/Logo%202023%20final%20dunkelgrau.png?width=221&height=97&name=Logo%202023%20final%20dunkelgrau.png)























Heutzutage ist ein schnelles Prototyping im Machine Learning Bereich wichtig, um sich möglichst viele Ansätze zu evaluieren und die erfolgversprechenden auszuwählen und weiterzuverfolgen. Für die Datenmanipulation und auch die Modellbildung wird gerne die Programmiersprache Python benutzt, da diese neueste Algorithmen und eine einfache Syntax vereint. Für das Anpassen des deskriptiven oder prädiktiven Modells sind allerdings große Mengen an Trainingsdaten notwendig. Hierin zeigt sich ein deutlicher Flaschenhals: Während die Algorithmen vertikal skaliert werden können, ist die Datenübertragung auf den Anwendungsserver ein typischer Faktor für Wartezeiten im Prototyping. Für hoch-performante Analysen wird deshalb gerne auf die SAP HANA gesetzt. Die Datenbereitstellung findet HANA-seitig in Echtzeit statt und zusätzliche Funktionen für In-Database-Machine-Learning werden geboten.
In diesem Artikel zeigen wir Ihnen, welche Möglichkeiten Sie haben über die open-source Programmiersprache Python in Kombination mit der SAP HANA eigene Data Science Anwendungen zu realisieren.
Machine Learning auf SAP HANA
Zunächst erfahren Sie, warum die SAP HANA für den Data Science Bereich eine hervorragende Wahl darstellt. Die SAP HANA (High-performance Analytic Appliance) ist eine Entwicklungs- und Integrationsplattform, welche im Kern aus einem relationalen, spaltenorientierten In-Memory-Datenbank-Managementsystem besteht. Im Hauptspeicher liegen die Daten in Echtzeit bereit, was die beste Voraussetzung für eine schnelle Zugriffszeit bedeutet. Dieser Performancevorteil ist für Machine Learning Anwendungen von Bedeutung.
Neben der reinen Datenspeicherung bringt die HANA viele praktische Funktionen für die Datenanalyse mit. Mit der Application Function Library (AFL) stehen einige Funktionen für erweiterte Analysen bereit. Diese können über SAP HANA SQLScript Prozeduren aufgerufen werden, um analytische Algorithmen direkt in der Datenbank auszuführen.
Hier sind die HANA Predictive Analysis Library (PAL) und die HANA Automated Predictive Library (APL) erwähnenswert. Themen wie Clustering, Regression, Zeitreihenanalyse, Datenvorverarbeitung, allgemeine Statistik und Empfehlungssysteme werden abgedeckt. Hier kann durch In-Database-Machine-Learning die Modellierung ohne Datenübertragung direkt auf der Datenbankhardware ablaufen.
SAP HANA Python Client API
Auf die beschriebenen Bibliotheken PAL und APL kann auch von Python aus zugegriffen werden. Hierfür wird die SAP HANA Python Client API verwendet, welche die Modellierung mittels HANA-DataFrames von Python aus steuert. Die Anwendung der analytischen Algorithmen findet vollständig auf der HANA statt und erzeugt dort Ergebnistabellen. Dies stellt die erste Möglichkeit dar, mittels Python auf Daten in einer HANA Instanz zuzugreifen. Allerdings schränken die begrenzte Algorithmenauswahl und die starren Ergebnistabellen die Flexibilität der Anwendung ein. Deshalb wird im Allgemeinen ein eigener Anwendungsserver mit Python verwendet.
HANA Daten in Python verarbeiten
Die Programmiersprache Python bietet einige Vorteile für Data Science Anwendungen. State-of-the-art Algorithmen, umfangreiche Datenmanipulation und die verständliche Syntax sind ausschlaggebende Hauptargumente. Entwickler*innen profitieren zusätzlich von den gut dokumentierten Packages und der unkomplizierten Einrichtung einer Entwicklungsumgebung. Für die Datenübertragung von der HANA aus stehen mehrere Packages zur Verfügung.
Wie Sie SAP BW und State of the Art Machine Learning zusammenbringen -
Laden Sie sich Ihr Whitepaper herunter!

