/Logo%202023%20final%20dunkelgrau.png?width=221&height=97&name=Logo%202023%20final%20dunkelgrau.png)























In Geschäftsdaten ist es keine Seltenheit, dass Spalten mehrere Werte in einem einzigen Feld enthalten – häufig durch Kommas getrennt.
Beispielsweise kann ein Konto mehrere Klassifizierungen aufweisen (A1,A2,A3) oder ein Auftrag mehrere Produktcodes enthalten (P01,P02,P03).
Diese Vorgehensweise vereinfacht zwar den Aufbau des Quellsystems, erschwert jedoch die Analyse. Die meisten Reporting- oder Modellierungstools bevorzugen normalisierte Daten – also Strukturen, bei denen jeder Wert in einer eigenen Zeile steht.
In SAP Datasphere (und SAP HANA) lässt sich diese Transformation effizient und ohne Schleifen umsetzen – mithilfe integrierter SQLScript-Funktionen wie SERIES_GENERATE_INTEGER und OCCURRENCES_REGEXPR.
Im Folgenden wird ein praxisnahes Beispiel vorgestellt, das Schritt für Schritt zeigt, wie kommaseparierte Listen dynamisch in einzelne Zeilen zerlegt werden können.
Das Geschäftsszenario
In vielen Unternehmen stammen Daten aus unterschiedlichen Systemen, in denen Kontonummern oder Klassifizierungen in einem String zusammengefasst sind. Das führt zu Einschränkungen, wenn Datenmodelle für Analysezwecke aufbereitet werden sollen.
Ein Beispiel: Das Account-Feld enthält Werte in folgender Form: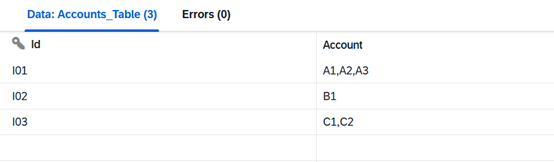
Diese Struktur bereitet Schwierigkeiten, wenn:
- eine Verknüpfung mit einer Stammdatentabelle auf Einzelwertebene erforderlich ist,
- nach spezifischen Konten gefiltert oder aggregiert werden soll oder
- ein Datenmodell für SAP Analytics Cloud benötigt wird, das atomare Werte erwartet.
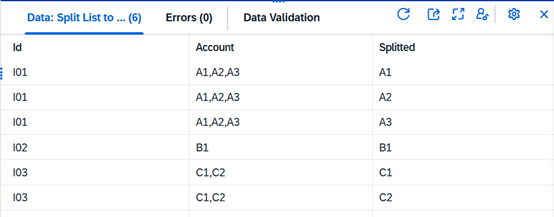
Das Ziel besteht darin, jede kommaseparierte Liste in einzelne Zeilen umzuwandeln, z. B.:
Sehen Sie sich die Aufzeichnung unseres Webinars an:
"SAP Datasphere and the Databricks Lakehouse Approach"

Die Herausforderung – eine set-basierte Lösung
Prozedurale Schleifen wirken auf den ersten Blick wie eine einfache Lösung. In SQL-basierten Engines wie SAP Datasphere sind sie jedoch ineffizient und verstoßen gegen das Prinzip der set-basierten Verarbeitung.
Die nachfolgende Lösung basiert vollständig auf set-basierten SQLScript-Funktionen. Damit lässt sich die Anzahl der Elemente in jeder Liste ermitteln, die erforderliche Anzahl an Zeilen dynamisch generieren und jedes Element präzise extrahieren – ganz ohne Loops.

