/Logo%202023%20final%20dunkelgrau.png?width=221&height=97&name=Logo%202023%20final%20dunkelgrau.png)























Wegen des zunehmendem Wettbewerbsdrucks wird es umso wichtiger, die individuellen Bedürfnisse seiner Kunden zu kennen und zu adressieren. Für einen großen und vielfältigen Kundenstamm ist es jedoch sehr zeit- und ressourcenaufwendig, jeden Kunden persönlich zu betreuen. Mithilfe einer Kundensegmentierung lassen sich verschiedene Kundengruppen mit speziellen Charakteristika und spezifischem Kaufverhalten automatisiert identifizieren.
Mit diesem Verständnis um das Kundenverhalten, können gezielt Marketingstrategien entwickelt und damit die Loyalität der Kunden und der Umsatz Ihres Unternehmens gesteigert werden. Somit bildet die Kundensegmentierung die Basis für ein erfolgreiches Customer Relationship Management (CRM).In diesem Artikel erfahren Sie, wie Sie Ihren Kundenstamm mithilfe der praxiserprobten RFM-Analyse segmentieren können. Weiterhin werden ebenso die Grenzen dieses Analysemodells erläutert und alternative Methoden aus dem Bereich der Maschinellen Lernverfahren vorgestellt.
Kundensegmentierung
Bei der Kundensegmentierung stehen eine Reihe an Segmentierungskriterien zur Auswahl. Kundengruppen können sowohl anhand demografischer Merkmale (Alter, Verdienst, Branche etc.), als auch anhand der Kaufhistorie (Umsatz, Kaufaktivität, etc.) gebildet werden. Die RFM-Analyse setzt ihren Fokus auf letzteres. Der deskriptive Ansatz besticht durch leichte Umsetzbarkeit, intuitives Handling und angenehme Flexibilität.
Gezielte Marketingstrategien entwickeln mithilfe der RFM-Analyse
Bei der RFM-Analyse handelt es sich um ein mehrdimensionales Scoring-Verfahren mit Fokus auf den folgenden drei Parametern:
- Recency (R) - Aktualität eines Kunden: Tage seit dem letzten Kauf.
- Frequency (F) - Häufigkeit der Buchungen/Umsätze eines Kunden: Anzahl der Käufe z.B. in einer Zeitperiode von 6 Monaten.
- Monetary (M) - Gesamtumsatz eines Kunden: Summe der Umsätze z. B. in einer Zeitperiode von 6 Monaten.
Somit kann die RFM-Analyse überall dort durchgeführt werden, wo eine Datenbank mit den benötigten Transaktionsinformationen eines jeden Kunden zur Verfügung steht.
Nachdem für alle betrachteten Kunden die Recency-, Frequency- und Monetary-Werte ermittelt wurden, werden anhand dieser Werte R-, F- und M-Scores bzw. Klassen bestimmt. Die Klassen können entweder anhand fester Wertebereiche aufgeteilt werden oder nach Quartilen oder Quantilen, sodass sich in jeder Klasse gleich viele Kunden befinden. Wir empfehlen die erste Variante, da keine Überschneidungen auftreten können und der Wertebereich flexibel gewählt werden kann z.B. in Abstimmung mit Vorabinformationen aus dem Vertrieb. Zudem ist es nicht zwingend notwendig, bei einer Kundensegmentierung gleich große Gruppen zu erhalten. Dabei würden Kunden mit außergewöhnlichem Verhalten sich nicht merklich abgrenzen.
