/Logo%202023%20final%20dunkelgrau.png?width=221&height=97&name=Logo%202023%20final%20dunkelgrau.png)























Die Absatzplanung ist ein Top-Thema für jedes Unternehmen, das im Handel tätig ist. Die Gewinnung von Erkenntnissen über die voraussichtlichen Verkaufszahlen gilt als wichtige, aber auch schwierige Aufgabe. Durch effektive Absatzprognosen können Unternehmen ihre Ressourcen effizienter einsetzen und sicherstellen, dass Produktion und Lagerbestände optimal auf die Nachfrage abgestimmt sind. Präzise Absatzprognosen ermöglichen es Unternehmen auch, realistische Umsatzziele festzulegen, die für die Finanzplanung unerlässlich sind.
Im Laufe der Jahre wurden viele Methoden entwickelt, um genaue Absatzprognosen zu erstellen. Diese reichen von einfachen statistischen Modellen bis hin zu ausgefeilten Algorithmen des Machine Learnings, die in erster Linie für die Vorhersage von Zeitreihen konzipiert sind. ARIMA-Modelle sind seit vielen Jahrzehnten ein nützliches Instrument für Analysten und Forscher, deren Aufgabe es ist, dem Vertrieb oder dem Supply-Chain-Management Business Intelligence zu liefern. Darüber hinaus haben sich neuronale Netze bei der Anpassung an die sich ständig ändernde Natur von Zeitreihen als recht erfolgreich erwiesen, wobei die LSTM-Architektur die bekannteste ist.
In diesem Artikel stellen wir ein komplettes Framework für die Vorhersage von Verkaufszeitreihen vor, vergleichen verschiedene Modelle und Methoden, erstellen Diagramme und Berichte und nutzen dabei die Vorteile von AzureML, einer Plattform für die Entwicklung und Bereitstellung von Machine Learning-Operationen, die es uns ermöglicht, schnell Prototypen von Lösungen zu erstellen, Tests durchzuführen und Schlussfolgerungen zu den monatlichen Verkäufen und Einnahmen einzelner Produkte zu ziehen.
Architektur des Systems
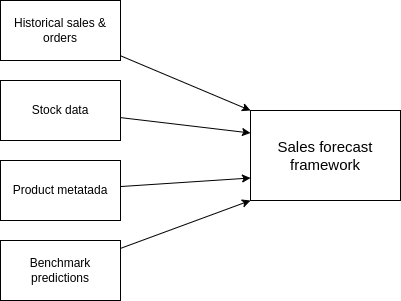
Ein Framework für die Zeitreihenvorhersage ist im Grunde eine ETL-Pipeline mit ein paar zusätzlichen Schritten dazwischen. Neben den historischen Produktverkäufen werden mehrere Datenquellen als Input für die Pipeline verwendet. Produkt-Metadaten sind nützlich, um Produkte anhand ihrer Eigenschaften zu kategorisieren (ähnliche Produkte können ein ähnliches Verkaufsverhalten aufweisen). Außerdem kann ein Unternehmen Produkte auf der Grundlage von Umsatz, Nachfrage oder allgemeiner Bedeutung kategorisieren. Darüber hinaus sind Informationen über den Lagerbestand sehr hilfreich bei der Bestimmung der zukünftigen Umsatzentwicklung, da Lagerverfügbarkeit und Absatzzahlen eng miteinander verbunden sind. Und schließlich können, wenn auf andere Weise zusammengestellte Plandaten vorhanden sind, diese als Benchmark für Vergleiche und die Bewertung der Vorhersagequalität dienen.
