/Logo%202023%20final%20dunkelgrau.png?width=221&height=97&name=Logo%202023%20final%20dunkelgrau.png)























Bei SAP BW Ladeprozessen kommt es des Öfteren zu Abbrüchen aufgrund fehlerhafter Datensätze. Um diese Abbrüche zu vermeiden, ist eine entsprechende Fehlerbehandlung sinnvoll. Grundsätzlich existieren zwei Möglichkeiten, die Fehlerbehandlung in SAP BW HANA Systemen abzubilden. In diesem Beitrage erläutere ich die einzelnen Szenarien im Detail.
So können Sie als erstes auf das DTP Error Handling zurückgreifen. Eine andere Herangehensweise wäre die automatische Korrektur der fehlerhaften Datensätze. Im ersten Szenario können Sie von automatischen Abläufen eines SAP Systems profitieren. Allerdings ist dabei eine flexible Weiterverarbeitung nicht möglich. Das zweite Szenario ist zwar mit mehr Entwicklungsaufwand verbunden, allerdings können Sie flexibler mit den fehlerhaften Datensätzen umgehen. So können Sie innerhalb von Transformationsroutinen automatische Prüfungen einbauen und Korrekturen durchführen.
Nachfolgend gehe ich zunächst auf das DTP Error Handling ein und erläutere die Funktionsweise des Errorstacks. Anschließend zeige ich Ihnen, wie Sie automatische Korrekturen mit SQLScript durchführen können.
Erstes Szenario - DTP Error Handling und manuelle Korrektur im Errorstack
Im ersten Szenario nutzen wir die Mechanismen des DTP Errorhandlers. Hier schreibt man die fehlerhaften Sätze in den Fehler-Stack, wo sie anschließend manuell korrigiert werden können.
Beachten Sie dabei, dass standardmäßig jede Transformation in zwei Durchläufen ausgeführt wird. Zuerst werden die fehlerhaften Datensätze herausgefiltert. Anschließend wird auf die verbliebenen, korrekten Daten die eigentliche Logik der Routine angewendet.
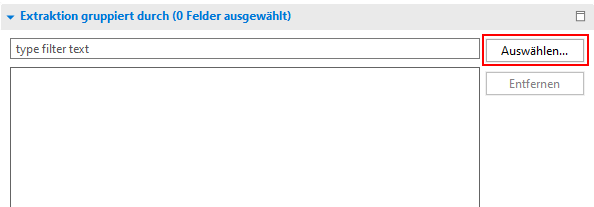
Bei der Ermittlung von fehlerhaften Sätzen spielt die semantische Gruppierung eine wichtige Rolle. So können Sie über die Einstellung Extraktion gruppiert durch im DTP Reiter Extraktion Felder definieren, die als Schlüssel für die Fehlerbehandlung dienen. Nachdem ein fehlerhafter Datensatz identifiziert wurde, werden alle Datensätze mit dem gleichen Schlüsselwert ebenfalls in den Errorstack verschoben.
Nachfolgend erläutere ich die Bedeutung der semantischen Gruppen anhand eines Beispiels. Betrachten wir die folgende Tabelle. Diese stellt verschiedene Bestellungen dar, die jeweils mehrere Bestellpositionen beinhalten:
| Bestellung | Bestell-Position | Belegtyp | Menge |
| 1337 | 10 | F | 48 |
| 1337 | 20 | F | 32 |
| 1338 | 10 | L | 74 |
| 1338 | 20 | 58 | |
| 1338 | 30 | L | 20 |
Bei der Bestellung mit der Nummer 1338 fehlt bei der Position 20 der Belegtyp, womit dieser Datensatz als fehlerhaft gilt:
| Bestellung | Bestell-Position | Belegtyp | Menge |
| 1337 | 10 | F | 48 |
| 1337 | 20 | F | 32 |
| 1338 | 10 | L | 74 |
| 1338 | 20 | 58 | |
| 1338 | 30 | L | 20 |
Mithilfe der semantischen Gruppierung kann die gesamte Bestellung als fehlerhaft gekennzeichnet werden:
| Bestellung | Bestell-Position | Belegtyp | Menge |
| 1337 | 10 | F | 48 |
| 1337 | 20 | F | 32 |
| 1338 | 10 | L | 74 |
| 1338 | 20 | 58 | |
| 1338 | 30 | L | 20 |
Diese Datensätze werden herausgefiltert und in den Fehlerstack geschrieben:
| Bestellung | Bestell-Position | Belegtyp | Menge |
| 1338 | 10 | L | 74 |
| 1338 | 20 | 58 | |
| 1338 | 30 | L | 20 |
Anschließend wird im zweiten Durchlauf die eigentliche Logik der Routine auf die verbliebenen Datensätze angewendet:
| Bestellung | Bestell-Position | Belegtyp | Menge |
| 1337 | 10 | F | 48 |
| 1337 | 20 | F | 32 |
Mithilfe der Fehlerbehandlung stellen Sie sicher, dass nur die korrekten Datensätze ins System gebucht werden. Die inkonsistenten Datensätze können manuell korrigiert und mithilfe eines Fehler-DTPs verbucht werden.
