/Logo%202023%20final%20dunkelgrau.png?width=221&height=97&name=Logo%202023%20final%20dunkelgrau.png)























Mit SAP Databricks, das inzwischen fest in die SAP Business Data Cloud integriert ist, gehen viele Unternehmen über reine Feature-Listen hinaus und stellen sich strategischere Fragen: Wie funktioniert der Datenaustausch über Systemgrenzen hinweg? Welche tatsächlichen Kosten entstehen beim Betrieb von Databricks? Und wie wirken sich diese Faktoren auf Ihre langfristigen Architekturentscheidungen aus?
Im ersten Teil unseres Vergleichs haben wir den Funktionsumfang von SAP Databricks und Enterprise Databricks untersucht und erläutert, wie sich die beiden Varianten hinsichtlich Plattformbetrieb und technischer Flexibilität unterscheiden. Im zweiten Teil richten wir den Fokus auf die zugrunde liegende Datenarchitektur und die wirtschaftlichen Aspekte. Wir werfen einen genaueren Blick auf Zero-Copy Data Sharing über Delta Sharing, vergleichen die jeweiligen Kostenmodelle und geben Ihnen strategische Orientierung, die Ihnen bei der Entscheidung zwischen SAP Databricks und Enterprise Databricks hilft.
Zero-Copy Data Sharing
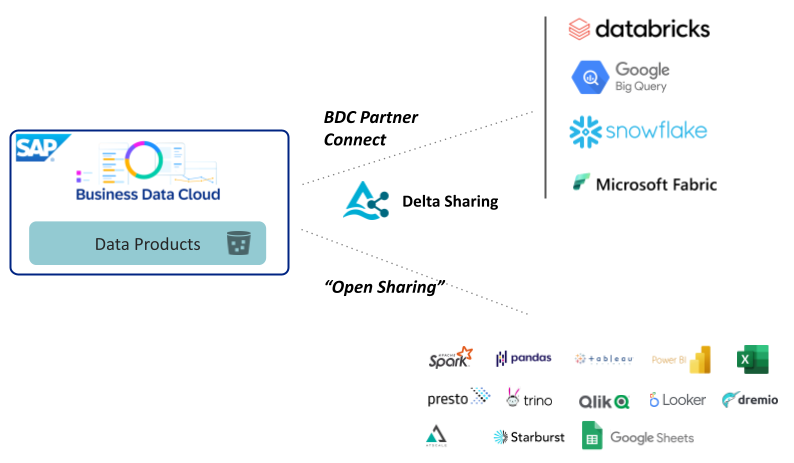
Die große technologische Neuerung in SAP Business Data Cloud ist sicherlich die tiefgehende Integration von Data Lake Storage in die Plattform. In einer solchen Data Lakehouse Architektur werden Storage- und Compute-Ressourcen entkoppelt, was es dem System erlaubt, dynamisch und kosteneffizient zu skalieren. Gegenüber der klassischen In-Memory Datenbank benötigt ein solches System z.B. nicht dauerhaft große Arbeitsspeicherkapazitäten. Das sogenannte Zero-Copy Data Sharing ist eine Folge dieser Architektur: Um auf Daten im Storage zuzugreifen, muss nicht zwingend immer die gleiche Compute-Ressource genutzt werden. Es ist möglich, unterschiedliche Query Engines auf die gleichen Daten zugreifen zu lassen, ohne diese zu replizieren. Insbesondere können somit auch kompatible Drittsysteme auf die Daten zugreifen, sofern Authentifizierung und Autorisierung technisch ausgehandelt werden.
Genau diese technische Verhandlung von Zugriffsberechtigungen übernimmt das Delta Sharing Protokoll, das maßgeblich von Databricks entwickelt wurde. SAP Business Data Cloud unterstützt das Protokoll und ermöglicht auf diese Weise nicht nur den wechselseitigen Zugriff auf Datenobjekte zwischen Datasphere und SAP Databricks innerhalb der Plattform, sondern auch Datenaustausch mit Drittsystemen.
Den Austausch von Daten über Delta Sharing mit Drittsystem nennt SAP “BDC Connect”. Enterprise Databricks, Google BigQuery, Snowflake und Microsoft Fabric sind bereits als kompatible Drittsysteme von der SAP angekündigt worden.
SAP Databricks unterscheidet sich hinsichtlich Delta Sharing Funktionalität von Enterprise Databricks: während die vollwertige Databricks Plattform bereits mit vielen Drittsystemen kompatibel ist und je nach Verfügbarkeit der entsprechenden Konnektoren auf der Gegenseite den Datenaustausch bidirektional erlaubt, beschränkt SAP Databricks die Konnektivität auf eingehende Datenfreigaben. So kann ein SAP Databricks Workspace also Daten aus einer Delta Sharing Freigabe beliebiger technisch mit dem Protokoll kompatibler Datenquellen lesen. Ausgehende Datenfreigaben können aus SAP Databricks heraus jedoch nur in Richtung der SAP BDC Umgebung erstellt werden.
