitsbereichsebene existieren innerhalb eines bestimmten Databricks-Arbeitsbereichs. Dazu gehören arbeitsbereichslokale Konfigurations- und Laufzeitressourcen wie Cluster, Clusterrichtlinien, SQL-Warehouses, Jobs, Notebooks, Arbeitsbereichsberechtigungen und Betriebseinstellungen.
Diese Unterscheidung ist besonders wichtig, wenn mehrere Umgebungen gleichzeitig bereitgestellt werden. Ressourcen auf Workspace-Ebene können in der Regel pro Workspace bereitgestellt werden, während Ressourcen auf Kontoebene oft nur einmal innerhalb des Databricks-Kontos existieren und dann einem oder mehreren Workspaces zugewiesen werden müssen.
Beispiele hierfür sind Unity Catalog-Metastores, Gruppen auf Kontoebene, Service Principals und Metastore-Zuweisungen. Diese Ressourcen werden naturgemäß gemeinsam genutzt und lassen sich daher nicht immer nahtlos in denselben Terraform-Workflow wie die Workspace-spezifische Infrastruktur integrieren. Werden DEV-, QA- und PROD-Workspaces gemeinsam bereitgestellt, können für Ressourcen auf Kontoebene zusätzliche Existenzprüfungen, Importlogik, manuelle Verifizierung oder ein separater Bereitstellungsschritt erforderlich sein.
Aus diesem Grund kann es sinnvoll sein, ausgewählte Ressourcen auf Kontoebene während der initialen Plattformeinrichtung manuell zu verwalten oder sie über einen dedizierten Terraform-Status und eine separate Pipeline, getrennt von den Workspace-Bereitstellungen, zu steuern. Dadurch wird vermieden, dieselbe gemeinsam genutzte Ressource mehrfach zu erstellen, und der Workspace-Bereitstellungsprozess konzentriert sich auf wirklich umgebungsspezifische Ressourcen.
Der praktische Unterschied besteht darin:
- Ressourcen auf Kontoebene definieren den gemeinsamen Databricks-Plattformkontext und werden einmal erstellt und dann bei Bedarf zugewiesen.
-
Ressourcen auf Workspace-Ebene gehören zu einem bestimmten Workspace und können pro Umgebung bereitgestellt werden.
Databricks Governance Implementierungsansatz
Der erste Schritt besteht üblicherweise in der Erstellung von Ressourcengruppen, gemeinsamen Tags und Namenskonventionen.
resource "azurerm_resource_group" "RG_DEV" {
name = var.resource_group_name
location = var.location
tags = var.tags
}
Eine einheitliche Namenskonvention hilft dabei, Umgebung, Eigentümer, Region und Kostenverantwortung über mehrere Abonnements und Arbeitsbereiche hinweg zu identifizieren.
Beispiel:
rg-dataplatform-dev-weu
dbw-dataplatform-dev-weu
stplatformdevweu
kv-dataplatform-dev-weu
Sobald die Azure-Grundlage verfügbar ist, kann Terraform den Azure Databricks-Arbeitsbereich bereitstellen.
resource "azurerm_databricks_workspace" "this" {
name = local.workspace_name
resource_group_name = azurerm_resource_group.RG_DEV.name
location = azurerm_resource_group.RG_DEV.location
sku = "premium"
tags = var.tags
managed_resource_group_name = local.managed_resource_group_name
}
In Unternehmensumgebungen wird der Arbeitsbereich häufig mit zusätzlichen Sicherheits- und Netzwerkanforderungen wie VNet-Injection, privaten Endpunkten und spezifischen DNS-Zonen bereitgestellt. Diese Aspekte gehören ebenfalls zur Infrastrukturschicht und sollten vor Beginn jeglicher Governance- oder Workload-Bereitstellung berücksichtigt werden.
Terraform sollte außerdem die Speicherkonten, Container, verwalteten Identitäten und Databricks-Rollen erstellen, die für RBAC verwendet werden.
