/Logo%202023%20final%20dunkelgrau.png?width=221&height=97&name=Logo%202023%20final%20dunkelgrau.png)























Im NextLytics Blogartikel der letzten Woche haben wir das Konzept des Feature Store als neue Komponente in Machine Learning Architekturen beleuchtet und die Gründe diskutiert, in eine solche zusätzliche Komponente zu investieren.
Diese Woche konzentrieren wir uns auf die verschiedenen Implementierungsmöglichkeiten, die Ihrem Unternehmen zur Verfügung stehen und welche Argumente dabei berücksichtigt werden sollten.
Rückblick
Beginnen wir mit einer kurzen Wiederholung dessen, was ein Feature Store ist und wie Ihr Unternehmen oder Team von der Einführung profitieren könnte.
Der Feature Store
Das Konzept dedizierter Feature Stores gibt es seit einigen Jahren: Große Technologie- und Internetkonzerne haben den Begriff geprägt, um ihre Lösungen für eine verbleibende Problemstelle im Data Science Workflow zu beschreiben. Heute sind Feature Stores ein integraler Bestandteil der Infrastruktur erfolgreicher datengesteuerter Unternehmen und ein Eckpfeiler skalierbarer Frameworks für Machine Learning. Feature Stores wirken als Schnittstelle zwischen verschiedenen Datenquellen und Frameworks für die Entwicklung und den Betrieb von Machine Learning (ML) Modellen. Sie können zu einem effizienteren Feature Engineering und zu Data Discovery Prozessen beitragen und das Data Science Team von repetitiven Aufgaben befreien.
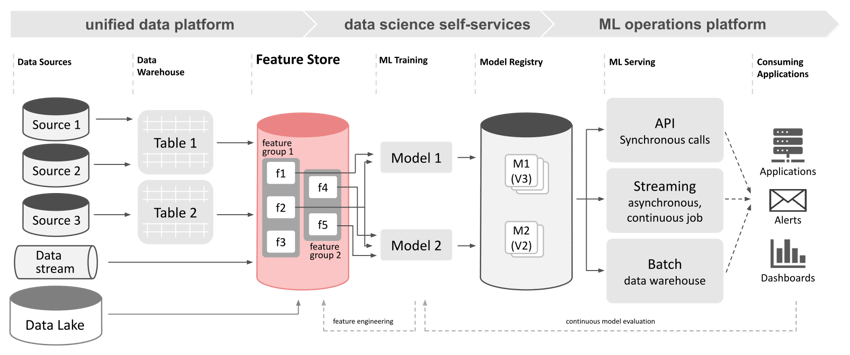
Brauchen Sie einen Feature Store?
Verbringen Ihre Data Scientists mehr Zeit mit Aufbereitung und Beschaffung von Daten oder dem Feature Engineering als mit der eigentlichen Entwicklung und Optimierung von ML Modellen? Werden für jede ML basierte Anwendung, die Sie betreiben, immer wieder die gleichen Merkmale aufbereitet? Stapeln sich Versionen und Kopien von Funktions- und Trainingsdatensätzen in einem Data Lake? Führen Ihre Teams immer mehr eigene REST Schnittstellen ein, um spezifische Metriken für ML Anwendungen bereitzustellen? Oder wächst die Anzahl der benutzerdefinierten Tabellen, die von Ihrem ML Team in einer Analysedatenbank erstellt werden, exponentiell?
Wenn Sie eine oder mehrere dieser Fragen mit einem eindeutigen "Ja" beantworten können, sollten Sie die Möglichkeit der Einführung einer Feature Stores Infrastruktur prüfen.
Optionen für die Implementierung
Doch welche Optionen stehen Ihrem Unternehmen zur Verfügung, wenn Sie sich entscheiden, einen Feature Store in Ihre aktuelle Data-Science-Architektur einzubinden?
In Blogartikeln, Whitepaper und Konferenzbeiträgen werden im Allgemeinen drei Ansätze vorgestellt:
- Verwendung einer integrierten Lösung vom Anbieter einer vollständen Machine Learning Produktlandschaft
- Anpassung von Open-Source-Software an Ihre eigene Infrastruktur
- Entwicklung einer eigenen Lösung für Ihre spezifischen Anforderungen
Integriertes Produkt
Sich auf das bestehende Produkt Ihres etablierten Anbieters zu verlassen, ist definitiv die bequemste Option. AWS, Databricks und Microsoft Azure haben in ihren allgemeinen "KI"-Frameworks bereits Feature Store Komponenten aufgenommen, die mit vollständig integrierten Benutzeroberflächen und Benutzerverwaltungsdiensten ausgestattet sind. Das Gleiche gilt für die meisten Anbieter, die schlüsselfertige On-Premise-Lösungen auf Basis proprietärer Software anbieten.