Zero-Copy Data Sharing verheißt allgemein eine spannende Zukunft, in der große, verteilte Unternehmensplattformen weniger Aufwand für die Synchronisierung von Daten über die verschiedenen Teilsysteme hinweg erfordern. Ein zentraler Aspekt in solchen Landschaften ist allerdings immer die Frage des einheitlichen Berechtigungsmanagement - und diese wird vom Delta Sharing Protokoll nicht beantwortet.
Sehen Sie sich die Aufzeichnung unseres Webinars an: "Bridging Business and Analytics: The Plug-and-Play Future of Data Platforms"

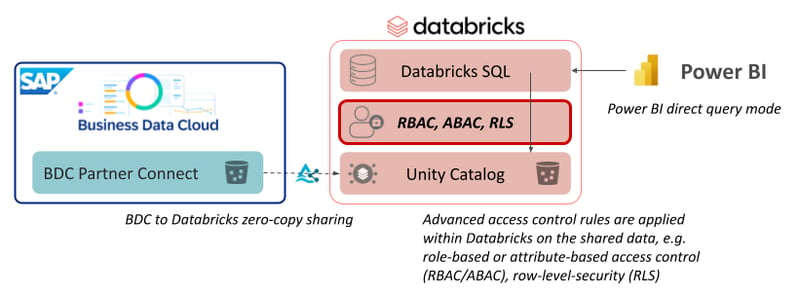
Eine Freigabe mittels Delta Sharing kann vereinfacht als Leseberechtigung auf alle Daten in einer Tabelle betrachtet werden. Erweiterte Zugriffsrechte basierend auf zusätzlichen Attributen, z.B. zeilenweise (Row-Level Security) oder spaltenweise (Column Masking) rollenbasierte (Role-based Access Control) Zugriffsrechte je nachdem ob ein Benutzer ein bestimmtes Attribut oder eine bestimmte Rolle zugewiesen bekommen hat, können mittels Delta Sharing nicht an das empfangene System übermittelt werden. Solche Zugriffskonzepte werden ab einer gewissen Komplexität und Größe einer Datenlandschaft benötigt und müssen aktuell in den verschiedenen Systemen, die auf einen gemeinsamen Datensatz zugreifen, jeweils mit der eigenen Query Engine explizit implementiert werden.
Diese Einschränkung gilt ausdrücklich sowohl für Datenfreigaben zwischen SAP BDC und SAP Databricks als auch für BDC und Enterprise Databricks.
Kostenvergleich
Wenn zwei Werkzeuge miteinander verglichen werden sollen, führt kein Weg an der Betrachtung zu erwartender Kosten vorbei. Databricks folgt dabei grundsätzlich einem “Pay Per Use” Kostenmodell, sodass nur tatsächlich genutzte Ressourcen dynamisch in Rechnung gestellt werden. Dazu kommen Kosten für die genutzte Infrastruktur auf dem jeweiligen Hyperscaler.
Wie setzen sich die Kosten für Enterprise Databricks zusammen?
Enterprise Databricks verrechnet genutzte Ressourcen in die sogenannten “Databricks Units”, DBU, die letztlich als eine Art on-demand Lizenzgebühr in Rechnung gestellt werden. Als Faustformel taugt dabei, Kosten von 1 EUR pro DBU pro Stunde anzunehmen, was bereits die Betriebskosten für die zugehörigen virtuellen Maschinen beinhaltet, die zusätzlich zu den DBU-Listenpreisen vom Hyperscaler in Rechnung gestellt werden. In Databricks selbst sowie im Kostenmonitoring der Hyperscaler kann sehr granular nachvollzogen werden, welche Ressourcen in welchem Zeitraum welche Kosten verursacht haben. Diese weitgehende Transparenz ermöglicht gezielte Optimierung insbesondere von automatisierten Prozessen und effiziente Skalierung von Compute-Clustern.
Kosten für den genutzten Storage sowie Netzwerklast stellt der Hyperscaler in Rechnung. Hier gilt: Storagekosten skalieren etwa linear und es gibt Optionen für Mengenrabatte, während bei den Ingress- und Egresskosten Vorsicht geboten ist. Sehr große Datenmengen in einem kurzen Zeitraum über die Systemgrenzen des Cloud-Anbieters zu bewegen kann zusätzliche Kosten verursachen.
Wie verrechnet SAP die Kosten für SAP Databricks?
Die Kostenrechnung für SAP Databricks ist weniger transparent oder zumindest eine Größenordnung abstrakter. Bezahlt wird für SAP “Capacity Units” (CU), die für die gesamte BDC Umgebung als Guthaben vorab gekauft werden und dann je nach Nutzung aus dem vorhandenen CU-Kontingent abfließen. In die anfallenden CU für SAP Databricks gehen sowohl die DBU-Kosten als auch die Infrastrukturbetriebskosten ein. Im SAP CU-Kapazitätsrechner müssen für den Betrieb von SAP Databricks somit vorab bereits unterschiedliche Kontingente für Storage, Compute und Netzwerklast geschätzt werden. Die Abrechnung erscheint somit einfacher, erlaubt gleichzeitig aber auch weniger konkrete Optimierung. Am Ende des Tages gilt für die tatsächlichen Kosten wie immer bei SAP-Produkten: der Endkunde verhandelt einen individuellen Preis mit der SAP, volle Transparenz ist nicht gegeben.
