/Logo%202023%20final%20dunkelgrau.png?width=221&height=97&name=Logo%202023%20final%20dunkelgrau.png)























Wenn Ihr Unternehmen wächst, wächst auch die Menge der Daten, die Sie anhäufen. Die Analyse der immer größer werdenden Datenmengen und die Gewinnung wertvoller Erkenntnisse daraus stellt jedes Datenteam vor große Herausforderungen: Die Verarbeitungszeiten und die Systemlast müssen so gering wie möglich gehalten werden und es muss sichergestellt werden, dass Ihre Data Pipelines sowohl planmäßig als auch fehlerfrei laufen. Die Verwendung von "Delta Loading" als Designprinzip für Data Pipelines kann dazu beitragen, Aktualität, Gültigkeit und Effizienz zu gewährleisten, sofern die Quellsysteme und Frameworks zur Datenverarbeitung diesen Ansatz unterstützen.
In diesem Beispiel wollen wir untersuchen, wie man mittels der Open-Source-Plattform für Workflow-Orchestrierung Apache Airflow eine Delta-Teilmenge von SAP BW-Daten, die über einen OData-Dienst bereitgestellt werden, verarbeiten kann. Während sich dieses Beispiel auf SAP BW konzentriert, sollte dieser Prozess in ähnlicher Weise auch für OData-Schnittstellen funktionieren, die von anderen SAP Systemen bereitgestellt werden.
Apache Airflow ist ein Open-Source-Orchestrierungsdienst, der häufig zur Erstellung, Planung und Überwachung von Data Pipelines verwendet wird. Mit ihm können Sie diese DAGs (Directional Acyclic Graphs) genannten Workflows mit der Programmiersprache Python erstellen.
Ein paar Worte zu OData
Die Bezeichnung OData steht für das Open Data Protocol, ein standardisiertes Protokoll zur Bereitstellung und Nutzung relationaler Daten als RESTful API, das ursprünglich von Microsoft im Jahr 2007 entwickelt wurde. Heutzutage ist die Version 4.0 bei OASIS standardisiert und als internationaler Standard anerkannt.
SAP BW ermöglicht die Nutzung des OData-Protokolls, um InfoProvider wie InfoCubes, DataStore-Objekte oder InfoObjects als OData-Dienste für Clients außerhalb von SAP bereitzustellen. Diese OData-Dienste können auf verschiedene Weise konfiguriert werden, unter anderem auch so, dass sie die Extraktion eines Deltas der angeschlossenen Datenquelle ermöglichen, wodurch der Benutzer die Änderungen in den Daten seit der letzten Datenextraktion abrufen kann. Dies ist eine große Hilfe bei der Arbeit mit Datenquellen, die große Datenmengen enthalten, da es dazu beiträgt, die Ausführungszeiten von Data Pipelines so gering wie möglich zu halten.
Verwendung des OData-Protokolls zur Extraktion von SAP BW-Daten
In diesem Artikel werden wir einen Airflow-DAG entwerfen, um den Inhalt eines SAP BW DataStore über den oben erwähnten OData-Provider zu extrahieren. Dieser DAG extrahiert den gesamten Inhalt des DataStore bei der ersten Ausführung, wobei alle vorhandenen Daten kopiert werden. In jedem weiteren Durchlauf wird anschließend nur das Delta geladen. In diesem Beispiel werden die extrahierten Daten in einer separaten Postgres-Datenbank gespeichert, mit einer zusätzlichen Tabelle, in der Metadaten über das Laden der Daten sowie der API-Endpunkt zum Extrahieren des Deltas für die nächste Prozessausführung gespeichert werden.
Wir werden die TaskFlow API von Airflow verwenden, um die DAG zu definieren und zu strukturieren, sowie die Python-Bibliotheken "Pandas" für die Verarbeitung von Datenobjekten, "SQLAlchemy" für die Verbindung mit der Postgres-Datenbank und "requests" für die Kommunikation mit dem OData-Dienst.
Der DAG selbst ist wie folgt strukturiert:
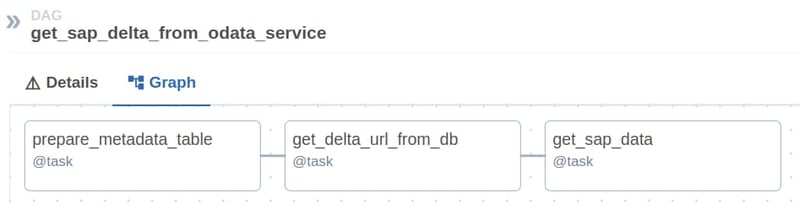
Bei der Initialisierung des DAG werden die Anmeldeinformationen für die Verbindungen sowohl mit dem OData-Dienst als auch mit der Postgres-Instanz aus den zuvor konfigurierten Airflow-Verbindungsobjekten geladen.