Integrierte Feature Stores in Ihre Machine Learning Architektur einzubinden, ist zunächst mit sehr niedrigem Aufwand verbunden. Abgesehen von der initialen Konfiguration sind diese Lösungen sofort einsatzbereit und die größte Herausforderung wird die Anpassung der bestehenden Workflow-Konventionen unter den designierten Benutzern sein, wahrscheinlich den Data-Engineering- und Data-Science-Teams Ihres Unternehmens. Diese schnellen Erfolge können auf Kosten der Arbeit mit der spezifischen Funktionalität oder API des Produkts gehen, die nicht unbedingt perfekt zu Ihren aktuellen Arbeitsabläufen und Prozessen passt. Die Einführung neuer Funktionen in diese vom jeweiligen Hersteller verwalteten Produkte kann im Vergleich zu Open-Source-Projekten für einen einzelnen Kunden langsamer oder schwieriger zu beeinflussen sein.
Darüber hinaus sind die betreffenden Lösungen in der Regel nicht verfügbar, wenn Ihr Unternehmen nicht bereits Kunde beim entsprechenden Anbieter ist und eine Migration der gesamten ML Infrastruktur nicht in Frage kommt.
Open-Source-Software
Die Einführung einer Open-Source-Lösung ermöglicht es Ihrem Unternehmen, die am besten geeignete Lösung auszuwählen und möglicherweise mehrere Alternativen zu testen. Die Auswahl verfügbarer Open-Source-Lösungen für Feature Stores ist derzeit allerdings noch gering.
Feast (von Feature Store) war die erste Open-Source-Lösung auf dem Markt und wird aktiv weiterentwickelt. Auf den ersten Blick wirkt Feast wie ein einfach zu bedienendes System, das gut in den Python Data Science Stack integriert ist und eine Vielzahl von Verbindungen zu Drittanbieterdiensten unterstützt. Da Azure seine integrierte Feature-Store-Lösung auf Grundlage dieses Projekts entwickelt und zum freien Quellcode beiträgt, scheint Feast langfristig gut aufgestellt zu sein.
Eine alternative Lösung ist der Feature Store von Hopsworks, der in ein größeres Machine Learning Operations-Framework integriert ist. Die Lösung von Hopsworks basiert auf bewährten Big-Data-Technologien wie Apache Spark und Apache Hudi und kann daher maximal skaliert werden. Die Skalierbarkeit geht auf Kosten der operationalen Komplexität, sodass eine lokale Testinstanz kaum aufgesetzt werden kann, wenn man nicht zumindest einem kleinen Kubernetes-Cluster zur Verfügung hat. Die gesamte Software ist sowohl aus Sicht der API als auch der Benutzeroberfläche gut zugänglich; übersichtliche Visualisierungen und die intuitive Navigation durch den Feature Store in einer webbasierten Oberfläche sind derzeit ein klarer Vorteil gegenüber Feast.
Laden Sie unser Whitepaper herunter und entdecken Sie das Potenzial von Künstlicher Intelligenz und Machine Learning!

Eigene Entwicklung
Wenn weder ein voll integriertes Produkt noch eine Open-Source-Lösung Ihre spezifischen Anforderungen erfüllen, kann die Entwicklung einer eigenen Lösung eine sinnvolle Alternative sein.
Die meisten datengesteuerten Unternehmen, die öffentlich über ihre Feature-Store-Lösungen gesprochen haben, haben sich für die Implementierung einer Inhouse-Lösung entschieden. Eine solche Lösung selbst zu entwickeln, stellt anfangs eine beträchtliche Investition dar. Es müssen entweder qualifizierte Entwickler*Innen in den eigenen Reihen stehen oder ein passender Entwicklungspartner gefunden werden. Die exakte Anpassung des entstehenden Systems an den bestehenden Systemkontext, die Prozesse und die Strategie kann zu einer deutlich höheren Benutzerzufriedenheit sowie zu einem geringeren Aufwand im Change Management und niedrigeren Wartungskosten führen.
Wir haben für unsere Kunden bereits Architekturlösungen für maschinelles Lernen implementiert, die bestehende Systeme als Feature Store wiederverwendet haben. In diesen Projekten haben wir mit einem geringen Aufwand an individueller Softwareentwicklung genau die vom Data Science Team benötigte Funktionalität hergestellt. In anderen Fällen kann die Entwicklung einer schlanken REST API als Harmonisierungsschicht alle Anforderungen eines Teams im Hinblick auf die Optimierung der Feature Engineering Prozesse erfüllen.