Sehen Sie sich die Aufzeichnung unseres Webinars an: "Bridging Business and Analytics: The Plug-and-Play Future of Data Platforms"

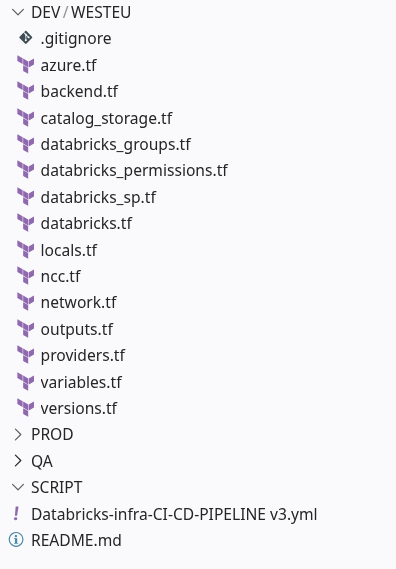
Infrastuktur Repository Structure
Es gibt mehrere sinnvolle Möglichkeiten, Terraform-Code für eine Azure Databricks-Bereitstellung zu strukturieren. Ein modulbasierter Ansatz kann hilfreich sein, wenn dasselbe Infrastrukturmuster häufig mit nur geringfügigen Unterschieden wiederverwendet wird. Er ist jedoch nicht immer die einfachste Option.
Wenn sich die Umgebungen deutlich unterscheiden oder der Bereitstellungsumfang noch überschaubar ist, kann eine starke Modularisierung zu zusätzlicher Abstraktion und Komplexität führen. In dieser Implementierung verwenden wir daher eine explizitere Struktur: Jede Umgebung hat ihren eigenen Ordner, und die Terraform-Dateien innerhalb jedes Ordners sind nach Zuständigkeiten organisiert.
Diese Struktur ermöglicht eine einfache Überprüfung des Deployments und definiert die Umgebungsgrenzen explizit. Jede Umgebung verfügt über eine eigene Backend-Konfiguration, eigene Variablen und einen eigenen Terraform-Status, wodurch Änderungen in den Umgebungen Entwicklung, Qualitätssicherung und Produktion voneinander getrennt werden. Der Nachteil besteht darin, dass einige Terraform-Definitionen in verschiedenen Umgebungen wiederholt werden und Änderungen an der Ressourcenstruktur unter Umständen mehrfach implementiert werden müssen.
Teil II: Verwaltung der Unity-Kataloggovernance mit deklarativen Automatisierungsbündeln (DAB)
Sobald die zugrunde liegenden Databricks-Workspaces bereitgestellt sind, stellt sich die nächste Herausforderung: die Implementierung eines konsistenten, skalierbaren und umgebungssensitiven Governance-Modells auf dieser Infrastruktur. Declarative Automation Bundles (DAB) schließen diese Lücke, indem sie eine strukturierte Möglichkeit zur Definition der Unity Catalog-Governance bieten, decken aber nicht alles ab.
Auf den ersten Blick wirkt der Unity Catalog unkompliziert: Kataloge, Schemas und Berechtigungen definieren. Sobald jedoch mehrere Teams, Umgebungen und Pipelines involviert sind, entwickelt sich die Governance oft zu einem unübersichtlichen Geflecht aus Konfigurationen, manuellen Prozessen und impliziten Annahmen.
Wir beobachten immer wieder dieselben Herausforderungen in verschiedenen Projekten:
- inkonsistente Berechtigungsmodelle in verschiedenen Umgebungen
- Unklare Trennung zwischen Infrastruktur und Datenlogik
- doppelte oder widersprüchliche Ressourcendefinitionen
- Pipelines, die aufgrund versteckter Abhängigkeiten fehlschlagen
In diesem Abschnitt teilen wir einen pragmatischen und produktionsreifen Ansatz um Unity Catalog-Governance mithilfe von Declarative Automation Bundles (DABs) zu verwalten.