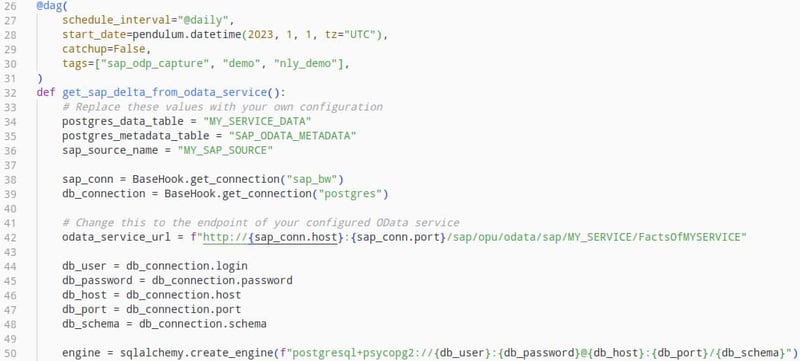
Im ersten Task wird die Struktur für die Metadatentabelle erstellt, in der die Pipeline-Ausführungen dokumentiert und die wichtigsten Metriken gespeichert werden.
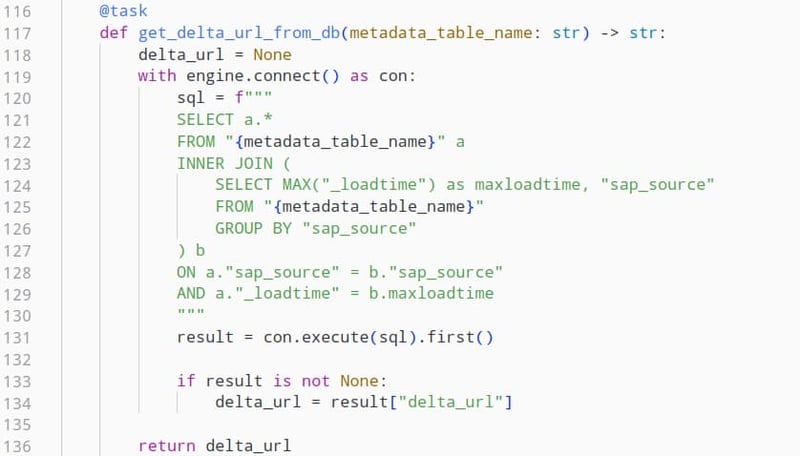
Im zweiten Task werden wir diese Metadatentabelle mit SQL abfragen und das Feld "delta_url" aus der letzten Ausführung der Pipeline für diese OData-Quelle extrahieren. Dies wiederum ermöglicht es uns, das entsprechende Delta von unserem OData-Dienst zu erhalten. Wird diese Pipeline zum ersten Mal ausgeführt, ist dieser Wert nicht vorhanden, was den weiteren Prozessschritt darüber informiert, dass wir eine initiale Datenladung durchführen müssen.
Jetzt können wir mit der eigentlichen Datenextraktion beginnen.
Effektives Workflowmanagement mit
Apache Airflow 2.0

Interaktion mit der SAP BW OData API
Die OData-API eines SAP-Datenproviders ist als RESTful-API implementiert und stellt die Inhalte der HTTP-Antworten im JSON-Format bereit. Dies ermöglicht es uns, die Daten einfach einzulesen und die relevanten Felder für unseren Anwendungsfall zu extrahieren.