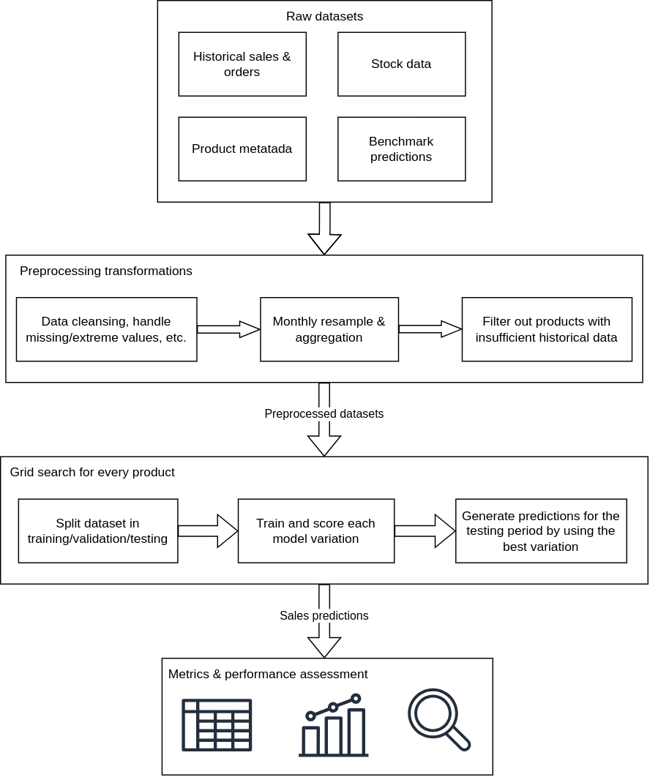
Nach dem Laden der Daten finden mehrere Vorverarbeitungsschritte und Transformationen statt, um sicherzustellen, dass die Inputdaten für das Training der Machine Learning-Modelle vorbereitet sind. In den meisten Fällen liegen die historischen Verkaufsdaten in Form von Auftragsdatensätzen vor, in denen die Produkt-ID, der Zeitstempel, die Anzahl der Einheiten, der Preis pro Einheit und die Rechnungsnummer erfasst sind. Diese Datensätze können fehlende oder extreme Werte enthalten, so dass wir sie entweder ganz verwerfen oder versuchen können, die fehlenden Werte zu interpolieren (z. B. indem wir den Mittelwert der täglichen Datensätze nehmen) und die Extremwerte in einen geeigneteren Bereich zu normalisieren. Die Auftragsdatensätze werden dann auf monatlicher Basis pro Produkt neu berechnet, so dass das Ergebnis zahlreiche Zeitreihen (eine pro Produkt) sind, die die monatlichen Gesamtverkäufe, die verkauften Einheiten und den Durchschnittspreis pro Einheit darstellen. Die Lagerbestände werden ebenfalls monatlich neu erhoben. Danach müssen wir sicherstellen, dass für jedes Produkt eine ausreichende Menge historischer Datensätze verfügbar ist. Einige der Trainingsalgorithmen benötigen mindestens zwei volle Jahre an Trainingsdaten, um Muster, wie z. B. einen jährlichen Trend, eindeutig erkennen zu lassen. Darüber hinaus sollte eine beträchtliche Menge an Daten zu Validierungszwecken ausgelassen werden. In diesem Schritt werden also Produkte herausgefiltert, für die nicht genügend Daten zur Verfügung stehen.