Eine starke Governance beeinflusst maßgeblich, wie effizient eine Organisation ihre Daten letztendlich nutzen kann, insbesondere für funktionale Anwender.Gruppen wie Datenplattform-Teams, Daten-/KI-Ingenieure, Analysten, Cloud-Architekten und jedes Team, das Databricks über mehrere Umgebungen hinweg skaliert.
Deklarative Governance-Architektur
Grundlage unseres Ansatzes ist eine Medaillonarchitektur in Kombination mit einer deklarativen Infrastruktur, die anhand eines geschichteten Governance-Modells veranschaulicht wird. Dieses zeigt, wie Berechtigungen von Katalogen über Schemas bis hin zu Tabellen und Views fließen.
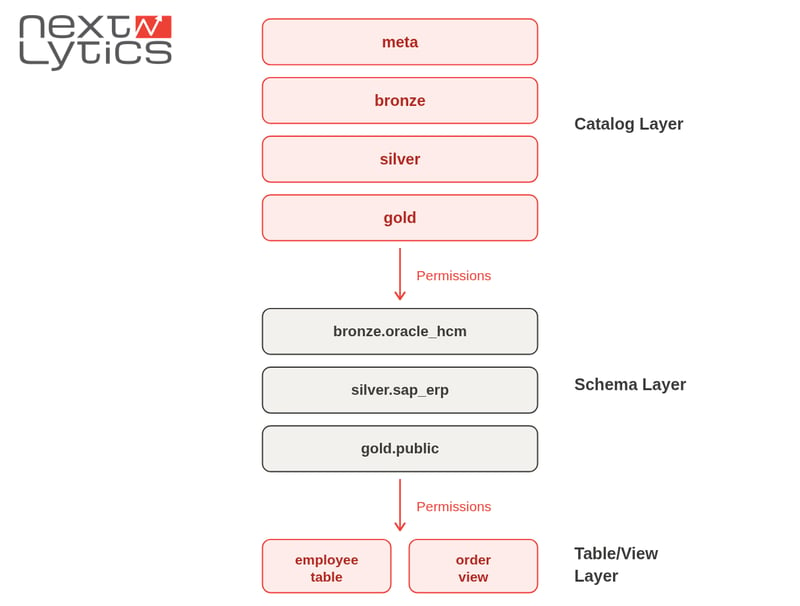
Governance deklarativ mit Databricks Bundles implementieren
Um eine Governance-Architektur in eine reproduzierbare, umgebungsbewusste Automatisierung zu übersetzen, verwenden wir Databricks Declarative Automation Bundles (DABs), um die Unity Catalog-Governance anhand dieser Schritt-für-Schritt-Anleitung auszudrücken:
Schritt 1: Verwendung einer einzigen deklarative Konfiguration
Eine einzige deklarative Konfiguration hält alle Umgebungen in einer zentralen databricks.yml, zur Beseitigung von Duplikaten und Schaffung einer source-of-truth.
Schritt 2: Katalogberechtigungen verstehen
Berechtigungen auf Katalogebene definieren, wer auf eine Datendomäne zugreifen und diese organisieren darf, beispielsweise durch Berechtigungen wie USE_CATALOG und CREATE_SCHEMA im catalog_engineer_privileges. Sie blockieren zwar Daten, gewähren aber keinen Zugriff auf die Daten selbst, weshalb ein Missverständnis ihres Zwecks zu den häufigsten Fehlern bei der Verwaltung des Unity Catalog gehört.
Typisches Beispiel:
catalog_engineer_privileges:
- USE_CATALOG
- CREATE_SCHEMA
Schritt 3: Zugriff auf Schemaebene definieren
Die eigentliche Datenzugriffslogik befindet sich auf der Schemaebene.