Die Kundensegmentierung und Berechnungen werden beispielhaft an einem zufällig erstellten Datensatz gezeigt:
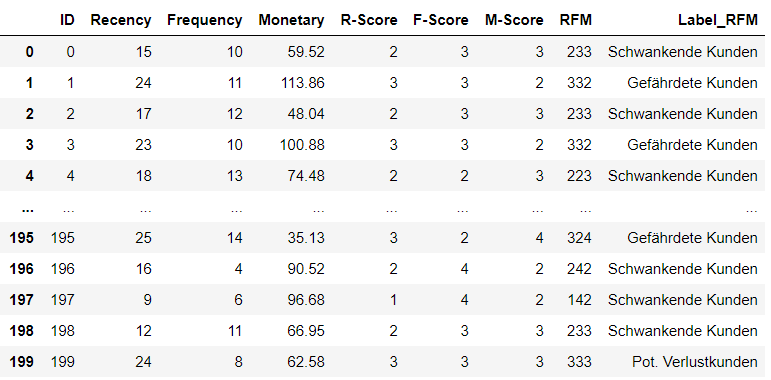
Für ein Beispielszenario wird der Verständlichkeit halber angenommen, dass ein kleiner Kundenstamm von 200 Kunden vorliegt. In der Realität besteht eine Datenbank aus weitaus mehr Kunden mit einer großen Vielfalt. In diesem Szenario sollen die Kunden anhand ihres Kaufverhaltens in den letzten 6 Wochen segmentiert werden. Bei der Auswahl der betrachteten Zeitperiode kann in Abhängigkeit zu den vertriebenen Produkten Ihres Unternehmens beliebig variiert werden. Empfehlenswert sind z.B. quartalsweise, halbjährliche und jährliche Berechnungen.
Wie Sie SAP BW und State of the Art Machine Learning zusammenbringen

Im ersten Schritt werden die Recency, Frequency und Monetary-Werte für jeden Kunden bestimmt. Die resultierenden Wertebereiche werden in diesem Beispiel in vier Bins aufgeteilt und dementsprechend den R-, F- und M-Scores 1 - 4 zugeordnet. Score 1 steht hierbei für das bestmögliche Ergebnis und 4 für das schlechteste. Da eine hohe Recency auf nicht-aktuelle Umsätze hinweist bekommen Kunden mit maximalen Recency-Werten einen R-Score von 4. Kunden, die innerhalb der letzten sechs Wochen häufige Buchungen vermerkt haben und somit maximale Frequency-Werte aufweisen, bekommen einen F-Score von 1. Dementsprechend wird Kunden mit maximalen Monetary-Werten ein M-Score von 1 zugeordnet. Die verschiedenen Scores werden zusammengefasst zum sogenannten RFM-Score, welcher die jeweilige Kundenqualität beschreibt. Dieser Wert kann im weitesten Sinne auch als Customer Lifetime Value (CLV) interpretiert werden. Bei jeweils vier Bins ergeben sich bis zu 64 verschiedene RFM-Scores bzw. Kundengruppen. Bei der hohen Anzahl wird es schwierig, signifikante Unterschiede zwischen den Gruppen festzustellen. Um dies zu vermeiden, werden die Kundengruppen zu Segmenten zusammengefasst. Die Graphik zeigt eine beispielhafte Segmentierung der Kundengruppen bzw. Scores.
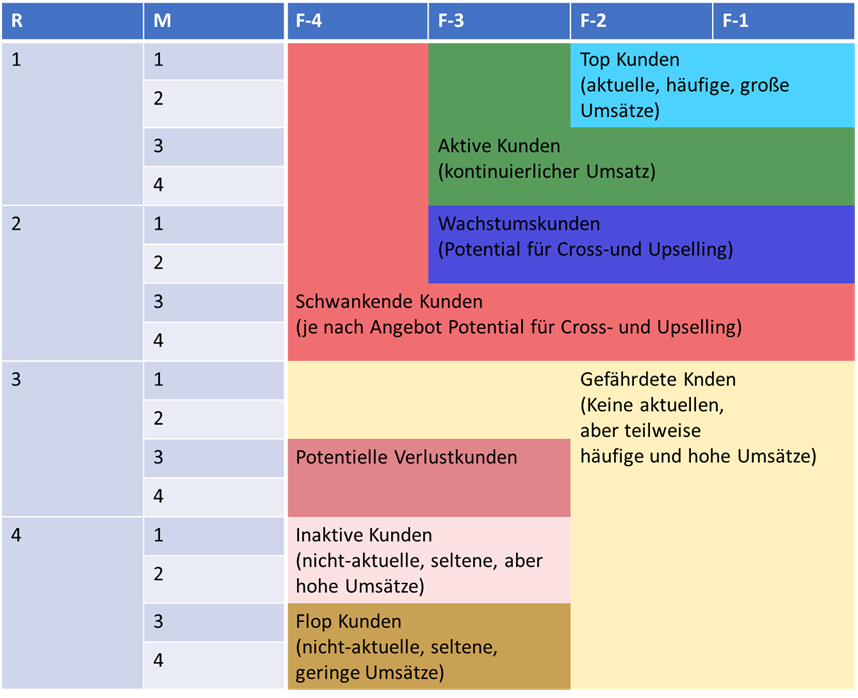
Dementsprechend werden Kunden mit dem optimalen RFM-Score von 111 als Top-Kunden klassifiziert und solche mit dem schlechtesten RFM-Score von 444 als Flop-Kunden.