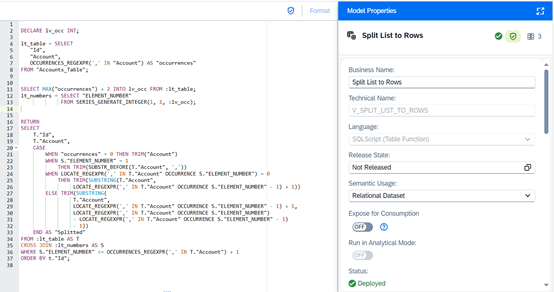
Das SQL-Skript erklärt
Lassen Sie uns den Fall Schritt für Schritt durchgehen.
Schritt 1: Maximale Anzahl an Kommas ermitteln
Zunächst wird ermittelt, wie viele Elemente jede Liste enthält. Mit OCCURRENCES_REGEXPR lässt sich die Anzahl der Kommas – und damit die Anzahl der zu erzeugenden Zeilen – einfach bestimmen:
lt_table = SELECT
"Id",
"Account",
OCCURRENCES_REGEXPR(',' IN "Account") AS "occurrences"
FROM "Accounts_Table";
Eine Zeile mit A1,A2,A3 ergibt beispielsweise den Wert 2 (zwei Kommas).
Diese Information dient anschließend als Grundlage für die Zeilenerzeugung.
Schritt 2: Dynamische Zahlenreihe erzeugen
Anstatt feste Werte zu hinterlegen, kann mit SERIES_GENERATE_INTEGER eine flexible Zahlenreihe erzeugt werden. Dadurch bleibt das Script dynamisch und unabhängig von der Listenlänge.
DECLARE lv_occ INT;
SELECT MAX("occurrences") + 2 INTO lv_occ FROM :lt_table;
lt_numbers = SELECT "ELEMENT_NUMBER"
FROM SERIES_GENERATE_INTEGER(1, 1, :lv_occ);
Die Funktion erstellt eine virtuelle Tabelle mit den Werten 1, 2, 3 … n, wobei n der maximalen Kommaanzahl + 2 entspricht.
Die Zugabe von +2 stellt sicher, dass auch alle tatsächlichen Elemente (nicht nur die Trennzeichen) abgedeckt werden.
Schritt 3: CROSS JOIN und dynamisches Splitten
Hier erfolgt die eigentliche Transformation:
Mithilfe eines CROSS JOIN und Stringfunktionen wie SUBSTR_BEFORE und LOCATE_REGEXPR wird jeder Wert in eine eigene Zeile überführt:
SELECT
T."Id",
T."Account",
CASE
WHEN "occurrences" = 0 THEN TRIM("Account")
WHEN S."ELEMENT_NUMBER" = 1
THEN TRIM(SUBSTR_BEFORE(T."Account", ','))
WHEN LOCATE_REGEXPR(',' IN T."Account" OCCURRENCE S."ELEMENT_NUMBER") = 0
THEN TRIM(SUBSTRING(T."Account",
LOCATE_REGEXPR(',' IN T."Account" OCCURRENCE S."ELEMENT_NUMBER" - 1) + 1))
ELSE TRIM(SUBSTRING(
T."Account",
LOCATE_REGEXPR(',' IN T."Account" OCCURRENCE S."ELEMENT_NUMBER" - 1) + 1,
LOCATE_REGEXPR(',' IN T."Account" OCCURRENCE S."ELEMENT_NUMBER")
- LOCATE_REGEXPR(',' IN T."Account" OCCURRENCE S."ELEMENT_NUMBER" - 1)
- 1))
END AS "Splitted"
FROM :lt_table AS T
CROSS JOIN :lt_numbers AS S
WHERE S."ELEMENT_NUMBER" <= OCCURRENCES_REGEXPR(',' IN T."Account") + 1;
In diesem Teil des Codes:
- Kombiniert der
CROSS JOINjeden Datensatz mit der erzeugten Zahlenreihe (1, 2, 3 …), sodass jede mögliche Position innerhalb der Liste abgedeckt ist. - Die Stringfunktionen extrahieren anschließend den entsprechenden Teilstring zwischen den Kommas – vollständig ohne Schleifen.