HANA Database Client (hdbcli)
Für die technische Umsetzung der Datenübertragung aus der SAP HANA zum Python-Anwendungsserver steht zunächst einmal der HANA Database Client (hdbcli) Treiber als eine simple Methode bereit. Hier können Daten über einen Cursor abgerufen werden und SQL-Statements über die Verbindung ausgeführt werden. Sollen die Daten weiterverarbeitet werden, müssen diese erst in ein passendes Format
(z. B. Pandas DataFrames oder Numpy Array) gebracht werden. Im Weiteren ist auch der Upload mit Aufwand verbunden, da einzelne INSERT-INTO-Statements generiert und ausgeführt werden müssen.
from hdbcli import dbapi
conn = dbapi.connect(
address="<hostname>",
port="<port>",
user="<username>",
password="<password>"
)
sql = 'SELECT * FROM TABLE1'
cursor = conn.cursor()
cursor.execute(sql)
for row in cursor.fetchall():
print(row)
Sqlalchemy
Mit der zusätzlichen Verwendung der Bibliothek sqlalchemy, lassen sich schneller große Datenmengen in eine erzeugte Tabelle hochladen und gezogene Daten lassen sich direkt in einen Pandas-DataFrame umwandeln. Dies spart Aufwand, hat aber noch einige Nachteile:
- Eine manuelle Parallelisierung auf mehrere Threads muss selbst angelegt werden - inklusive das Zusammenfügen der temporären Uploadtabellen auf der SAP HANA beim Upload
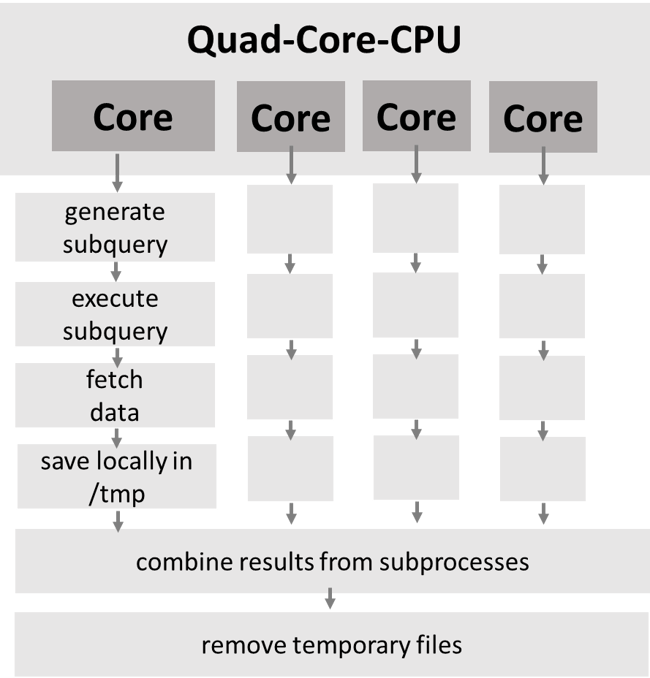
Parallelisierung des Datendownloads
- Das Schema der Zieltabelle muss vorhanden sein, um die Daten hochladen zu können.
Die letzte Möglichkeit für einen Datenzugriff auf die HANA über Python wurde aufgrund der besonderen Anforderungen im Data Science Bereich von uns bei NextLytics entwickelt.
Phython SAP HANA Connector by NextLytics
Um das Zusammenspiel der SAP HANA mit der Programmiersprache Python zu optimieren, wurde ein eigener Connector entwickelt, der besonderes Augenmerk auf die einfache Verwendung aus Sicht von Python Entwickler*innen legt. Dabei waren uns folgende Punkte wichtig:
- Performance durch Parallelisierung
- Sichere Authentifizierung
- Volle Kompatibilität mit Pandas DataFrames
- Einfache Nutzbarkeit für einen Data Science orientierten Python Entwickler*innen
Der NextLytics HANA Connector kann in Python einfach als ein Package geladen werden und stellt intuitive Funktionen zur Kommunikation mit einer HANA Instanz bereit. Alle Informationen zum Connector finden Sie auf unserer Webseite.
SAP HANA Connector - Unser Fazit
Um Machine Learning Anwendungsfälle mit der Kombination aus Python und der SAP HANA umzusetzen, bieten sich Ihnen viele Möglichkeiten. Für einfache Anwendungsfälle sind die Application Functions Libraries APL und PAL für direkte Berechnungen auf der HANA die schnellste Option. Diese sind auch über den Python Client ausführbar.
Die Datenanalyse auf einen Anwendungsserver geht mit einem aufwendigen Datenübertrag einher. Hierfür können Sie neben dem Hana Database Client (hdbcli) auch auf SqlAlchemy setzen. Für diesen Use Case bietet Ihnen der NextLytics Python SAP HANA Connector einen signifikanten Geschwindigkeitsvorteil durch Parallelisierung und erlaubt es Entwickler*innen, schnell und einfach auf die HANA Datenbank zuzugreifen.
Haben Sie noch Fragen oder Interesse an dem Connector? NextLytics steht Ihnen stets als erfahrener Projektpartner zur Seite. Wir helfen Ihnen, Ihre Datenprobleme von der Datenintegration bis zum Einsatz von Machine Learning Modellen effektiv zu lösen. Sprechen Sie uns gerne an.