Eine konkrete Kostenprognose für die Nutzung von Databricks jedweder Ausprägung ist immer eine individuelle Berechnung anhand konkreter (geschätzter) Betriebsparameter für einen spezifischen Verwendungszweck. Sofern Databricks regelmäßig von mehreren Benutzern für produktive Zwecke genutzt wird, dürfte Enterprise Databricks aufgrund der feineren Konfigurations- und Kontrollmechanismen sowie der direkten Abrechnung gegenüber Hyperscaler und Databricks günstiger ausfallen.
Enterprise Databricks vs. SAP Databricks: Unser Fazit und Ausblick
Wir haben SAP Databricks und Enterprise Databricks hinsichtlich ihres Funktionsumfangs, der unterschiedlichen Betriebsaufwände und der Kostenstruktur verglichen. Darüber hinaus haben wir unsere Erkenntnisse zu den Möglichkeiten und Einschränkungen von Zero-Copy Data Sharing in den beiden Systemvarianten dargelegt. Das Fazit bleibt: SAP Databricks ist eine deutlich eingeschränkte Light-Version von Enterprise Databricks mit vereinfachten Betriebs- und Abrechnungsmodi für SAP Kunden.
SAP Databricks hat das Potenzial, in den kommenden Jahren tatsächliche funktionale Schwerpunkte zu entwickeln, die den Einsatz in einer integrierten SAP Business Data Cloud attraktiver machen. Ein voll integriertes Autorisierungsframework liegt nahe, das komplexe rollen- und attributbasierte Zugriffsregeln auf Zeilenebene über Datasphere, SAC und SAP Databricks hinweg ohne zusätzlichen Programmieraufwand vereinheitlicht. Auch echte, durchgängig vereinheitlichte Data Governance über alle Systemkomponenten in einem integrierten Enterprise Data Catalog ist eine Chance für die SAP.
Anfang 2026 sehen wir SAP Databricks jedoch vor allem als eine komfortable Entwicklungsumgebung für bestimmte Nischen: die Entwicklung individueller Machine Learning Applikationen auf Daten, die bereits vollständig in der SAP-Welt vorliegen; komplexe Data Pipelines, die mit Datasphere Bordmitteln schlecht oder ineffizient umgesetzt werden können; komplexe Auswertungen über Daten, die aus organisatorischen Gründen nicht außerhalb der SAP-Systemlandschaft verarbeitet werden dürfen.
Abschließend zeigt sich, dass die Entscheidung zwischen SAP Databricks und Enterprise Databricks keine rein technische Fragestellung ist, sondern eine strategische Plattformentscheidung, die Architektur, Betriebsmodell und langfristige Skalierbarkeit maßgeblich beeinflusst. Um Entscheidungsträger:innen eine schnelle und fundierte Orientierung zu ermöglichen, haben wir die zentralen Erkenntnisse in einer One-Page Executive Comparison zusammengefasst. Sie fasst die wichtigsten Unterschiede und Abwägungen kompakt zusammen und unterstützt Sie dabei, einzuschätzen, welche Databricks-Variante am besten zu Ihren organisatorischen Prioritäten und strategischen Zielen passt.
Executive Comparison Matrix |
||
| Dimension | Enterprise Databricks | SAP Databricks |
| Strategische Rolle | Zentrale unternehmensweite Daten- und AI-Plattform | SAP-integrierte Erweiterung der Business Data Cloud |
| Funktionsumfang | Sehr hoch (vollständige Databricks-Plattform) | Begrenzt (Kernfunktionalitäten) |
| Operativer Aufwand | Hoch (DevOps, IaC, CI/CD erforderlich) | Sehr gering (vollständig durch SAP gemanagt) |
| Flexibilität & Erweiterbarkeit | Sehr hoch | Begrenzt durch Plattformdesign |
| Datenintegration | Umfassend (Low-Code-Connectoren, Streaming, Batch) | Grundlegend (primär programmatisch) |
| Zero-Copy Data Sharing | Vollständig, bidirektional | Eingehend vollständig, ausgehend auf BDC beschränkt |
| Kostentransparenz | Hoch (DBUs + Hyperscaler-Kosten klar nachvollziehbar) | Gering (SAP Capacity Units, abstrakte Abrechnung) |
| Kosteneffizienz im produktiven Betrieb | Hoch bei skalierter Nutzung | Oft geringer bei wachsendem Einsatz |
| SAP-Integration | Neutral | Nativ und tief integriert |
| Typische Zielgruppe | Unternehmen mit komplexen, systemübergreifenden Anforderungen | SAP-fokussierte Organisationen mit geringem Betriebsaufwand |
Wenn Sie bewerten möchten, welche Databricks-Variante am besten zu Ihrer Systemlandschaft, Ihren Use Cases und Ihrem Betriebsmodell passt, nehmen Sie gerne Kontakt mit uns auf. Wir unterstützen Sie bei der Evaluierung, Analyse und fundierten Entscheidungsfindung – vom ersten Assessment bis hin zu einem konkreten Architekturplan.