Das CASE WHEN-Prinzip verstehen
Nachdem wir gesehen haben, wie das Skript unsere Daten mit einer Zahlenreihe verbindet, schauen wir uns nun den CASE WHEN-Block genauer an.
Jede Bedingung innerhalb des CASE-Blocks erfüllt einen bestimmten Zweck – von der Behandlung von Datensätzen ohne Kommas bis hin zum korrekten Extrahieren des ersten, mittleren und letzten Elements.
Hier findet die eigentliche Textaufteilung statt.
Lassen Sie uns Schritt für Schritt vereinfachen, was in den einzelnen CASE-Bedingungen passiert.
Hier ist der entsprechende Ausschnitt aus dem CASE WHEN -Code noch einmal:
CASE
WHEN "occurrences" = 0 THEN TRIM("Account")
WHEN S."ELEMENT_NUMBER" = 1
THEN TRIM(SUBSTR_BEFORE(T."Account", ','))
WHEN LOCATE_REGEXPR(',' IN T."Account" OCCURRENCE S."ELEMENT_NUMBER") = 0
THEN TRIM(SUBSTRING(
T."Account",
LOCATE_REGEXPR(',' IN T."Account" OCCURRENCE S."ELEMENT_NUMBER" - 1) + 1
))
ELSE TRIM(SUBSTRING(
T."Account",
LOCATE_REGEXPR(',' IN T."Account" OCCURRENCE S."ELEMENT_NUMBER" - 1) + 1,
LOCATE_REGEXPR(',' IN T."Account" OCCURRENCE S."ELEMENT_NUMBER")
- LOCATE_REGEXPR(',' IN T."Account" OCCURRENCE S."ELEMENT_NUMBER" - 1)
- 1
))
END AS "Splitted"
Auf den ersten Blick wirkt das kompliziert, aber tatsächlich werden hier nur vier verschiedene Situationen behandelt.
Gehen wir sie der Reihe nach in einfacher Sprache durch.
1. Wenn es überhaupt keine Kommas gibt
Keine Kommas? Dann einfach den Originalwert behalten.
WHEN "occurrences" = 0 THEN TRIM("Account")
Wenn die Spalte keine Kommas enthält, gibt es nichts zu trennen.
Der Code gibt also schlicht den ursprünglichen Wert zurück.
Die Funktion TRIM sorgt lediglich dafür, dass führende oder nachgestellte Leerzeichen entfernt werden.
Beispiel:
B1 → B1
Ein einfacher „Mach-nichts“-Fall, der Einzelwerte unverändert lässt.
2. Das erste Element in der Liste
Erstes Element? Alles vor dem ersten Komma nehmen.
WHEN S."ELEMENT_NUMBER" = 1 THEN TRIM(SUBSTR_BEFORE(T."Account", ','))
Wenn ELEMENT_NUMBER den Wert 1 hat, handelt es sich um das erste Element in der Liste.
Die Funktion SUBSTR_BEFORE holt einfach alles, was vor dem ersten Komma steht.
Beispiel:
A1,A2,A3 → A1
Das ist meist der einfachste Fall, da keine Positionsberechnung nötig ist.
3. Das letzte Element in der Liste
Letztes Element? Alles nach dem letzten Komma nehmen.
WHEN LOCATE_REGEXPR(',' IN T."Account" OCCURRENCE S."ELEMENT_NUMBER") = 0 THEN TRIM(SUBSTRING( T."Account", LOCATE_REGEXPR(',' IN T."Account" OCCURRENCE S."ELEMENT_NUMBER" - 1) + 1 ))
Wenn keine weiteren Kommas mehr gefunden werden, bedeutet das: Wir sind am Ende der Zeichenkette.
Der Code sucht die Position des letzten Kommas, addiert eins und nimmt alles, was danach kommt.