Beispiel:
schemas:
bronze_oracle_hcm:
grants:
- principal: data_engineers
privileges: write_privileges
- principal: data_analysts
privileges: read_privileges
Hier werden die Berechtigungen angewendet:
-
SELECT -
MODIFY -
CREATE_TABLE -
WRITE access
Ohne eine Steuerung auf Schemaebene bleibt die Zugriffskontrolle unvollständig.
Schritt 4: Rechenleistung und Views für vollständige Zugriffskontrolle steuern
Der Rechenzugriff (Compute) bestimmt, wer Workloads ausführen oder Notebooks an verwaltete Cluster anbinden darf, und ist somit ein entscheidender Kontrollpunkt für die sichere und konforme Datenverarbeitung.
Views erfordern explizite Berechtigungen, da sie kuratierte oder eingeschränkte Datenteilmengen offenlegen. Ohne Governance sowohl auf Compute- als auch auf View-Ebene können Benutzer die Kontrollen auf Schemaebene umgehen und die Gesamt-Governance schwächen.
Schritt 5: Umgebungsbezogene Logik implementieren
Um eine einheitliche Governance auf der gesamten Plattform zu gewährleisten, muss sich das Modell an jede Umgebung anpassen.Flexibilität sicherstellen auf DEV, Stabilität auf QA und strenge Kontrolle auf PROD ohne jemals die Produktionssicherheit zu beeinträchtigen.
Hinweis: Verwendung von YAML-Ankern für skalierbare Governance Definitionen
Mit zunehmender Komplexität der Governance-Konfigurationen wird es immer schwieriger, Konsistenz zu wahren und Duplikate zu vermeiden. Hier setzt die Herausforderung an. YAML-Anker helfen dabei, Bundle-Definitionen sauber und skalierbar zu halten.
YAML-Anker ermöglichen es Ihnen, einen Konfigurationsblock einmal zu definieren und ihn mehrfach wiederzuverwenden.
Schritt 6: Strukturierung des Repositories für skalierbare Governance
Eine gut konzipierte Governance-Struktur erfordert auch eine übersichtliche und wartungsfreundliche Repository-Struktur. In unserer Implementierung organisieren wir das Databricks-Bundle in einem modularen und skalierbaren Layout:
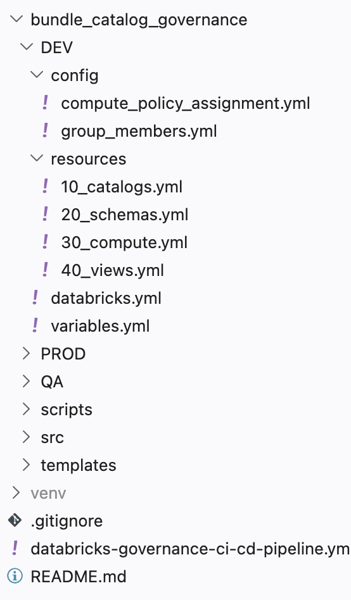
Jeder Teil hat eine bestimmte Verantwortung:
- databricks.yml: zentraler Einstiegspunkt für Konfiguration und Umgebungs-Orchestrierung
- /ressources: Deklarative Definitionen für Cluster, Jobs und die Verwaltung des Unity-Katalogs
- /scripts: ausführbare Logik wie Initialisierungsroutinen oder Gruppenverwaltung
- /config: wiederverwendbare Konfigurationsblöcke wie Richtlinienzuweisungen und Gruppenmitgliedschaftszuordnungen
Diese Struktur gewährleistet eine wartungsfreundliche, modulare und vollständig auf CI/CD-Prinzipien abgestimmte Governance und ermöglicht zudem die Aufteilung zwischen deklarativen Automatisierungs-Bundles im /ressourcen Ordner und programmatische Logik (SDK) im /scripts Ordner explizit.