Beispiel: Integration von Feature Store und Apache Airflow
Das folgende Python Codebeispiel veranschaulicht, wie die Interaktion mit einem Feature Store abläuft, hier am Beispiel des Hopsworks Feature Stores und der dazugehörigen Python-Bibliothek "hsfs". Zunächst erstellen wir eine Feature Gruppe, die auf einem Pandas DataFrame Objekt basiert:
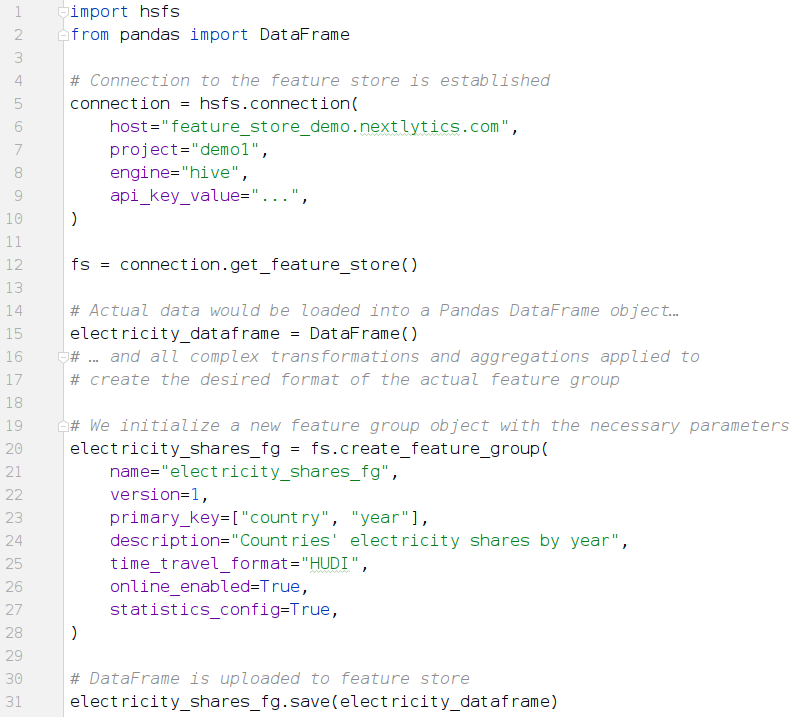 Python Codebeispiel 1: Wie einen neue Feature Group auf Basis eines Pandas DataFrame erzeugt
Python Codebeispiel 1: Wie einen neue Feature Group auf Basis eines Pandas DataFrame erzeugt
und im Hopsworks Feature Store gespeichert werden kann.
Der Beispielcode für die Erstellung und Registrierung von Features würde in einer eigenen Phase des gesamten Workflows isoliert werden. Das Abrufen der Daten aus dem Feature Store in der eigentlichen ML Entwicklung beschränkt sich anschließend auf drei einfache Anweisungen im Code, wie im zweiten Codeausschnitt gezeigt:
- Verbindung mit dem Feature Store herstellen (Zeilen 1-12)
- Zeigervariablen für die Feature Gruppen erzeugen (15-16)
- Abrufen der eigentlichen Daten, direkt im korrekten Format für die weitere Verarbeitung (19-24)
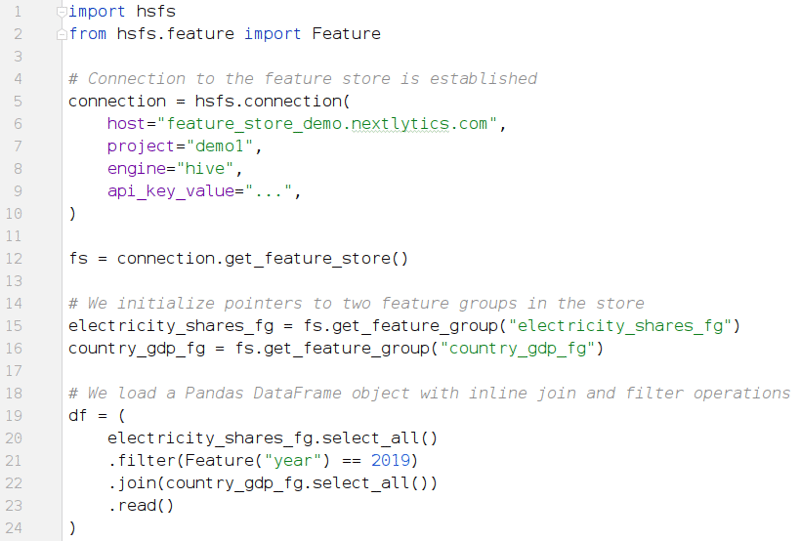 Python Codebeispiel 2: Wie Daten in wenigen Schritte direkt zusammengeführt, gefiltert und als DataFrame
Python Codebeispiel 2: Wie Daten in wenigen Schritte direkt zusammengeführt, gefiltert und als DataFrame
formatiert aus dem Hopsworks Feature Store geladen werden können.