Der Teil OCCURRENCE in der Funktion LOCATE_REGEXPR erwartet eine Ganzzahl, damit die Funktion weiß, bei welchem Vorkommen des Kommas sie suchen soll (z. B. beim 1., 2. oder 3. Mal).
Durch die Verwendung der Spalte "ELEMENT_NUMBER" sucht der Code dynamisch nach den jeweiligen Komma-Vorkommen pro Zeile.
Beispiel:
A1,A2,A3 → A3
Dieser Fall behandelt also das Ende jeder Liste.
4. Alles dazwischen
Mittlere Elemente? Was zwischen den Kommas liegt extrahieren.
ELSE TRIM(SUBSTRING( T."Account", LOCATE_REGEXPR(',' IN T."Account" OCCURRENCE S."ELEMENT_NUMBER" - 1) + 1, LOCATE_REGEXPR(',' IN T."Account" OCCURRENCE S."ELEMENT_NUMBER") - LOCATE_REGEXPR(',' IN T."Account" OCCURRENCE S."ELEMENT_NUMBER" - 1) - 1 ))
Dieser Teil deckt alle „mittleren“ Werte ab – also jene, die weder das erste noch das letzte Element sind.
Die Idee: Finde das Komma vorher und das Komma nachher, und nimm alles dazwischen.
Beispiel:
A1,A2,A3,A4 → A2, A3
Die LOCATE_REGEXPR -Aufrufe bestimmen die Positionen dieser Kommas, sodass SUBSTRING genau den richtigen Abschnitt herauszieht.
Die Funktion SUBSTRING erwartet als Parameter:
- den Text, in dem gesucht wird ("Account"),
- die Startposition (1, 2, 3 …),
- und die Anzahl der zu entnehmenden Zeichen.
Hier ist die Startposition das erste gefundene Komma + 1, damit das Komma selbst nicht in den Text aufgenommen wird.
Die Länge wird für jede Zeile dynamisch berechnet, indem die Positionen des vorherigen und des nächsten Kommas voneinander abgezogen werden – daher der Subtraktions-Teil der LOCATE_REGEXPR -Ausdrücke.
Jede dieser Regeln sorgt dafür, dass deine Daten konsistent und sauber bleiben.
Alles zusammenfügen in SAP Datasphere
Wenn Sie das komplette SQLScript-View ausführen, sehen Sie, wie jede durch Kommas getrennte Liste in einzelne Zeilen aufgeteilt wird – bereit für Joins, Aggregationen und Analysen in SAP Datasphere oder SAP Analytics Cloud.
Kommagetrennte Listen in Zeilen mit SQLScript in SAP Datasphere aufteilen: Unser Fazit
Kommagetrennte Felder mögen in Quellsystemen auf den ersten Blick wie eine harmlose Abkürzung wirken – doch sie werden schnell zu einem Hindernis für verlässliche Analysen und skalierbare Datenmodelle.
Mit nur wenigen leistungsstarken SQL-Funktionen können Sie komplexe Zeichenketten elegant in ein sauberes, normalisiertes Format transformieren – ganz ohne Schleifen oder aufwendige Skripte.
Der hier vorgestellte Ansatz läuft besonders effizient in SAP Datasphere und eignet sich daher ideal für große Datenmengen und nahezu Echtzeit-Transformationen.
Wenn Ihre Datenlandschaft noch Legacy-Strukturen enthält, die Analysen verlangsamen, kann unser Team Sie unterstützen.
Wir sind spezialisiert auf die Entwicklung performanter, cloudfähiger Datenmodelle, die Optimierung von SQLScript-Transformationen sowie die nahtlose Integration von SAP Datasphere in Ihre bestehende Architektur.
Lassen Sie uns darüber sprechen, wie Sie Ihre Data Layer modernisieren und eine bessere Reporting-Performance erreichen können – vereinbaren Sie gerne ein kurzes Beratungsgespräch oder eine praxisnahe Session mit konkreten Anwendungsfällen.