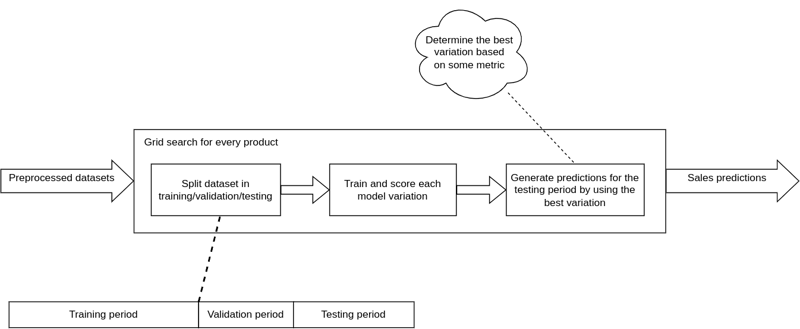
Nach der Vorverarbeitung der Datensätze geht es nun an die Modellauswahl, bei der mehrere statistische und Machine Learning-Modelle getestet werden, um festzustellen, welches Modell für jedes Produkt am besten geeignet ist. Dieses Verfahren wird als Rastersuche bezeichnet und beinhaltet das kontinuierliche Training und die Validierung verschiedener Modelle über einen Satz von Algorithmus-Hyperparametern. Im Grunde handelt es sich um eine erschöpfende Hyperparameter-Optimierungsmethode, die garantiert, dass das beste Prognosemodell gefunden und fein abgestimmt wird. Das Kriterium für die Bewertung der verschiedenen Modellvarianten ist in der Regel eine Fehlermetrik wie MSE oder MAPE; ein kleiner Wert zeigt an, dass die Vorhersagen den tatsächlichen Verkäufen im Validierungszeitraum recht nahe kommen. Mit einer Reihe von optimierten Modellen können wir Vorhersagen für jedes Produkt im Testzeitraum erstellen. Das folgende Diagramm zeigt die Methodik der Rastersuche.
So kurbeln Sie Ihr Business durch
Künstliche Intelligenz und Machine Learning an

Die Vorhersagen können nun verwendet werden, um die Leistung des Systems unvoreingenommener zu bewerten, da die Metriken auf der Grundlage von zuvor nicht gesehenen Datenpunkten berechnet werden. An dieser Stelle können wir Diagramme erstellen, zusätzliche Metriken berechnen, Benchmarks vergleichen und Berichte über einzelne Produkte und Produktkategorien erstellen. Die vollständige Architektur ist in dem nachstehenden Diagramm dargestellt.
Einsatz in AzureML
Trotz seiner scheinbar komplexen Architektur ist das Framework recht flexibel und kann auf praktisch jeder Plattform eingesetzt werden. Aus diesem Grund haben wir AzureML für die Entwicklung und Bereitstellung gewählt. AzureML ist ein Cloud-basierter Dienst von Microsoft zum Erstellen, Trainieren und Bereitstellen von Modellen für maschinelles Lernen. Er bietet eine breite Palette von Tools zur einfachen Verwaltung großer Datensätze, zur Verwendung verschiedener Machine/Deep-Learning-Frameworks und zur Automatisierung von Arbeitsabläufen.
Azure Blob Storage erleichtert die effiziente Speicherung und den Abruf der rohen Inputdaten sowie die Speicherung und Versionierung verschiedener Ergebnisse und Metriken der durchgeführten Rastersuchen. Vorhersagezeitreihen, Diagramme und Berichte werden ebenfalls in Blob Storage gespeichert. AzureML ermöglicht die Erstellung von Prototypen und Experimenten durch die Verwendung von Jupyter Notebooks, so dass die Entwicklungserfahrung viel interaktiver und kollaborativer wird. Die eingesetzten Vorhersagemodelle (die für Echtzeitprognosen verwendet werden) können versioniert werden und sind über REST-Endpunkte zugänglich.
Die nachstehende Grafik zeigt die Leistung verschiedener Vorhersagemodelle im Zusammenhang mit der Rastersuche.