Schwächen von DAB und die Notwendigkeit des Python SDK
Nach der deklarativen Definition von Katalogen, Schemas, Berechtigungen und Repository-Struktur wird deutlich, dass Databricks Bundles nur einen Teil des gesamten Governance-Themas abdecken. Bundles eignen sich hervorragend zum Ausdruck von Infrastruktur und Zugriffskontrollen auf Schemaebene, doch einige kritische Governance-Prozesse bleiben außerhalb des deklarativen Modells. Hier setzt die Databricks Python SDK an.
Beispiel: CODE BLOCK 1 - unity_governance.py (Python)
# =============================
# WORKSPACE BINDING + ISOLATION
# =============================
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.catalog import CatalogIsolationMode
for catalog in catalogs.values():
try:
print(f"Processing {catalog}")
workspace_client.catalogs.update(
name=catalog, isolation_mode=CatalogIsolationMode.ISOLATED
)
print(f"Isolation set for {catalog}")
workspace_client.workspace_bindings.update(
name=catalog, assign_workspaces=[workspace_id]
)
print(f"Success: {catalog}")
except Exception as e:
print(f"Error: {catalog}: {e}")
Bundles bieten eine starke deklarative Abdeckung für Kataloge, Schemas, Berechtigungen und Compute, aber sie können weder Workspace-Governance, Automatisierung auf Kontoebene, Workspace-Objektberechtigungen noch vollständig reproduzierbare Logik ausdrücken. Und da sichere Multi-Workspace-Setups genau von diesen Voraussetzungen abhängen, bleibt die Databricks Python SDK unerlässlich, um die Lücken zu schließen, die Bundles nicht abdecken können.
Tabelle 1: Bundles und SDKs bilden ein vollständiges Governance-Framework
| Bereich | Bundles (DAB) | Python SDK | Anmerkungen |
| Definitionen von Governance | ✅ | ❌ | Bundles definieren Kataloge und Schemata deklarativ. |
| Berechtigungsmodelle | ✅ | ❌ | YAML-Anchors sorgen für eine DRY-Berechtigungslogik. |
| Rechenbereitstellung | ✅ | ❌ | Bundles stellen Cluster und SQL-Data-Warehouses bereit. |
| Compute-Governance | ❌ | ✅ | Das SDK setzt Clusterrichtlinien und Workspace-ACLs durch. |
| Bereitstellung anzeigen | ✅ | ❌ | Bundles erstellen Views über SQL-Tasks. |
| Governance anzeigen | ❌ | ✅ | Das SDK verwaltet ACLs und die Besitzrechte an Views. |
| Umgebungslogik | ✅ | ❌ | Die Unterschiede zwischen DEV, QA und PROD werden deklarativ ausgedrückt. |
| Programmatische Steuerung | ❌ | ✅ | Schleifen, Bedingungen, Prüfungen. |
| Idempotente Updates | ❌ | ✅ | Retries, Exception-Handling. |
| Automatisierung auf Kontoebene | ❌ | ✅ | Bundles sind nur auf den Arbeitsbereich beschränkt. |
| Workspace-Governance | ❌ | ✅ | Katalogisolierung, Arbeitsbereichsbindungen. |
| Eigentumsrechte und Berechtigungen | ❌ | ✅ | Eigentümerwechsel, Clusterrichtlinienberechtigungen, Arbeitsbereichs-ACLs. |
Bundles definieren die Governance. Das SDK setzt die Governance um.
Zusammen bilden sie das derzeit einzige vollständige Automatisierungsframework für Databricks-Plattformen mit mehreren Arbeitsbereichen und Umgebungen.
Bereitstellungsprozess für Databricks Infrastruktur(Terraform) & Governance (DAB)
In unserem Beispiel wird die gesamte Plattformkonfiguration, einschließlich Cloud-Infrastruktur (Terraform), Databricks-eigenen Ressourcen (DAB) und Logik (SDK), als Code in Azure DevOps-Repositories verwaltet. Innerhalb dieser Repositories orchestriert eine Azure-Pipeline den Bereitstellungsprozess über alle Umgebungen hinweg.