Auf diese Weise lässt sich ein Kundenstamm beliebiger Größe segmentieren. Das Ergebnis des RFM-Labelings auf den Beispieldatensatz zeigt folgende Treemap:
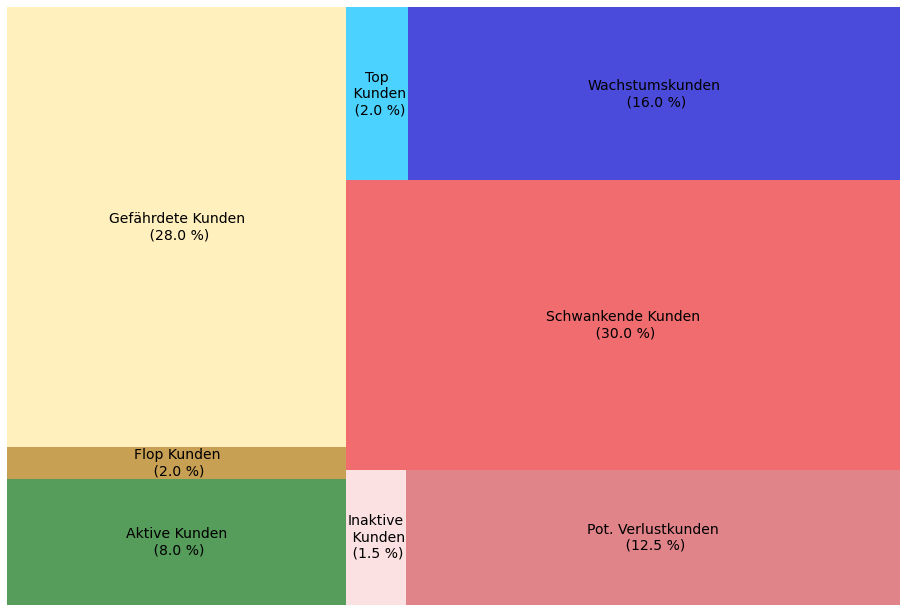
Anhand der verschiedenen Segmente können nun individuelle Marketingstrategien entwickelt werden. Ein Beispiel: Bei einem einkommensstarken Kunden mit einem RFM-Score von 421 aus dem Segment Gefährdete Kunden liegt die letzte Buchung bereits länger zurück. Selbstverständlich sollten einkommensstarke Kunden nicht verloren gehen - doch besteht hier die Gefahr, dass dieser Kunde zur Konkurrenz abwandert. Um dies zu verhindern können beispielsweise ein persönlicher Kontakt durch den Vertrieb hergestellt, eine Vertragsverlängerung angeboten und/oder neue innovative Produkte hervorgehoben werden.
Bei einem anderen Kunden mit dem RFM-Score 141 aus dem Segment Schwankende Kunden könnte es sich aufgrund der hohen Recency und der niedrigen Frequency um einen Neukunden handeln. Der hohe Monetary-Wert deutet auf ein großes Potential hin, mehr Umsatz aus diesem Kunden in Zukunft generieren zu können. Hier ist es ratsam, den Kunden zu Beginn stärker zu unterstützen (On-Boarding Support) und langfristig eine enge Kundenbeziehung aufzubauen, um beispielsweise neue Produkte direkt vorzustellen und zu vermarkten (Up-Selling). Ein Kunde derselben Gruppe mit einem Score von 214 und demnach mit einem schlechteren Monetary-Wert könnte hingegen mit besonderen Angeboten wie Mengenrabatten oder zusätzlichen reduzierten Produkten beworben werden (Cross-Selling).
Die Beispiele machen deutlich, dass die RFM-Analyse definierte Kundengruppen mit ausgeprägter Geschäftsentwicklung identifizieren kann und somit den Vertrieb und das Management unterstützt.