Der Nachteil dieses Szenarios ist, dass die Daten zweimal prozessiert werden, was in längeren Ladezeiten resultieren kann. Dies fällt vor allem bei Routinen für einzelne Felder ins Gewicht, da die kompletten Daten ein weiteres Mal verarbeitet werden. Das bedeutet, dass die Laufzeit bei n verwendeten Feldroutinen um Faktor n+2 verlängert wird. Aus diesem Grund sollten Sie auf Feldroutinen verzichten und stattdessen eine Endroutine verwenden.
Darüber hinaus ist auch der Fehler DTP erst mit BW/4HANA 2.0 verwendet. Mit BW/4HANA 1.0 und BW 7.5 on HANA kann das Error Handling für die HANA-Laufzeit nicht verwendet werden. Wenn Sie bereits ein BW/4HANA 2.0 im Einsatz haben und diese Lösung nutzen möchten, sollten Sie den Einsatz dieser Lösung unter dem Performance-Aspekt kritisch prüfen. Alternativ können Sie das zweite Szenario in Betracht ziehen, welches wir im nachfolgenden Absatz erläutern.
Steigern Sie die Leistung Ihres BW mit SQLScript

Zweites Szenario - Automatische Korrektur von fehlerhaften Datensätzen
Dieses Szenario unterscheidet sich grundsätzlich von der ersten Methode. Anstatt die fehlerhaften Datensätze im Error Stack zu sammeln, geht es darum, die fehlerhaften Sätze flexibel weiterverarbeiten zu können.
So können Sie zum Beispiel in den Ziel-InfoProvider ein Feld aufnehmen, welches als Statusindikatior dient. Mit diesem Flag können Sie die fehlerhaften Datensätze kennzeichnen. Gegebenenfalls können Sie dort auch die Fehlerart hinterlegen, um spätere Fehlerbehandlung zu erleichtern.
Grundsätzlich werden also alle Datensätze fortgeschrieben, wobei die fehlerhaften Sätze mit einem Flag versehen werden. Dieses Vorgehen hat den Vorteil, dass Berichte auch fehlerhafte Sätze einbeziehen können. Über das Feld Statusindikator können Sie steuern, ob die Datensätze mit Fehlern angezeigt oder herausgefiltert werden sollen.
Um die fehlerhaften Sätze zu korrigieren, können Sie eine Transformation verwenden, die in den Ziel-InfoProvider selbst schreibt und automatische Korrekturen vornimmt. Eine andere Möglichkeit wäre es, die Daten in ein anderes DataStore Objekt zu verbuchen, um dort die Daten mit einem eigenen UI (wie z. B. NextTables) zu bearbeiten. Dabei können Sie auf die Funktionen RSDRI_INFOPROV_READ und RSDSO_WRITE_API bzw. RSDSO_DU_WRITE_API als APIs zurückgreifen. Anschließend können Sie die korrigierten Daten in den eigentlichen Ziel-InfoProvider zurückschreiben oder anderweitig verarbeiten.
Wenn Sie die fehlerhaften Datensätze nicht in einem DSO zwischenlagern möchten, existiert eine weitere Alternative. So können Sie die fehlerhaften Datensätze auch direkt in der Transformation, ohne Ablage in einem DSO, korrigieren. Wie es mithilfe von SQLScript funktioniert, erfahren Sie in einem weiteren Artikel, den wir in dieser Reihe noch veröffentlichen werden.
Möglichkeiten zur Fehlerbehandlung - Unser Fazit
Je nach Anforderungsprofil ist das erste oder das zweite Szenario sinnvoller.
Beim ersten Szenario stellen Sie sicher, dass nur die konsistenten Datensätze verbucht werden. Dieses Szenario kommt allerdings erst ab der Version BW/4HANA 2.0 in Frage. Das Einsatzszenario sollte hinsichtlich der Performance genau getestet werden, da die Daten doppelt verarbeitet werden. Sie können hier die Standardfunktionalität der SAP nutzen, aber sind auch an deren Möglichkeiten gebunden. So können Sie die inkorrekten Datensätze nur manuell korrigieren und anschließend mit einem Fehler-DTP laden.
In unserem nächsten Artikel, den wir in dieser Reihe veröffentlichen werden, gehen wir dann im Detail auf dieses Szenario ein und liefern hilfreiche SQLScript Coding Snippets für die Umsetzung.
Beim zweiten Szenario haben Sie eine höhere Flexibilität - Ihnen stehen mehr Möglichkeiten zur Verfügung, die inkonsistenten Daten zu verarbeiten. Ob Sie dabei die fehlerhaften Sätze zunächst in einem DSO hinterlegen oder on-the-fly korrigieren, hängt von den individuellen Anforderungen ab. Allerdings entfernen Sie sich dabei vom SAP-Standard und sind auf Eigenentwicklungen angewiesen. Beide Alternativen beleuchten wir in den später folgenden Beiträgen ausführlich.
Planen Sie einen Umstieg auf SQLScript und benötigen Sie Unterstützung bei der Planung der richtigen Strategie? Oder benötigen Sie erfahrene Entwickler zur Umsetzung Ihrer Anforderungen? Zögern Sie bitte nicht, uns zu kontaktieren - wir beraten Sie gerne.