Beispielsweise haben wir uns in unserer Terraform-Pipeline dafür entschieden, eine einzige Pipeline zur Validierung und Planung der Deployments über verschiedene Umgebungen hinweg zu verwenden, mit einer separaten manuellen Deployment-Phase pro Umgebung.
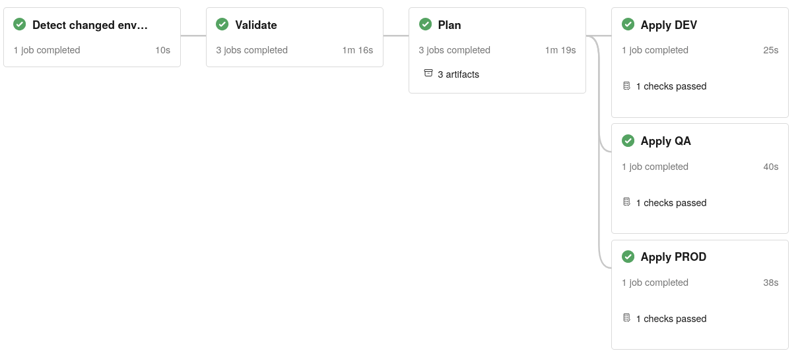
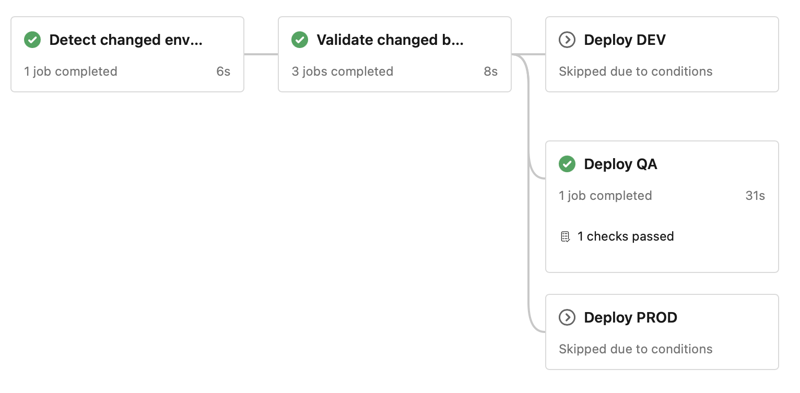
Für unsere Databricks-Governance-Pipeline verwenden wir eine einzige Pipeline, die zunächst erkennt, welche Umgebungen Änderungen aufweisen, das geänderte Bundle validiert und nur die betroffenen Umgebungen anschließend bereitstellt. Die PROD-Umgebung wird zusätzlich durch eine manuelle Genehmigung nach dem Zusammenführen in den main branch geschützt.
Bereitstellung und Verwaltung von Azure Databricks mit Terraform und Databricks-Bundles: Unser Fazit
Die Kombination von Terraform, Databricks Declarative Automation Bundles und dem Python SDK bietet einen sauberen und skalierbaren Ansatz zum Aufbau von (Azure) Databricks-Plattformen.
- Terraform stellt die Infrastruktur bereit,
- Bundles definieren Governance und Ressourcen deklarativ,
- und die SDK schließt kritische Automatisierungslücken.
Diese Trennung der Zuständigkeiten ermöglicht konsistente, sichere und umweltbewusste Bereitstellungen und vermeidet gleichzeitig eine Überlastung der Tools und manuelle Prozesse, was zu einer robusten und wartungsfreundlichen Unternehmensdatenplattform führt.
Dieser Teil der Umsetzung ist nur ein Schritt auf dem Weg mit Databricks. Wenn Sie sich fragen, wie Sie Ihre Bereitstellungen am besten strukturieren, wie Sie Governance umsetzen können oder sonstige Fragen zu Databricks haben, wenden Sie sich jederzeit gerne an uns.



