/Logo%202023%20final%20dunkelgrau.png?width=221&height=97&name=Logo%202023%20final%20dunkelgrau.png)























Heute geht es um das Thema Datenmanagement in Ihrem HANA System und welche einfache Data Tiering Option Sie zur Verfügung haben, um wertvollen Arbeitsspeicher, mit der die HANA arbeitet, einzusparen. Nicht alle Objekte benötigen die Power des begrenzten Arbeitsspeichers. Erfahren Sie in diesem Blogbeitrag:
-
was NSE ist und wann es eingesetzt wird
-
wie einfach es in der Anwendung ist
-
wie viel Performanceeinbußen Sie haben (Wir haben nachgemessen)
-
Tipps und Tricks in der Anwendung.
Theorie - Was ist Native Storage Extension (NSE)?
SAP NSE wurde erstmals mit HANA 2.0 SPS04* eingeführt und und stellt erstmalig für viele Kunden eine einfache Möglichkeit zur Verfügung Daten aus dem Hauptspeicher auf die Festplatte auszulagern und dies sogar meist ganz ohne in neue Hardware zu investieren. Mit wenigen Schritten lässt sich mit dieser Data Tiering Technologie wichtiger Arbeitsspeicher der HANA Datenbank einsparen. NSE stellt dabei eine einfachere und aktuelle Alternative der zuvor bekannten Extension Node dar.
Multi-Temperature Data Management
Die folgende Grafik ordnet die Technologien entsprechend nach dem Konzept des Multi-Temperature Data Management ein.
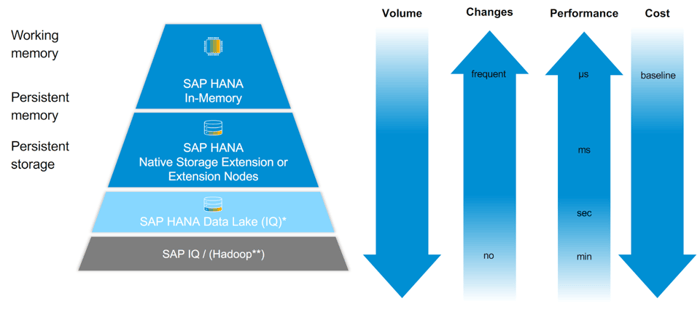
Multi-Temperature Data Management im Kontext von Volumen, Änderungshäufigkeit, Performance und Kosten
-
SAP HANA In-Memory bildet hierbei den “hot” Speicher.
-
SAP HANA Native Storage Extension oder Extension Node bilden den “warm” Speicher ab.
-
Als “Cold” Speicher fungiert SAP HANA Date Lake und SAP IQ.
In diesem Blogbeitrag beschäftigen wir uns mit der aktuellsten Lösung um einen “warm” Speicher zu implementieren.
NSE Implementierung
Die Implementierung von NSE ist dabei denkbar einfach. Musste man zuvor mit der Extension Node noch ein Scale Out System implementieren, was einen erhöhten Wartungsaufwand bedeutete, wird die Native Storage Extension einfach als Scale Up System implementiert und vertikal skaliert. Dabei ist NSE bereits ab der HANA 2.0 SPS04 verfügbar und mit SPS05 auch in der SAP BW/4HANA Modellierung einfach einsetzbar, wie in folgender Abbildung ersichtlich.
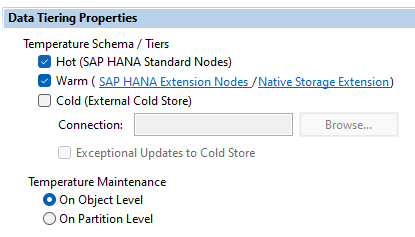
BW/4HANA: Data Tiering Optionen ab SPS05
Die Verwendung ist dabei out-of-the-box möglich und sehr flexibel. Sie können beliebige Datenspeicher wie z.B. aDSO jederzeit in den “warm” Speicher (“Page loadable”) überführen und genauso einfach auch wieder als “hot” Data (“column loadable”) verfügbar machen, sollten sich die Anforderungen an die Verfügbarkeit der Daten geändert haben. Dies ist entweder auf Objektebene oder auf Partitionsebene möglich.
Performance & der Buffer Cache
Die Query performance ist bei “warm” Data gegenüber “hot” Data leicht reduziert. “Page loadable“ Data wird in granularen Einheiten in den Arbeitsspeicher geladen wie es für Query-Verarbeitung erforderlich ist. Der Zugriff auf die Daten, z.B. für die Query Engine, ist dabei identisch. Um eine hohe Performance zu ermöglichen, wird ein sogenannter Buffer Cache genutzt, welcher standardmäßig 10% des gesamten “hot” Speichers allokiert. Über diesen werden angefragte Daten aus dem “warm” Speicher entsprechend gepuffert und stehen somit schneller für das Reporting verfügbar.