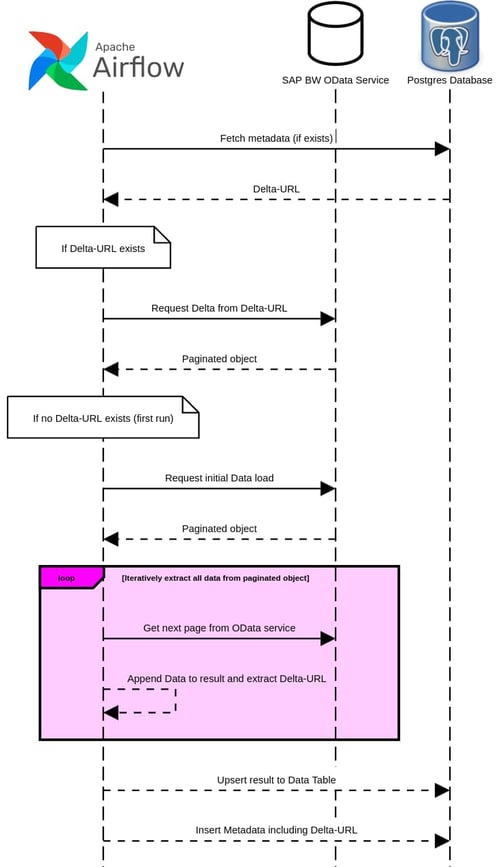
Um die Größe der Antwortmengen überschaubar zu halten, stellt diese API die Daten in einem paginierten Format bereit. Das heißt, wenn eine große Menge an Daten angefordert wird, enthält die erste Antwort nur eine Teilmenge dieser Daten sowie ein Feld mit einem anderen API-Endpunkt namens "__next", der die nächste Teilmenge an Daten enthält. Dies gilt auch für die erneute Abfrage des genannten Endpunkts, bis alle Daten übertragen wurden. In diesem Fall enthält die Antwort ein Feld namens "__delta", das den API-Endpunkt für die Abfrage des Deltas für die nächste Pipeline-Ausführung enthält.
Dieser Mechanismus ist für das Verständnis der Funktionsweise des nächsten Schritts der Data Pipeline relevant, da nur durch die iterative Abfrage der OData-API sichergestellt werden kann, dass alle abzufragenden Daten extrahiert werden, ohne die Systemleistung zu beeinträchtigen oder Datenverluste aufgrund von HTTP-Anfrage-Timeouts zu riskieren.
Der folgende Task führt die Datenextraktion aus, wobei dieser Vorgang geringfügig variiert, abhängig davon, ob der Datenprovider zum ersten Mal extrahiert wird oder nur ein Delta der Daten verarbeitet wird.
In beiden Fällen liefert dieser Vorgang sowohl einen Pandas-Dataframe, in dem die Daten enthalten sind, als auch den API-Endpunkt zur Abfrage des Deltas bei der nächsten Pipeline-Ausführung.
Die Interaktion mit dem OData-Dienst selbst funktioniert wie folgt:
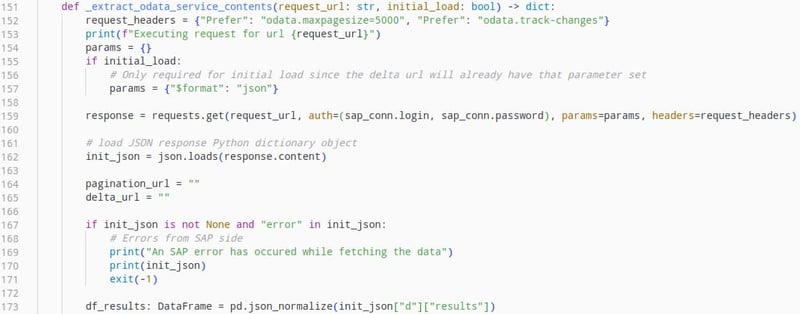
Dadurch wird die Antwort auf die ursprüngliche Anfrage als Dataframe geladen, und wir können mit dem Verarbeiten der Daten fortfahren.