Vorteile und Grenzen der RFM-Analyse
Das gewählte Beispiel zeigt, dass die RFM-Analyse für verschiedenste Business Units und Business Cases genutzt werden kann. Dabei können die Annahmen und Attribute des Modells zielgerichtet verändert werden. Beispielsweise können die Kunden vorab anhand bestimmter Merkmale (z.B. nach Branchenzugehörigkeit) aufgeteilt werden und die RFM-Analyse kann somit branchenspezifisch ausgeführt werden.
Die RFM-Analyse lässt sich außerdem durch den zusätzlichen Parameter Length erweitern (LRFM-Analyse), welcher die Anzahl an Tagen seit dem ersten Vertragsabschluss beschreibt bzw. seit wann der Kunde in der Datenbank gespeichert ist.
Des Weiteren eignen sich die berechneten Parameter optimal als Features für Cluster-Verfahren aus dem Machine Learning-Bereich und bieten damit eine Basis für Prognosemodelle. Dies zeigt jedoch bereits die Grenzen der RFM-Analyse, denn alleinstehend ist sie nicht in der Lage vorherzusagen, wie sich ein Kunde in Zukunft verhalten wird. Sie kann lediglich auf vergangene Daten zugreifen und beispielsweise Vergleiche zum Verhalten des Kunden aus den vorherigen Jahren machen. Nichtsdestotrotz eignet sich die Analyse, um kurzfristige Maßnahmen abzuleiten (persönlicher Kontakt, Rabatte etc.).
Kundensegmentierung mit künstlicher Intelligenz
Auch im Bereich des Kundenmanagements werden maschinelle Lernverfahren immer beliebter. Bei der Segmentierung stehen insbesondere Clustering-Algorithmen wie beispielsweise K-Means oder DBSCAN im Fokus. Darauf basierend können Klassifikation- oder Zeitreihen-Algorithmen genutzt werden, um das Kaufverhalten der Kunden in der Zukunft vorherzusagen. So wird frühzeitig erkannt, wenn sich ein Kunde anders verhält, z. B aufgrund eines bestimmtes Events (z.B. Corona-Lockdown). Klassifikationsalgorithmen können darüber hinaus genutzt werden, um vorherzusagen, ob ein Kunde auf ein bestimmtes Marketing-Angebot reagiert oder nicht.
Die Predictive Analysis Library (PAL) als Teil des SAP-Ökosystems enthält vorgefertigte Algorithmen für verschiedene Einsatzgebiete u. a. für die Kundensegmentierung. Dies ermöglicht Ihnen In-Database Machine Learning in hoher Geschwindigkeit.
In diesem Blogartikel geben wir Ihnen einen Überblick über die PAL.
RFM-Analyse - Unser Fazit
Fakt ist: Jedes Unternehmen profitiert von Kundensegmentierung. Mit der RFM-Analyse lassen sich schnell verschiedene Gruppen von Kunden mit ähnlichen Charakteristika identifizieren und daraus geschäftsrelevante Erkenntnisse schlussfolgern. Es bringt viele Vorteile mit sich. Dazu zählt sowohl die universelle Anwendung in verschiedenen Bereichen (Finance, Marketing, Vertrieb) als auch die Anpassbarkeit und Flexibilität. Jedoch handelt sich lediglich um eine Status quo Analyse und kann insbesondere im klassischem BI-Reporting eingesetzt werden, um eine grundlegende deskriptive Segmentierung zu ermöglichen, d.h. es kommt schnell an seine Grenzen und zeigt Schwächen in der Methodik. Im Gegensatz dazu nutzen Verfahren aus dem Machine Learning Bereich anstatt des deskriptiven Ansatzes überwiegend Distanzmetriken zum Bestimmen der Kundensegmente. Um Ihre Prozesse bestmöglich zu gestalten, kann also auch hier Maschinelles Lernen der Weg zum Erfolg sein. Damit Sie dabei nicht den Durchblick und die Kontrolle verlieren, empfehlen wir Ihnen unser Whitepaper “SAP BW und State of the Art Machine Learning”. In diesem beleuchten wir - neben dem gesamten Machine Learning Portfolio von SAP - auch einen Open Source unterstützten Ansatz auf Basis des NextLytics Python Software Development Kits (NLY-SDK) und geben klare Empfehlungen, wie Sie gewinnbringende Vorteile aus Ihren Daten herausholen können.