Hierbei sind einige Größenordnungen bei der Implementierung zu beachten, da das Volumen des “hot” Speichers maximal 4x und das des “warm” Speichers maximal 8x so groß wie das Volumen des Buffer Cache sein sollte.
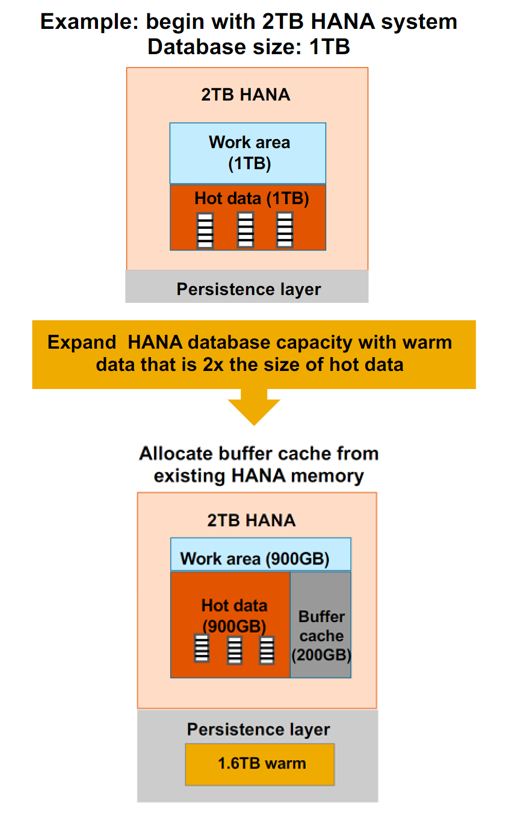
Beispielhafte Implementierung von NSE auf einer HANA Datenbank mit 2TB Speicher
Ein Vergleich von SAP BW, HANA Native und SAP DW-Cloud - Laden Sie sich hier das Whitepaper herunter!

NSE Advisor - Geeignete Einsparungspotentiale ermitteln
Um herauszufinden welche Datenspeicher ein großes Einsparungspotential an “hot” Speicher bieten, kann der sogenannte NSE Advisor genutzt werden. Hierbei sollen geeignete Objekte identifiziert werden. Dies bedeutet, dass unter repräsentativer Arbeitslast der NSE Advisor aktiviert wird um Leistung von Abfragen, Speichernutzung und Dauer der Prozesse zu prüfen. Ziel der Heuristik ist dabei:
- Objekte, die klein sind und auf die häufig zugegriffen wird, sollten im Speicher gehalten werden, um die Leistung zu verbessern.
- Objekte, die groß sind und auf die selten zugegriffen wird, sollten besser auf der Festplatte gespeichert werden, um den Speicherverbrauch zu verringern. Diese Objekte werden nur bei Bedarf und nur für die Seiten, auf die zugegriffen wird, in den Speicher geholt.
Ergebnis ist eine Vorschlagsliste mit Tabellen, welche Einsparungspotential bieten und in den “warm” Speicher überführt werden sollten. Die Erfahrung hat hierbei gezeigt, dass eine lange Laufzeit (z.B. eine Woche) des NSE Advisor zu besseren Ergebnissen führt. Für komplexe Fälle ist eine manuelle Analyse jedoch unabdingbar.
Testszenario - Sind Nachteile durch NSE spürbar?
Soviel zur Theorie über NSE, aber wie viel Speicher wird letztendlich gespart wenn NSE eingeführt und die Datentemperatur der aDSO entsprechend gepflegt wird? Sind Performanceeinbußen im Reporting bemerkbar?
Diesen Fragen sind wir für Sie auf den Grund gegangen und haben zwei aDSO vorbereitet, welche identisch aufgebaut sind und jeweils im “warm” Speicher und “hot” Speicher vorliegen.
Die beiden aDSO definieren sich dabei wie folgt:
- 1 Schlüsselfeld des Datentyps CHAR
- 24 weitere Felder des Datentyps CHAR
- 1 Kennzahl des Datentyps DEC
- 5 Millionen Zeilen Testdaten in der aktiven Datentabelle
Der aDSO mit der Bezeichnung Data-Temperature: hot wird dabei mit der Datentemperatur “hot” und Data-Temperature: warm mit der Temperatur “warm” gepflegt, wie im folgenden Screenshot ersichtlich wird. Die Größe ist dabei nahezu identisch, da keine weitere Komprimierung der Daten erfolgt.