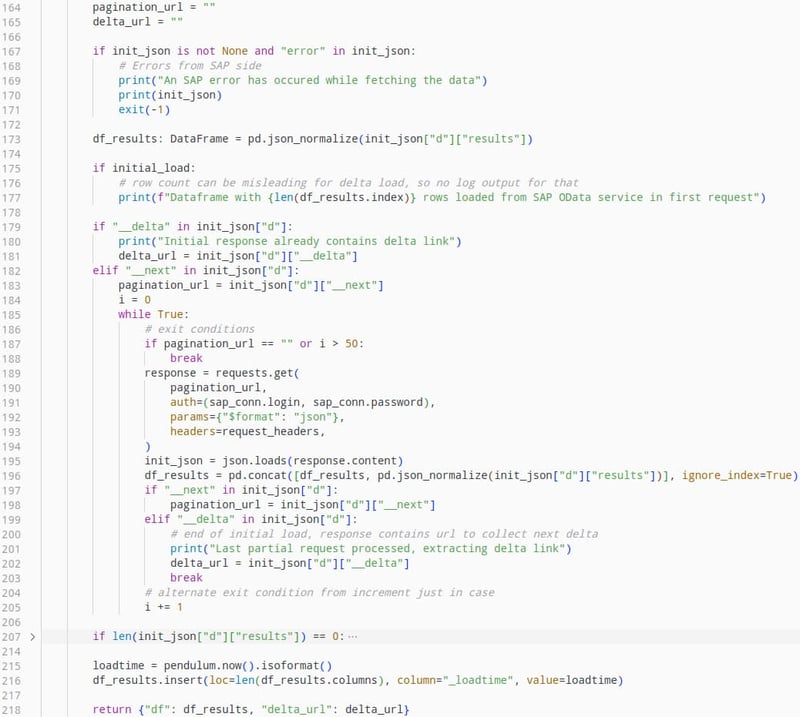
Dieser Teil des Codes extrahiert iterativ die paginierten Daten und fügt sie an einen Datenframe an. Außerdem wird eine separate Metadatenspalte hinzugefügt, in welcher der Abrufzeitpunkt der Daten dokumentiert wird.
Diese Daten können dann in unsere Zieldatentabelle geschrieben werden. Im Falle einer initialen Datenübertragung müssen lediglich alle Daten eingefügt werden. Wird dagegen ein Delta-Load ausgeführt, muss ein Upsert*-Mechanismus vorhanden sein, der das Schreiben der Datenbank für neu eingefügte Daten sowie für die seit der letzten Pipeline-Ausführung aktualisierten oder gelöschten Zeilen übernimmt.
(*Der Begriff "Upsert" ist ein Kofferwort aus der Kombination der Wörter "Update" und "Insert".)
Um korrekt zu ermitteln, zu welcher Kategorie die Daten gehören, können wir das Feld "ODQ_CHANGEMODE" nutzen, das Teil der Delta-Load-Antwort ist, die wir vom OData-Dienst erhalten haben. Diese Werte können "D" für gelöschte Zeilen, "C" für neu erstellte Zeilen und "U" für aktualisierte bestehende Zeilen sein.
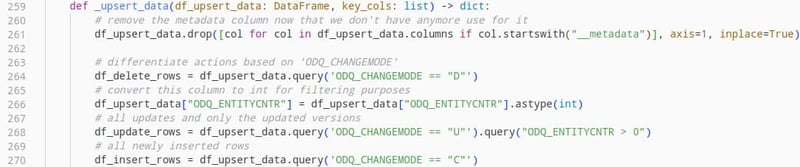
Jetzt müssen nur noch die voneinander getrennten Dataframe-Objekte in die Zieldatenbank geschrieben werden, wobei die jeweils auszuführende Operation zu berücksichtigen ist.
Dokumentieren von Datenverarbeitungsprozessen mit relevanten Metadaten
Nachdem unsere Daten nun geschrieben wurden, besteht der letzte Schritt darin, einen Eintrag in der Metadatentabelle zu erstellen, die wir zu Beginn dieses DAGs angelegt haben. Zu diesem Zweck haben wir die Anzahl der eingefügten, aktualisierten und gelöschten Zeilen sowie den API-Endpunkt für den nächsten Delta-Load erfasst.
Apache Airflow für die Erfassung von SAP Änderungsdaten - Unser Fazit
In diesem Beispiel haben wir die Leistungsfähigkeit des OData-Standards sowie die Möglichkeiten untersucht, wie Sie Apache Airflow verwenden können, um Ihre Data Pipelines zu strukturieren. Dieser Prozess gilt nicht allein für die OData-Dienste von SAP BW und kann auf ähnliche Weise auch für andere SAP-Produkte wie SAP S/4HANA eingesetzt werden.
Die mit dieser Pipeline gesammelten Daten können nun verwendet werden, um weitere betriebswirtschaftliche Erkenntnisse zu gewinnen. Wir könnten zum Beispiel Verkaufsdaten für ein bestimmtes Produkt verwenden, um ein optisch ansprechendes Dashboard mit Apache Superset zu gestalten.
Den gesamten Code für diese DAG finden Sie hier. Wenn Sie Fragen zu dieser Implementierung haben oder wenn Sie sich fragen, wie Sie Apache Airflow nutzen können, um Ihr datengetriebenes Geschäft zu optimieren, helfen wir Ihnen gerne. Kontaktieren Sie das Data Science and Engineering Team bei Nextlytics noch heute.