Im gesamten ML Workflow wird das Erstellen, Registrieren, Hochladen und Aktualisieren von Merkmalen aus dem eigentlichen Code extrahiert, der ein ML Modell trainiert oder anwendet. Diese extrahierten Schritte bilden eine neue Phase von Feature Engineering Jobs. Diese Jobs können von jedem fähigen ETL-Orchestrierungstool verwaltet werden, z. B. von Apache Airflow als zentralem ML Workflow Controller.
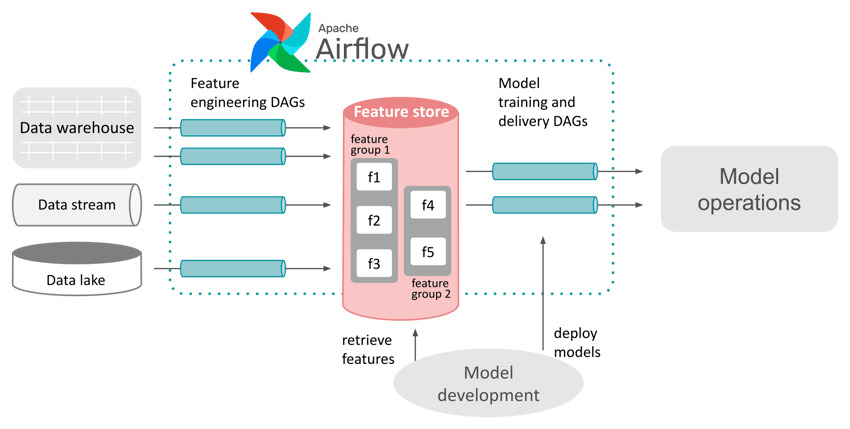 Apache Airflow kann genutzt werden um Feature Engineering Prozesse im gesamten
Apache Airflow kann genutzt werden um Feature Engineering Prozesse im gesamten
Machine Learning Entwicklungsprozess zu integrieren.
Unser Airflow-Beispiel zeigt, wie ein Feature Store in ein bestehendes Framework für Machine Learning integriert werden kann. Dieses Konzept funktioniert sowohl mit einer spezialisierten Feature Store Software als auch mit einer beliebigen hauseigenen Implementierung. Auf diese Weise können die Vorteile eines Feature Stores und einer dedizierten Feature Engineering Phase im ML Workflow für Ihr Unternehmen greifbar gemacht werden, relativ unabhängig von der bestehenden Architektur.
Machine Learning Framework - Unser Fazit
Der Feature Store ist ein spannender Trend in der Data Engineering und Machine Learning Community. Die Anbieter von Plattformlösungen haben das Potenzial erkannt und ihre Infrastruktur für Machine Learning um integrierte Feature Stores erweitert. Open Source Alternativen sind für den Eigenbetrieb sowie als Managed Services bei verschiedenen Anbietern verfügbar.
Die derzeitigen Feature Store Implementierungen befinden sich noch mitten im Reifungsprozess und werden schnell weiterentwickelt. Um den maximalen Nutzen aus dem Feature Store Konzept zu ziehen, kann auch eine maßgeschneiderte Inhouse-Lösung eine sinnvolle und schnelle Lösung für Ihr Unternehmen sein.
Der Erfolg der Einführung eines Feature Stores hängt maßgeblich von einer präzisen Analyse der Ausgangslage und Anforderungen sowie einer realistischen Einschätzung der Risiken und Vorteile der Implementierungsmöglichkeiten ab. Ein erfahrener Partner wie NextLytics kann Sie bei der Bewertung alternativer Lösungen unterstützen und Sie zur besten Entscheidung für Ihr Unternehmen führen.
Haben Sie weitere Fragen zu Feature Stores als Ergänzung zu Ihrer Data Science Infrastruktur oder benötigen Sie einen Implementierungspartner?
Wir unterstützen Sie gerne von der Problemanalyse bis zur technischen Umsetzung. Nehmen Sie noch heute Kontakt mit uns auf!