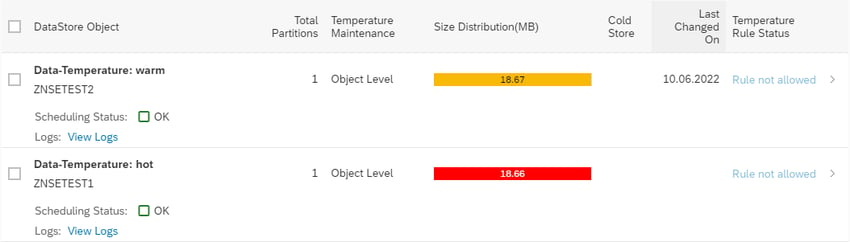
DTO-Cockpit: aDSO hot und aDSO warm im gepflegten Zustand
Um nun die Performance zu prüfen, wurde auf den beiden aDSO jeweils ein hinreichend komplexes Query angelegt, welches anschließend auf die Laufzeit überprüft werden kann. In BW/4HANA erfolgt die Auswertung über den Query CDS View “Rv_C_OlapStatAQuery”. Dieser View beinhaltet die relevanten Felder mit Laufzeitinformationen:
- TIMETOFRONTEND (Laufzeit Frontend)
- TIMEOLAP (Laufzeit OLAP)
- TIMEDM (Laufzeit Data Manager)
- TIMEPLAN (Laufzeit Planung)
Ergebnisse
Volle Verwendung des Buffer Cache
Die Queries wurden identisch oft über den Querymonitor gestartet. Die ermittelten Durchschnittswerte für den Durchlauf mit voller Verwendung des Buffer Cache ergeben sich wie folgt:
|
Bezeichnung |
Laufzeit Data Manager (in Sekunden) |
|
Hot Query |
0,221 |
|
Warm Query |
0,495 (+125%)* |
Ergebnisse mit voller Verwendung des Buffer Cache *(gerundet mit Hot Query als Basis)
Ohne volle Verwendung des Buffer Cache
In der nachfolgenden Testreihe wurde der Buffe Cache künstlich auf 5 Megabyte verkleinert, um den Zugriff auf die Festplatte ohne Buffer Cache zu erzwingen. Die ermittelten Durchschnittswerte ergeben sich dabei wie folgt:
|
Bezeichnung |
Laufzeit Data Manager (in Sekunden) |
|
Hot Query |
0,221 |
|
Warm Query |
0,527 (+138%) |
Ergebnisse ohne volle Verwendung des Buffer Cache *(gerundet mit Hot Query als Basis)
Bewertung der Ergebnisse
Aus den Ergebnissen des Tests geht hervor, dass die Performance unter der Verwendung von SAP NSE deutlich leidet. Ein Zugriff auf das Query über den Buffer Cache ist mit einer erhöhten Laufzeit von durchschnittlich 125 % und ohne volle Verwendung des Buffer Cache sogar mit 138 % verbunden.
Wissenswertes
Zur Überprüfung welche Objekte im Buffer Cache oder generell als “Page loadable” vorliegen gibt es einige nützliche DDL-Statements die auf der HANA Datenbank ausgeführt werden können.
|
-- Shows which Data is currently inside the buffer cache: |
NSE - Unser Fazit
Mit der Native Storage Extension ist eine einfache Möglichkeit vorhanden wertvollen Arbeitsspeicher der HANA einzusparen. Dieses Potential ist in jedem Fall, aber insbesondere auf den unteren Schichten des LSA++, zu betrachten.
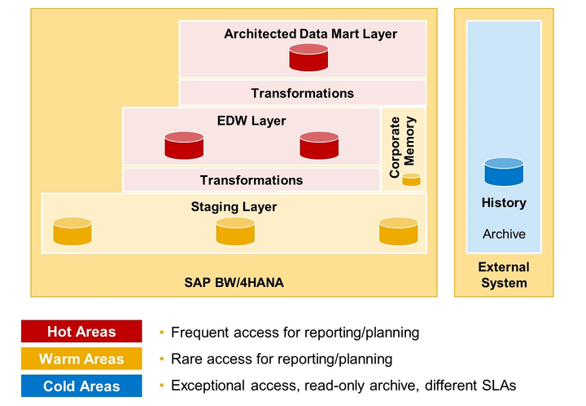
Multi-Temperature Data Management im LSA++ Kontext
Unsere Handlungsempfehlung liegt klar bei einer Implementierung auf der Schicht des Staging Layer oder Corporate Memory. Auf Schichten mit einem häufigen Zugriff auf Daten, die für das Reporting benötigt werden, müssen die Performanceaspekte durch Verwendung von SAP NSE unbedingt betrachtet werden, da diese je nach Szenario variieren können.
Die Implementierung von SAP NSE auf einem BW/4HANA System ist dabei einfach durchführbar und eine Analyse der eigenen Datenspeicher eine lohnenswerte Investition.
Haben Sie Fragen zu HANA Native Storage Extension oder zum Thema Multi-Temperature Data Management? Versuchen Sie das nötige Know-How in Ihrer Abteilung aufzubauen oder benötigen Sie Unterstützung bei einer konkreten Fragestellung? Wir helfen Ihnen gerne dabei. Fordern Sie noch heute ein unverbindliches Beratungsangebot an.