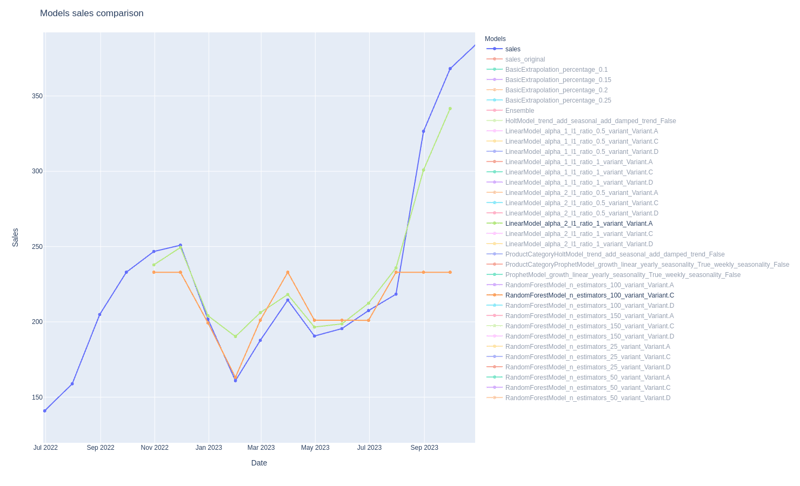
Die blaue Linie stellt die tatsächlichen Verkäufe eines bestimmten Produkts dar, also die Werte, die wir vorhersagen wollen. Die hellgrüne Linie stellt eine Variante eines linearen Regressionsmodells dar, das sich als das beste Modell für dieses Produkt erweist. Im Gegensatz dazu ist eine Variante eines Random Forest-Modells (einem beliebten Ensemble-ML-Algorithmus) in Orange dargestellt, das nicht so gut abzuschneiden scheint. Beide Modelle scheinen den Verkaufstrend zu erfassen, aber die lineare Regression glättet den steilen Aufwärtstrend gegen Ende des Vorhersagezeitraums besser. Auf der rechten Seite sehen Sie eine Liste aller verfügbaren Modelle, die jedoch aus der Darstellung herausgenommen wurden, um die Übersichtlichkeit zu verbessern.
In der nachstehenden Tabelle werden einige der Leistungskennzahlen zwischen den beiden oben genannten Prognosemodellen verglichen.
|
MAE |
MAPE |
SMAPE |
R² |
|
|
Lineare Regression |
12.305 |
0.0543 |
0.0528 |
0.9243 |
|
Random Forest |
27.844 |
0.0954 |
0.1059 |
0.2898 |
Die lineare Regression übertrifft Random Forest eindeutig in jeder Metrik. Im Hinblick auf den mittleren absoluten Fehler (MAE) sagt die lineare Regression im Durchschnitt ± 12,3 Einheiten vom Ziel ab, während Random Forest ± 27,8 Einheiten vom Ziel abweicht. Ein intuitiverer Indikator ist der mittlere prozentuale Fehler (MAPE), der bei der linearen Regression ebenfalls niedriger ist; die Interpretation ist, dass das Modell im Durchschnitt ± 5,28 % vom Zielwert abweicht. R², die Anpassungsgüte, liegt näher bei 1, wenn das Modell gut abschneidet. In diesem Fall hat die lineare Regression einen R²-Wert, der ziemlich nahe bei 1 liegt, im Gegensatz zum Random Forest, der in dieser Hinsicht unzureichend ist.
Die Vertriebsplanung in AzureML - Unser Fazit
Die Durchführung präziser Absatzprognosen gilt nicht ohne Grund als Herausforderung. Eine schlechte Datenqualität führt in der Regel zu falschen Annahmen und Prognosen, die nicht der Realität entsprechen. Mit einer Mischung aus bewährten Software-Engineering-Verfahren und der Flexibilität von Azure haben wir einen Framework für die Absatzprognose entwickelt, das die Fähigkeiten modernster Algorithmen des maschinellen Lernens für Zeitreihenvorhersagen nutzt. Der Rastersuchmechanismus garantiert die Erstellung spezialisierter Prognosemodelle, die auf die Bedürfnisse des Produkts zugeschnitten sind. Die Leistung des Systems wird anhand von Metriken bewertet, die messen, wie nahe die Prognosen an den tatsächlichen Produktverkäufen liegen. Darüber hinaus werden interaktive Diagramme und Berichte erstellt, um eine visuelle Darstellung der Gesamtleistung zu liefern. Durch die Nutzung von Azure Machine Learning für Entwicklung und Bereitstellung können Modelle neu trainiert und zusammen mit wichtigen Metadaten und begleitenden Metriken und Ergebnissen gespeichert werden.
Haben Sie Fragen zu AzureML oder anderen Themen? Wir freuen wir uns darauf, mehr über Ihre Herausforderungen zu erfahren und helfen Ihnen gerne dabei, optimale Lösungen zu finden und diese umzusetzen.


